
编者按:如果问华语乐坛近期产量最高的歌手是谁,“AI 孙燕姿”一定有姓名。歌迷们先用歌手的音色训练 AI,再通过模型将其他歌曲转换成以歌手音色“翻唱”的歌曲。语音合成技术是“AI 孙燕姿”的背后支持。广义的语音合成包含文本到语音合成(Text to Speech,TTS)、声音转换等。在 TTS 领域,微软亚洲研究院机器学习组和微软 Azure 语音团队早已深耕多年,并在近期推出了语音合成模型 NaturalSpeech 2,只需几秒提示语音即可定制语音和歌声,省去了传统 TTS 前期训练过程,实现了零样本语音合成的跨越式发展。
文本到语音合成(Text to Speech,TTS)作为生成式人工智能(Generative AI 或 AIGC)的重要课题,在近年来取得了飞速发展。多年来,微软亚洲研究院机器学习组和微软 Azure 语音团队持续关注语音合成领域的研究与相关产品的研发。为了合成既自然又高质量的人类语音,NaturalSpeech 研究项目(https://aka.ms/speechresearch)应运而生。
NaturalSpeech 的研究分为以下几个阶段:
1)第一阶段,在单个说话人上取得媲美人类的语音质量。为此,研究团队在2022年推出了 NaturalSpeech 1,在 LJSpeech 语音合成数据集上达到了人类录音水平的音质。
2)第二阶段,高效地实现多样化的语音合成,包含不同的说话人、韵律、风格等。为此,该联合研究团队在2023年推出了 NaturalSpeech 2,利用扩散模型(diffusion model)实现了 zero-shot 的语音合成,只需要几秒钟的示例语音(speech prompt)模型就能合成任何说话人、韵律、风格的语音,实现了零样本语音合成的重要突破,为语音合成技术的未来发展带来了无限可能。
3)当前,研究团队正在开展第三阶段的研究,为达到高自然度(高质量且多样化)的语音合成这一目标,乘势而上,开创新局面。
三大创新设计,让NaturalSpeech 2脱颖而出
于近期发布的新一代语音合成大模型 NaturalSpeech 2,经历了上万小时、多说话人的语音数据集训练,并采用了 zero-shot(预测时只提供几秒钟的目标示例语音)的方式合成新的说话人、韵律、风格的语音,以实现多样化的语音合成。

论文链接:
https://arxiv.org/abs/2304.09116
项目演示:
https://speechresearch.github.io/naturalspeech2/
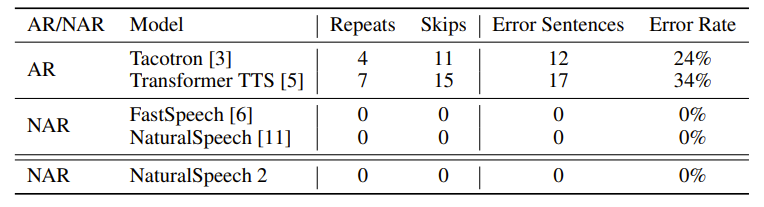
要想达到良好的 zero-shot 训练效果,面临极大挑战。先前的方法是将语音量化成离散 token,并用自回归语言模型进行建模(例如 AudioLM)。但这种方法存在很大的局限性:自回归模型面临严重的错误传播(error-propagation)问题,导致生成语音质量低下、鲁棒性差,韵律失调以及重复、漏词等问题。同时还容易陷入离散 token 量化和自回归建模的两难困境(如表1所示),即要么离散 token 难以以较高质量还原语音,要么离散 token 难以预测。

表1:先前语音合成系统的两难处境
NaturalSpeech 2 提出了一系列创新设计,如图1所示,完美地有效规避了先前的局限,实现了零样本语音合成的重要突破。考虑到语音波形的复杂性和高维度,微软亚洲研究院机器学习组与 Yoshua Bengio 共同提出的 Regeneration Learning 范式,为这个问题提供了创新的参考答案。
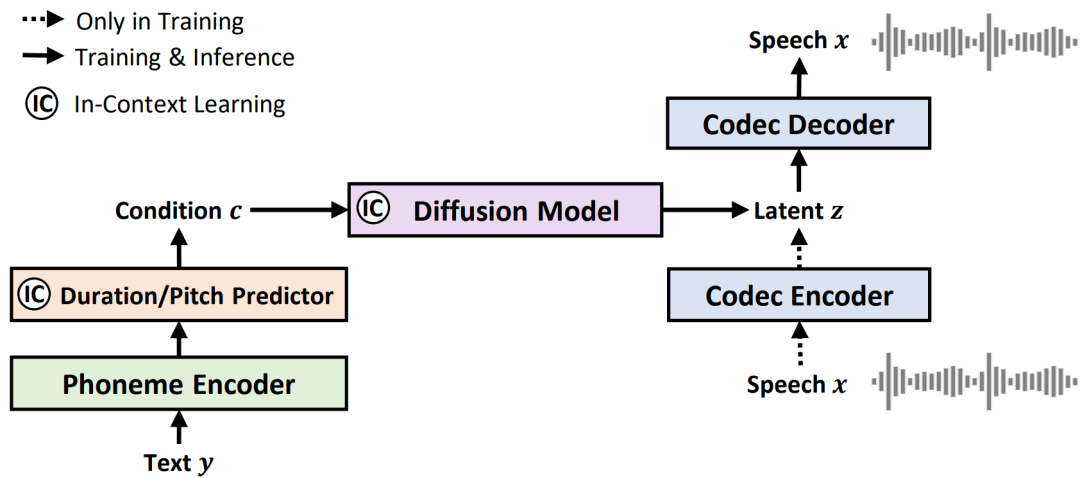
图1:NaturalSpeech 2 系统概览
NaturalSpeech 2 首先利用神经语音编解码器(Neural Audio Codec,如图2所示)的编码器(encoder),将语音波形转换为连续向量并用解码器(decoder)重建语音波形,再运用潜在扩散模型(Latent Diffusion Model)以非自回归的方式从文本预测连续向量。在推理时,利用潜在扩散模型和神经语音解码器从文本生成语音的波形。
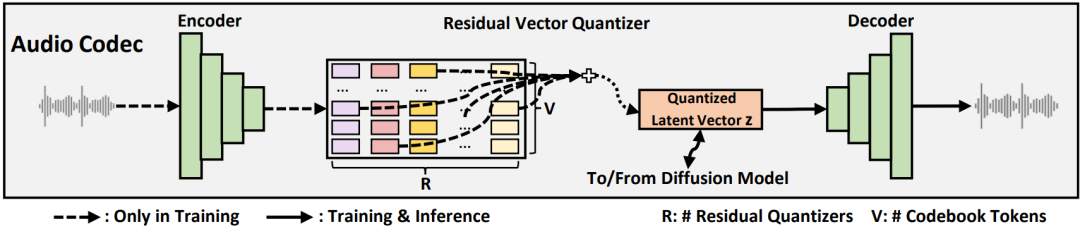
图2:NaturalSpeech 2 中的 Neural Audio Codec 概览
相比先前的语音合成系统,NaturalSpeech 2 有以下几大优势,如表2所示:

表2:NaturalSpeech 2 相比先前语音合成系统的优势
1. 使用连续向量替代离散 token。离散 token 会导致序列长度过长(例如,使用8个残差向量量化器,序列长度会增加8倍),增加了预测的难度。而连续向量可以缩短序列长度,同时增加细粒度重建语音所需要的细节信息。
2. 采用扩散模型替代自回归语言模型。通过非自回归的生成方式,能避免自回归模型中的错误累积所导致的韵律不稳定、重复吐次漏词等问题。
3. 引入语音提示机制,激发上下文学习能力。研究员们创新设计的语音提示机制(如图3所示),让扩散模型和时长/音高预测模块能够更高效地学习语音上下文,从而提升了零样本的预测能力。
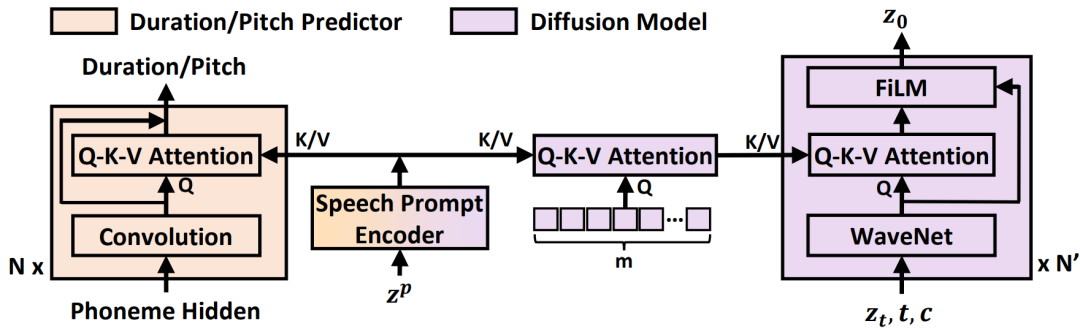
图3:NaturalSpeech 2 中的语音提示机制
得益于以上设计,NaturalSpeech 2 生成的语音非常稳定、鲁棒,无需要复杂的两阶段模型来预测中间表征序列。同时,非自回归的方式和音高时长预测机制也赋予了 NaturalSpeech 2 扩展到语音之外的风格(例如歌声)的能力。
微软亚洲研究院高级研究员谭旭表示,语音合成是人工智能内容生成的一个非常重要的领域,该研究团队一直致力于构建高自然度的语音合成系统。NaturalSpeech 2 是继去年推出的 NaturalSpeech 后跨越的又一里程碑,利用大数据、大模型和零样本合成技术,极大地丰富了语音合成的音色、韵律、风格的多样性,使语音合成更自然更像人类。
NaturalSpeech 2的语音合成性能大检测
研究团队将 NaturalSpeech 2 的模型大小扩展到了400M,并基于4.4万小时的语音数据进行了训练。值得一提的是,即使 NaturalSpeech 2 与被模仿人“素昧平生”,只需几秒的语音提示, NaturalSpeech 2 输出的结果也可以在韵律/音色相似度、鲁棒性和音质方面都更优于先前的 TTS 系统。这一成果使得 NaturalSpeech 2 的性能达到了新高度,并有望为未来的 TTS 研究提供基础性参考。
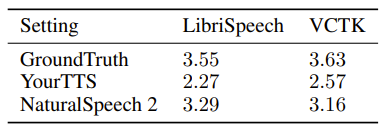
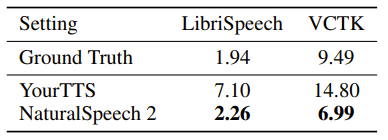
首先,在音质方面,NaturalSpeech 2 在 zero-shot 条件合成的语音显著优于先前的 TTS 系统,如表3和表4所示。
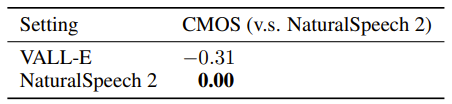
同时,在相似度方面,NaturalSpeech 2 也能更好地生成和语音提示相似的语音,如表5和表6所示(评估指标详细介绍参见论文)。
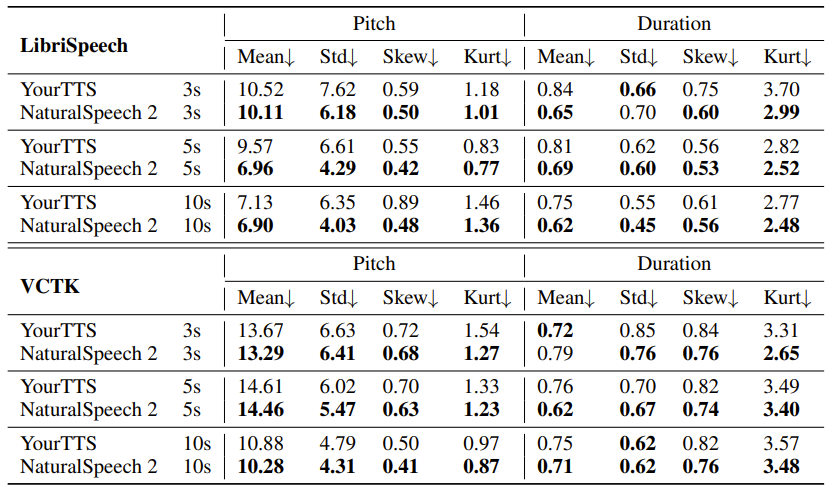
在稳定度方面,相较于既有的 TTS 模型,NaturalSpeech 2 的表现也更为优异,如表7和表8所示。
研究员们还从互联网上收集了歌声数据,并将其与语音数据混合起来,共同训练模型。令人惊喜的是,无论是语音还是歌声提示,NaturalSpeech 2 都可以进行零样本歌声合成。欢迎点击链接:https://speechresearch.github.io/naturalspeech2/,一起听一听更多 AI 合成的语音和歌声吧!
随着合成语音质量的不断提升,确保 TTS 能被人们信赖是一个需要攻坚的问题。微软主动采取了一系列措施来预判和降低包括 TTS 在内的人工智能技术所带来的风险。微软致力于依照以人为本的伦理原则推进人工智能的发展,早在2018年就发布了“公平、包容、可靠与安全、透明、隐私与保障、负责”6个负责任的人工智能原则(Responsible AI Principles),随后又发布负责任的人工智能标准(Responsible AI Standards)将各项原则实施落地,并设置了治理架构确保各团队把各项原则和标准落实到日常工作中。
未来,该研究团队将持续推动符合负责任的人工智能原则的语音合成大模型的研发,在更加多样化的场景中生成质量更高且更自然的语音,让语音合成技术可以赋能更多个人和组织。
更多研究成果请关注该团队研究主页 https://speechresearch.github.io/
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。