
这个系列文章我们来介绍一位海外工程师如何探索 WebRTC 音视频技术,对于想要开始学习音视频技术的朋友,这些文章是份不错的入门资料,本篇介绍测量 WebRTC 的 NetEQ 抖动缓冲如何提供流畅音频。
来源:webrtcHacks
编译:关键帧Keyframe
音频抖动缓冲是理解 VoIP 的入门知识。libWebRTC 的音频抖动缓冲实现 —— 即 Chromium 中的 NetEQ,绝非基础简单。这对用户来说是好事,因为现实网络环境常充满挑战。然而,这也意味着 NetEQ 的晦涩代码复杂难懂。幸运的是,我们找到了一位志愿者来攻克这一任务 。
欢迎 Fengdeng Lyu 来到 webrtcHacks,深入探讨 NetEQ—— 自 WebRTC 诞生以来,这个音频抖动缓冲实现便不断演变,以确保音频播放流畅。Fengdeng 是 Meta 的一名软件工程师,负责 RTC 网络弹性的研发工作。本文聚焦音频,但 Fengdeng 也参与了视频前向纠错(FEC),该技术最近在 Scale@ 会议 上亮相。
在本文中,Fengdeng 将剖析 NetEQ 如何处理数据包抖动、丢失和隐藏,以在现实网络条件下维持音频质量。前半部分回顾音频抖动缓冲的基础知识和不那么基础的内容。后半部分则是对 libWebRTC NetEQ 实现的逐函数指南,并深入解析其众多重叠算法。
1、WebRTC 中音频抖动缓冲的高级回顾
1.1、全景概览
- 每当音频数据包从网络传来,NetEq 便会将其存储。
- 每当需要播放音频时,NetEq 必须生成音频。
NetEQ 以上述两种任务,以最低的延迟和最高的音频质量完成工作。
1.2、NetEQ 为何需要复杂性
由于不同产品需求,不同用例有着不同的抖动缓冲实现:
- 在 Netflix 上观看电影(即 HLS)时,抖动缓冲会缓存数分钟的内容,即使连接中断一段时间,也能保证播放不间断。
- 在 TikTok 上观看直播(即 LL-HLS)时,抖动缓冲仅缓存几秒的内容,因为缓冲时间越长,主播与观众互动的延迟就越大。
- 而在 VoIP 通话(即 WebRTC)中,抖动缓冲最多只能缓存几百毫秒的内容,否则会导致灾难性效果,比如双方同时说话时出现混乱。
为 RTC 构建抖动缓冲极具挑战性。与视频流媒体相比,RTC 的底层传输更不可靠,且对延迟要求更严格:
- RTP 通过 UDP 不可靠—— WebRTC 在 UDP 上使用 RTP 协议作为薄层。数据包何时到达、能否到达均无保证 。VoIP 系统舍弃可靠传输协议(如 TCP)而选用 UDP,因其速度更快。这种取舍意味着需要一个能处理丢失、迟到和顺序错乱数据包的缓冲区。
- 连续音频至关重要—— 当接收设备播放音频时,音频波形的连续性是首要考量。任何音频卡顿 / 欠载都会立刻被用户察觉。缓冲区应尽可能减少音频卡顿。
- 小缓冲区至关重要—— 如 YouTube 和 Spotify 等流媒体客户端,即使是直播活动,通常也会缓冲数秒的音频。作为听众,由于没有延迟参考,你不会察觉到这种延迟。然而,实时音频对话要求延迟低于 500 毫秒,以保证流畅互动。一旦超过这个时间,与另一端的自然对话将变得困难。当你开始交谈时,延迟会显而易见。
2、音频编码和分包
2.1、等一下 —— 我们在说 NetEQ 吗?
要了解 NetEQ 的工作原理,熟悉基本音频概念至关重要。
在继续之前,我们将讨论一些重要的音频基础知识。
2.2、数字音频概念
前提条件:查阅这篇 MDN 文章,全面且准确地回顾音频的数字表示和音频编码。它涵盖了广泛的音频应用。
针对 WebRTC,我将围绕音频格式给出一些实用原则:
- 48kHz是音频录制、分包和播放最为普遍的频率。本文将全程以 48kHz 作为默认采样率。
- Opus是 WebRTC 中最为常用的音频编解码器。WebRTC 对 Opus 的高级功能(如 DTX 和带内前向纠错 FEC)有成熟支持,这些功能会影响 NetEQ。
- 以 单声道16 位原始音频表示,未压缩的占用带宽为 48k/s×16 比特 = 768 kbps,若考虑到多路流和更高带宽的视频需求,这无疑是一个巨大的带宽占用。
- Opus 可以不同的比特率对音频进行编码。通常,20kbps-25kbps 的编码比特率能提供相对不错的感知质量。在 RTC 中,根据网络状况,在 10kbps 至 40kbps 之间的任何比特率都有意义。
2.3、分包长度和 ptime
所选的音频编码器(如 Opus)将音频样本编码为比特流。然后比特流被分包成不同的 RTP 数据包并发送到网络。
分包长度或 “ptime”表示一个数据包包含多少音频样本。例如,20 毫秒的 ptime 意味着发送端在一个数据包中累积 20 毫秒的音频比特流,这会增加 20 毫秒的发送端音频延迟。
在 WebRTC 中,ptime 是 SDP 中的一个属性,用于控制分包长度。默认值为 20,代表 20 毫秒的分包间隔。常见取值为 10 毫秒、20 毫秒、40 毫秒、60 毫秒和 120 毫秒。20 毫秒和 60 毫秒在 VoIP 应用中最为常见。
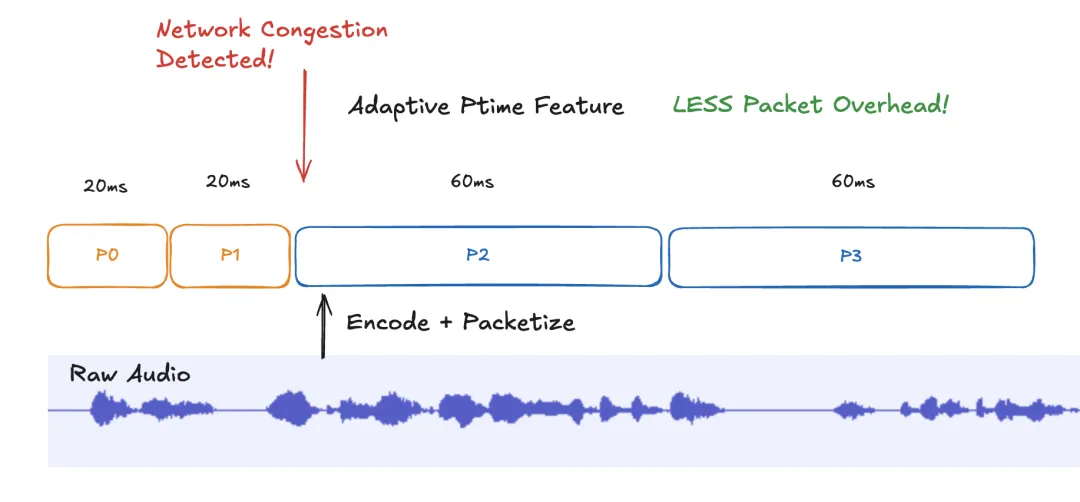

一般来说,随着网络传输改善,ptime 应该缩短(下一部分将深入探讨原因),这就是为什么即使在浏览器中,RTC 配置中也存在自适应 ptime 字段。除了数据包开销,10 毫秒的 ptime 在编码效率上也显著低于 20 毫秒的 ptime。你可以通过这个示例了解浏览器中不同编解码器的实时音频比特率:对等连接:仅音频。
2.4、音频分包长度很重要
不同的分包长度意味着在延迟、带宽和音频质量之间进行权衡。虽然较小的分包长度意味着较小的发送端延迟,但较小的分包长度需要更高的带宽,因为数据包速率更高,编码效率降低。
令人惊讶的是,在许多场景中,数据包头部的大小可能大于实际音频有效载荷。
数据包头部(IP/UDP/RTP)开销占用相当大的带宽。考虑到 IPv4 头部大小为 20 字节,UDP 头部大小为 8 字节,RTP 头部大小为 12 字节,SRTP 身份验证标签长度为 10 + 字节,每个数据包携带 50 字节的头部开销。
此外,RTP 头部扩展带来了相当大的额外开销,但对于 WebRTC 的高级功能(如传输宽 congestion control(TWCC)和绝对捕获时间)至关重要。实际上,RTP 头部扩展功能至少为每个数据包带来 20 字节的额外开销,轻松达到 40 字节。
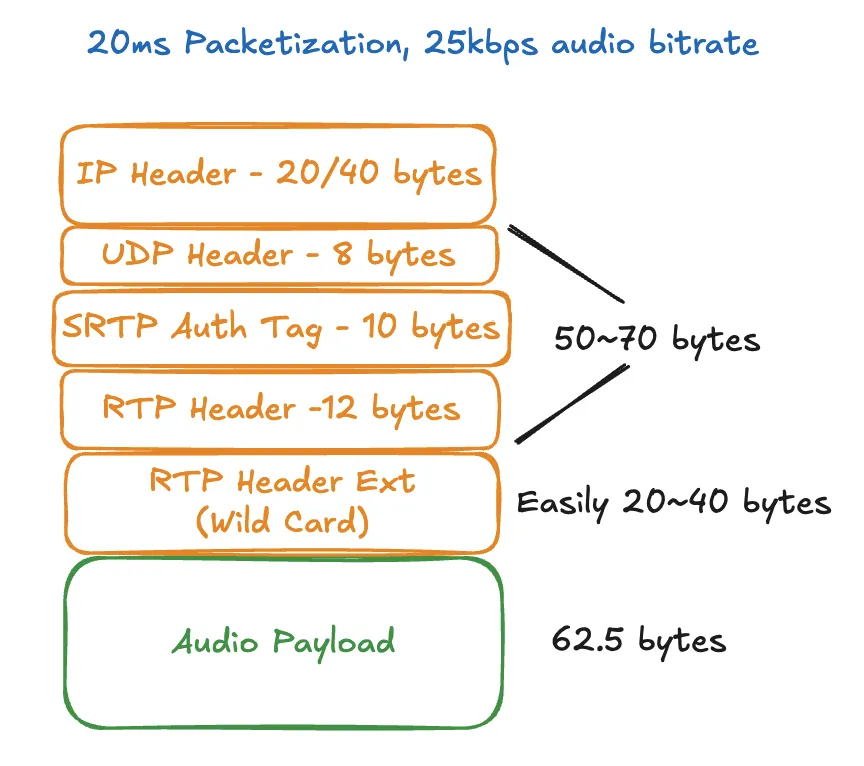
让我们看看 60 毫秒的 ptime 与 20 毫秒的对比。假设 RTP 头部扩展为 20 字节,20 毫秒分包情况下,每秒有 50 个数据包(1 秒 /20 毫秒);60 毫秒分包情况下,每秒有 16.7 个数据包(1 秒 /60 毫秒)。因此,20 毫秒 ptime 的头部开销与 60 毫秒 ptime 的差异为(50-16.7 个数据包 / 秒)×50 字节 / 数据包 ×8 比特 / 字节 =18,648 比特 / 秒 ,即 18.6 千比特每秒。18.6 千比特每秒可以显著提升编码比特率下的音频质量。
2.5、音频网络适配器
在通话过程中,分包长度可以动态调整。WebRTC 使用一个名为音频网络适配器(ANA)的组件来实现这一点。其理念是在网络状况良好时,发送高质量(通过更高比特率)和低延迟(通过更小分包长度)的音频,反之亦然。
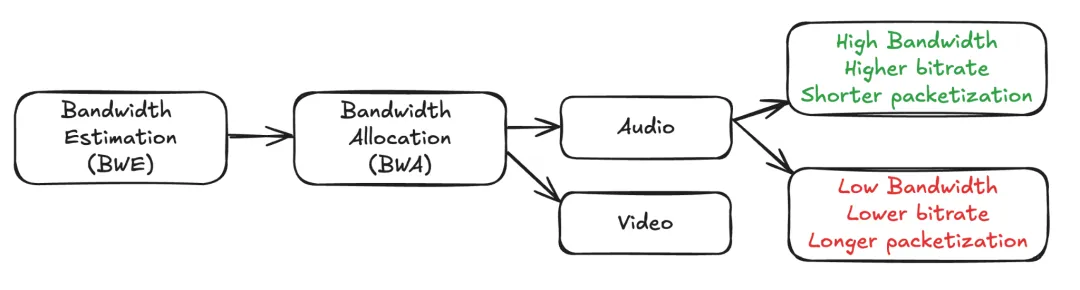
一般来说,网络状况良好时应使用 20 毫秒的分包长度,网络状况较差时可以使用 60 毫秒甚至 120 毫秒。理论上,10 毫秒的分包长度也是可行的,但很少使用。
3、网络异常
网络并不完美。可能会因路由器故障导致数据包丢失;网络过度使用会造成数据包延迟;甚至你的设备网络端口可能会出现线程问题。NetEQ 被设计用于克服数据包到达模式的不规律性。
让我们分类 NetEQ 所关注的常见网络问题。
3.1、抖动
NetEQ 的大部分逻辑用于处理 数据包抖动。数据包从发送端均匀发出,但并不一定均匀到达接收端。换句话说,网络传输时间在各个数据包之间波动。网络抖动可分为以下几类:
- 突发到达:接收端在一段时间内没有收到任何数据包。然后多个数据包同时到达接收端。人们可能觉得这种模式极端,但它却是 最为常见的网络异常。
- 轻微抖动:一个或多个数据包到达时间有轻微延迟。之后到达的数据包迅速赶上。根据 NetEQ 的逻辑,延迟应小于分包长度,否则会被归类为突发到达。
- 永久性网络延迟变化:从某一时刻起,网络传输时间永久性增加或减少。接收端会观察到一次到达时间间隔的跳跃 / 下降,但之后不再有抖动。
3.2、丢失
数据包丢失恢复是 WebRTC 中的热门话题。NetEQ 只是处理网络丢失的众多组件之一。尽管本文聚焦于 NetEQ 的抖动补偿功能,但我想概述音频丢失恢复机制,以解答基本问题。
3.2.1、丢失检测
每个数据包都被分配了一个序列号。接收端可以通过查找这些数字之间的间隙来检测数据包丢失。类似的丢失信息也会通过 RTCP 接收报告(RTCP RR)和传输宽 congestion control(TWCC)算法作为反馈发送给发送端。
3.2.2、音频丢失恢复机制
在 WebRTC 应用中,常见的音频丢失恢复机制分为两类:
- 主动式:带内前向纠错(FEC)、带外 FEC、RED
- 被动式:否定确认(NACK)/ 重传
WebRTC 原生支持 Opus 带内 FEC、RED 和 NACK(重传)。带外 FEC——即在 Opus 内置编码机制之外发送冗余音频——由开发者自行实现。
3.2.3、重传与 NetEQ
如果开发者在 SDP 中明确协商 NACK,NetEQ 将通过 RTCP NACK 消息请求音频重传。
一个常见问题是 NetEQ 是否会主动 等待重传,答案是否定的。最大的原因是接收端无法区分重传数据包和普通数据包。
视频侧的 RTX 流可以区分常规 / 重传数据包,但音频侧尚未实现这一功能。换句话说,重传音频数据包和常规数据包具有相同的 SSRC,因此接收端无法识别哪些数据包是音频 NACK 的结果。
尽管 NetEQ 不会故意等待重传,但接收到一定数量的重传数据包后,抖动缓冲长度最终会变大。这是因为重传数据包通常较晚到达,类似于网络抖动,从而增大 NetEQ 延迟。
3.3、其他
数据包乱序(顺序错乱)是指数据包到达接收端的顺序与发送顺序不同。人们可能认为这是现实世界中的普遍问题,但实际上,除了 NACK 重传的数据包外,这种情况很少见。
4、libWebRTC 的 NetEQ 实现
现在我们将深入探讨 WebRTC NetEQ 实现的细节。
5、NetEQ 架构
NetEQ 有两个主要 API:InsertPacket和 GetAudio:
- InsertPacket存储来自网络的音频数据包。
- GetAudio返回正好 10 毫秒的音频样本。它必须由播放线程每秒精确调用 100 次。理想情况下,
GetAudio每 10 毫秒被调用一次,用于设备播放。
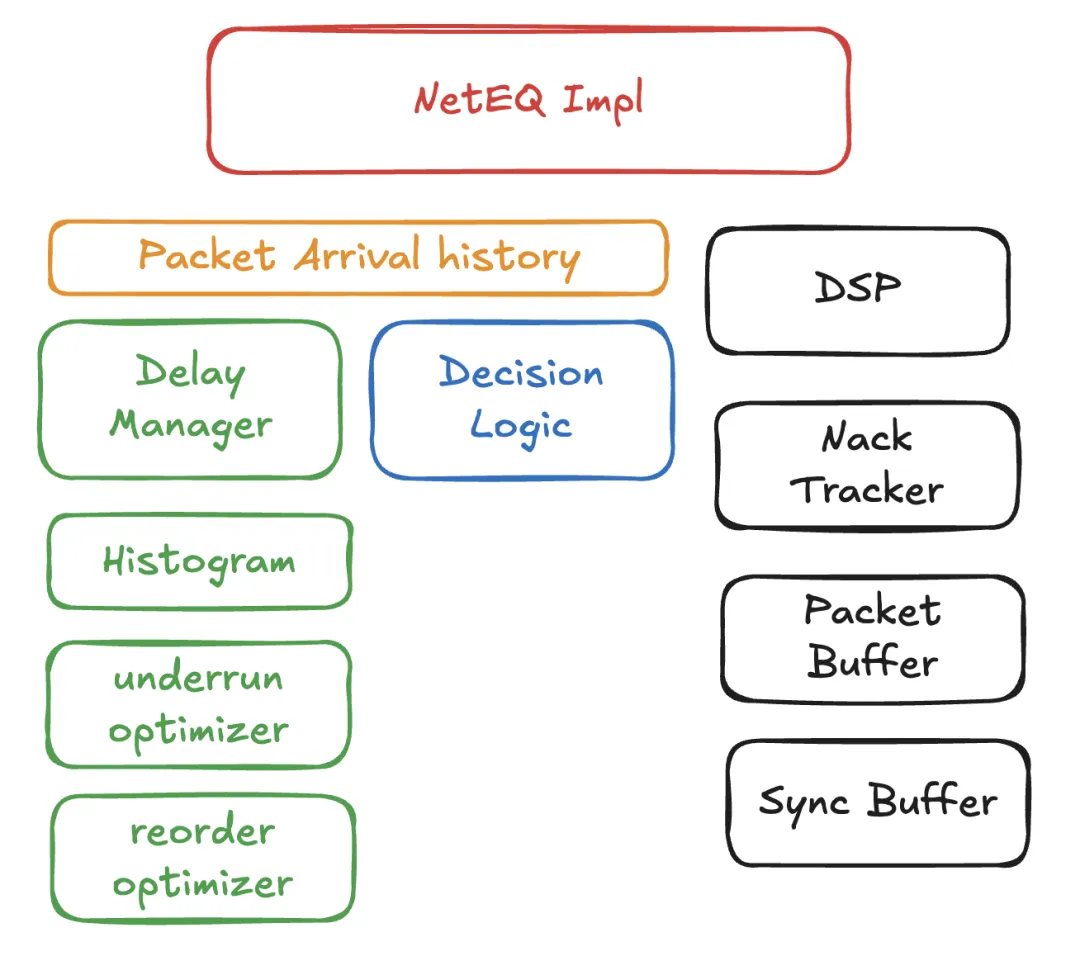
在 NetEQ 文件夹内的 100 + 个文件中,骨干是 neteq_impl、delay_manager和 decision_logic:
neteq_impl是主要协调器delay_manager负责延迟估计decision_logic负责缓冲区管理
你可以在这里找到所有 NetEQ API。
5.1、NetEQ Impl
neteq_impl.cc具体化 NetEQ API,并作为主要协调器。
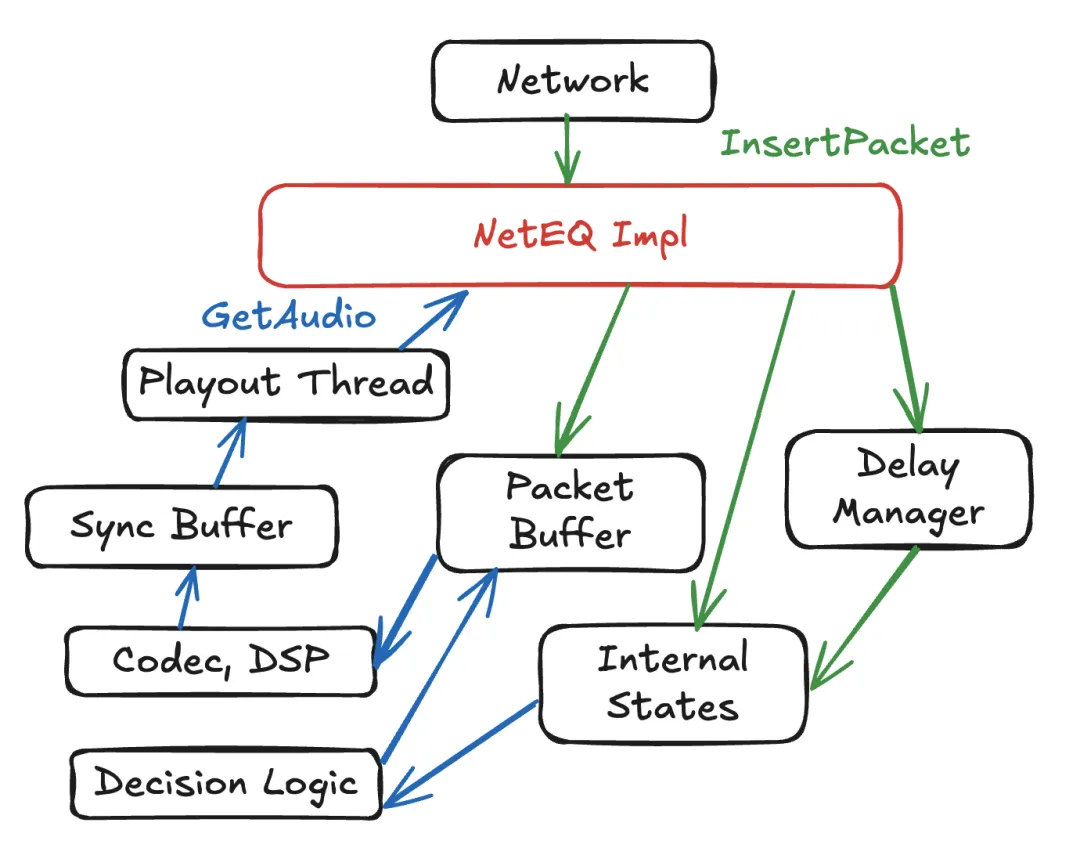
当数据包从网络到达时,调用 InsertPacket。这将执行以下操作:
- 分离主动保护的 FEC 和 RED(如果有的话)
- 调用
delay_manager更新延迟估计 - 将数据包插入
packet_buffer - 更新所有内部状态,如同步缓冲区长度、统计信息、采样率、DTX、静音等
注意:有关音频 RED 的更多背景,请参阅通过冗余提高音频质量。尽管 RED 作为单独的编解码器进行协商,而不是像 FEC 那样的属性,但在接收端,NetEQ 通过直接从有效载荷解析冗余内容来类似地处理 RED 和 FEC。
当播放线程请求 10 毫秒的音频样本时,调用 GetAudio函数:
- 向
decision_logic提供内部状态和 TargetLevelMs(来自delay_manager)。 - 根据
decision_logic的指令,neteq_impl可能会从同步缓冲区提取数据包,通过编解码器解码数据包,使用数字信号处理(DSP)—— 扩展、加速、语音拉伸等—— 对解码后的音频样本进行后期处理,并将样本放入同步缓冲区(一个中间短缓冲区)。我们将在决策逻辑部分解释这些概念。 - 从同步缓冲区提取 10 毫秒的样本并返回,以响应
GetAudio调用。
同步缓冲区
“同步缓冲区” 这个名字并不直观。它实际上是一个中间缓冲区,用于存放解码后的音频样本。例如,使用 60 毫秒的分包长度,解码一个数据包后,同步缓冲区将有 60 毫秒的音频样本。每个 GetAudio()调用仅请求 10 毫秒的音频样本,不多也不少。因此,同步缓冲区保存了多余的部分,并允许立即响应下一次 GetAudio()调用。
同步缓冲区还辅助 DSP 操作。当需要语音拉伸操作时,从同步缓冲区提取音频样本,经 DSP 处理后放回;当 NetEQ 音频扩展需要时,DSP 使用先前提取的音频样本进行插值。
6、NetEQ 数据包延迟测量的演变
在本文中,我们使用 60 毫秒的固定分包长度以便于说明。
delay_manager根据网络状况生成 目标水平(目标延迟)。当大量数据包 延迟时,delay_manager应输出更高的目标延迟,以便数据包在缓冲区中停留更长时间。decision_logic管理缓冲区中的数据包。如果一个数据包已到解码时间,decision_logic会从缓冲区中移除该数据包进行解码。
但是 delay_manager如何量化一个数据包应延迟多少?decision_logic又如何断言一个数据包已到解码时间?让我们借助 数据包相对延迟的概念来解决这个问题。
6.1、哪个数据包传输更快
网络状况每毫秒都在波动,因此每个数据包的网络传输时间各不相同。由于设备时钟可能偏移,我们无法 “精确” 计算单个数据包从发送端到接收端的传输时间。然而,仍然可以使用以下公式比较两个数据包之间的传输时间(从发送端到接收端)。
P1_P2_travel_time_difference
= (P2_arrival_ntp_ms - P2_rtp_ts / sampling_rate + clock_shift_ms) - (P1_arrival_ntp_ms - P1_rtp_ts / sampling rate + clock_shift_ms)
= (P2_arrival_ntp_ms - P2_rtp_ts / sampling_rate) - (P1_arrival_ntp_ms - P1_rtp_ts / sampling_rate)
当公式返回一个正数时,表示 P2比 P1传输得慢,反之亦然。
如果 P2是最近到达的数据包,那么 P1的选择代表 NetEQ 数据包延迟测量的演变。
6.2、经典的到达间隔延迟
到达间隔延迟是指两个连续数据包到达时间的差异。直到 2022 年,NetEQ 一直使用到达间隔延迟来更新 delay_manager。
以 60 毫秒的分包长度为例,接收端每 60 毫秒期望接收一个音频数据包。设想这样一个场景:每 4 个数据包中,第二个数据包延迟 40 毫秒到达,因此其到达间隔延迟为 100 毫秒。自然地,理想的 NetEQ 目标延迟应为 100 毫秒。
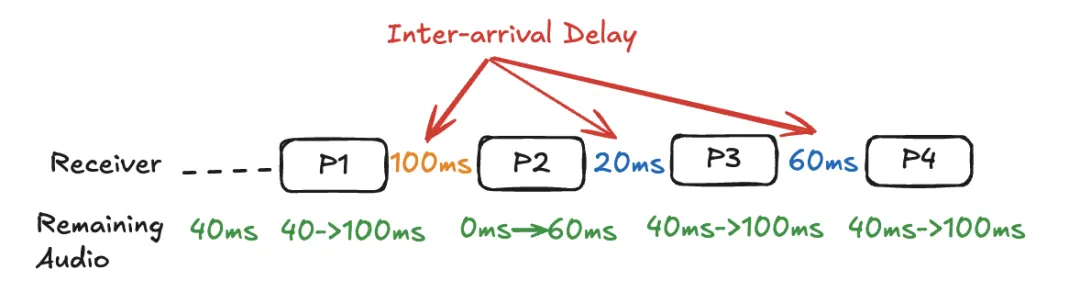
缓冲 100 毫秒的音频在这种情况下运行良好。在 P2到达之前,播放线程刚刚消耗了缓冲区中的所有音频,然后 P2到达。NetEQ 在任何时候都没有耗尽音频样本。
6.3、当到达间隔延迟失效时
如果网络延迟持续恶化会怎样?
在下面的例子中,P3和 P4遭受累积的网络延迟,但使用到达间隔延迟的目标水平仍为 100 毫秒。记住我们以看到的最大到达间隔延迟作为目标延迟进行说明。
在 P3到达之前,缓冲区缺少 40 毫秒的音频;在 P4到达之前,抖动缓冲区再次缺少 40 毫秒的音频,这也被称为抖动缓冲区欠载。
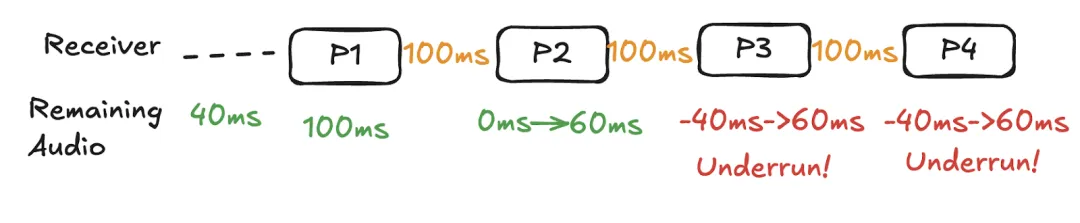
显然,到达间隔延迟无法处理累积的网络延迟。我们需要一个更好的算法来计算数据包延迟 —— 我们将在下一节介绍。
* 注意,在这种情况下,语音拉伸 / 预扩展可能会部分抵消欠载,但音频欠载并未完全消除
。### 相对延迟
相对延迟在 2022 年取代到达间隔延迟,解决了上述确切问题。
使用相对延迟时,我们选择时间窗口内 “最快” 的数据包作为锚点。有关如何测量这一点,请参阅上述 “哪个数据包传输更快” 部分。
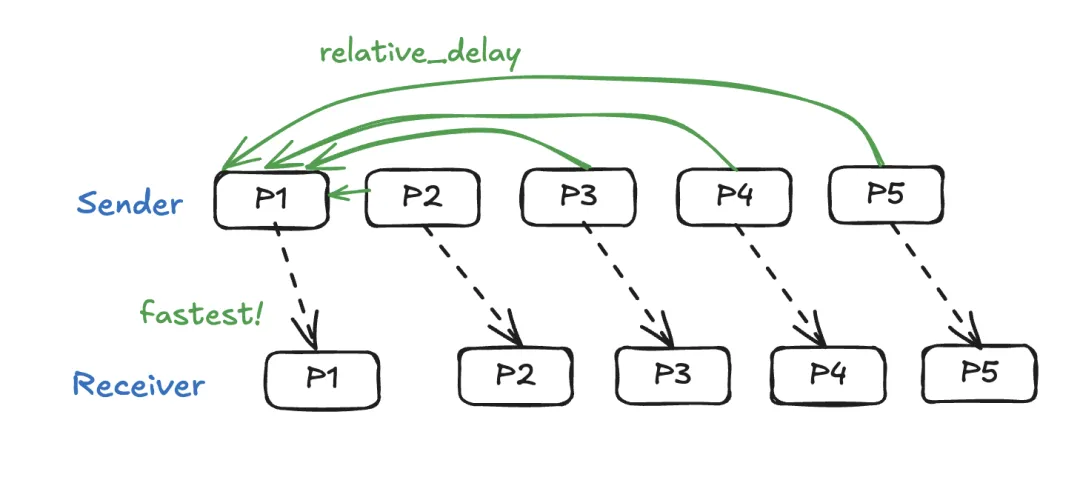
设当前数据包为 Pn,最快的数据包为 Pf,则每个数据包的相对延迟为:
(Pn_arrival_ntp_ms - Pn_rtp_ts / sampling_rate) - (Pf_arrival_ntp_ms - Pf_rtp_ts / sampling rate)
让我们运行上述示例,看看相对延迟如何胜过到达间隔延迟。
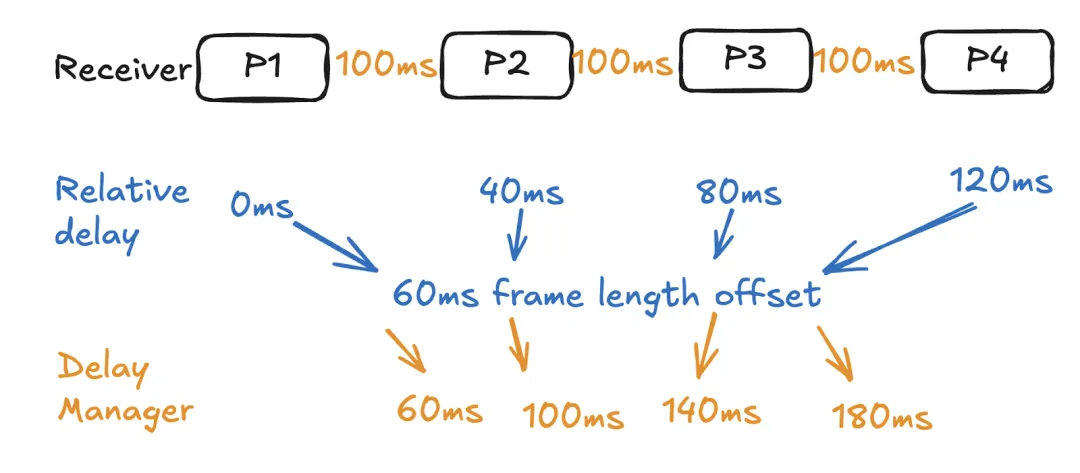
使用相对延迟计算,新的目标水平将变为 180ms。NetEQ 不再缺少音频样本!是不是很神奇?

6.4、情况说明 —— 历史窗口大小
在上述示例中,P1被选为 历史窗口内的最快数据包。WebRTC NetEQ 默认使用 2 秒的窗口大小,但对这个历史窗口有一个直观的理解吗?
思考这个问题:如果数据包传输时间仅永久性增加一次,那么增加抖动缓冲区大小还有意义吗?
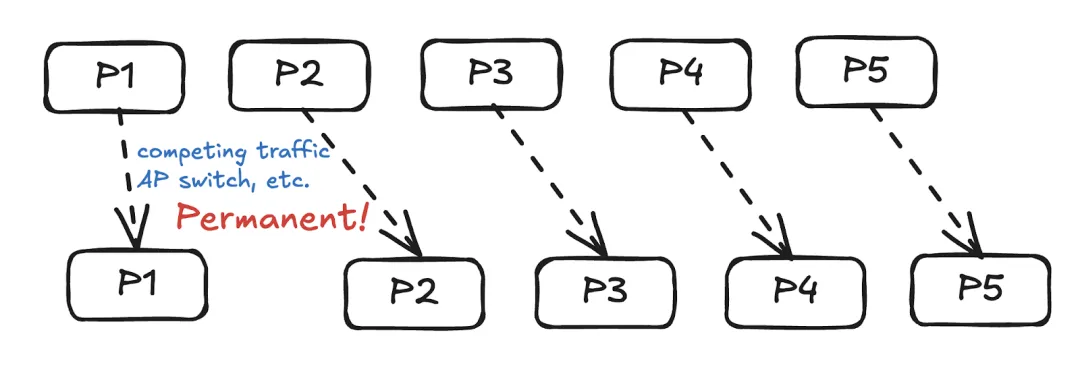
答案是否定的,但相对延迟计算仍然会将 2 秒内的较大值推送给 delay_manager。窗口大小是一个启发式值,用于区分临时抖动和永久延迟变化:
- 如果过去 2 秒内数据包传输时间曾增加,那么较大的延迟值会被推送给延迟管理器。
- 否则,这种传输时间增加是永久性的 / 一次性的,因此我们不再用较大的延迟值更新延迟管理器。
在实践中,默认的 2 秒窗口并非适用于所有场景,而是一个可调参数。
7、延迟管理器
delay_manager汇总前几个数据包的相对延迟,然后输出一个 目标水平以控制抖动缓冲延迟。
在高层次上,有两个数据包到达跟踪直方图:欠载直方图和乱序直方图。delay_manager取两个直方图的最大目标水平作为最终目标水平。
- 两个直方图都使用 遗忘因子(介于 0 和 1 之间的指数因子)来控制直方图忘记之前值的速度。遗忘因子较大时,直方图接受新相对延迟的速度较慢。
- 欠载直方图使用分位数选择目标水平,而乱序直方图使用成本函数。
7.1、遗忘因子
遗忘因子控制直方图忘记之前延迟值的速度。默认的硬编码值 0.983 用于捕获低频事件。
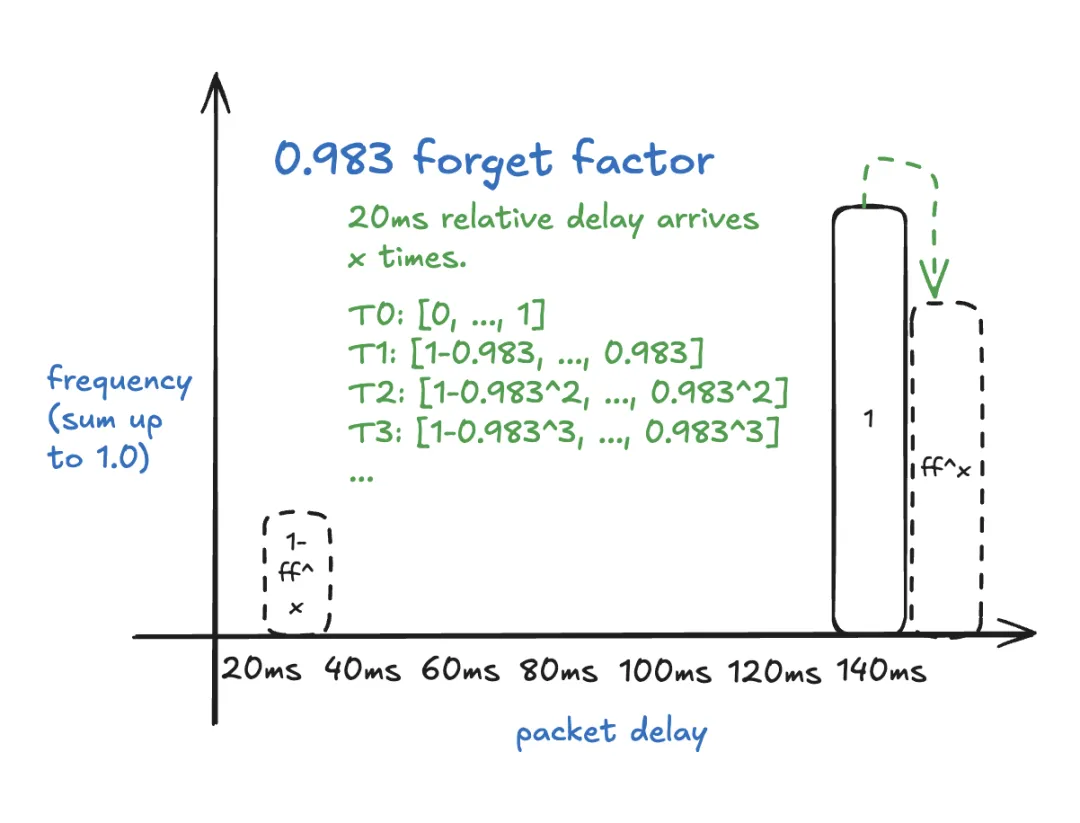
直方图中所有桶的值之和为 1。每当有一个新的相对延迟到达时,所有值乘以 遗忘因子,使得新的总和正好为 遗忘因子。然后,将(1-遗忘因子)添加到新 相对延迟所属的桶中。查看以下示例以便轻松理解。
那么,直方图需要多长时间才能忘记 “相对延迟”?在上述示例中,使用 20 毫秒的分包长度,新的 20 毫秒目标延迟取代旧的 140 毫秒目标延迟需要 3.5 秒(175 个数据包)。
7.2、欠载直方图
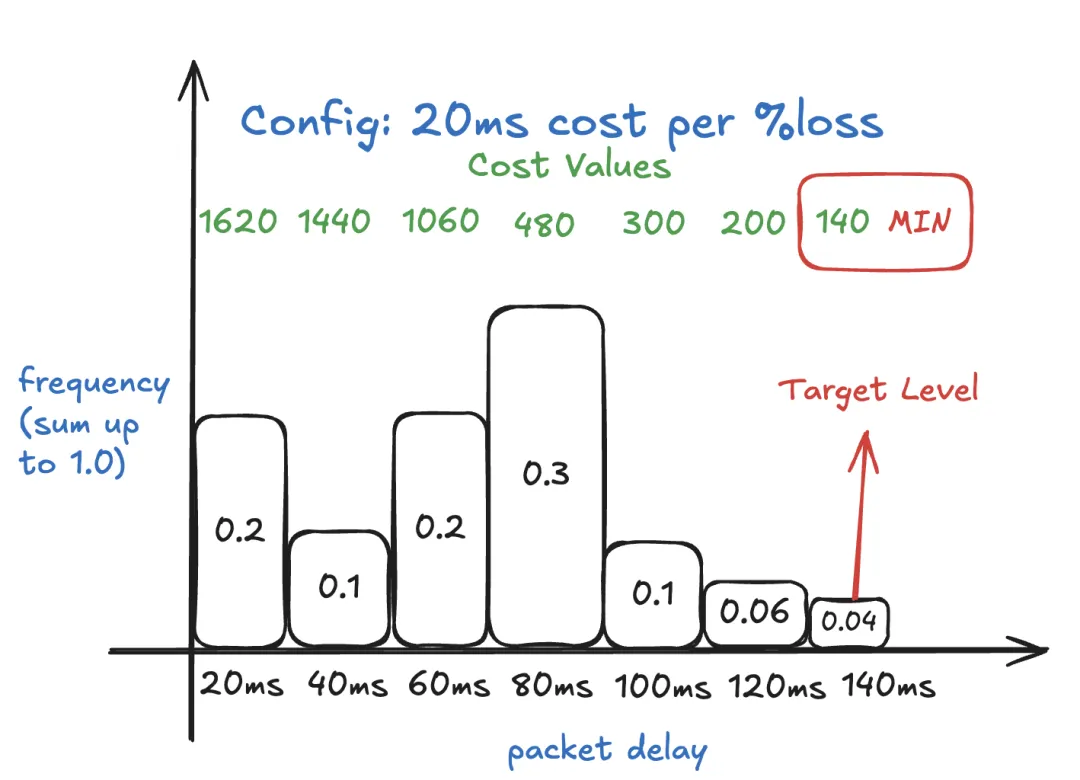
欠载直方图跟踪整个会话期间的相对延迟。它旨在捕获低频事件,例如 “在整个会话期间,每 10 秒出现 100 毫秒的数据包延迟”。
20 毫秒是直方图的良好桶大小。请注意,这个桶大小与分包长度无关。它们是正交的!每个桶包含对应相对延迟值的频率(介于 0 和 1 之间)。
在下面的示例中,20% 的数据包具有 20 毫秒的相对延迟,10% 的数据包具有 40 毫秒的相对延迟……6% 的数据包具有 120 毫秒的相对延迟,4% 的数据包具有 140 毫秒的相对延迟。
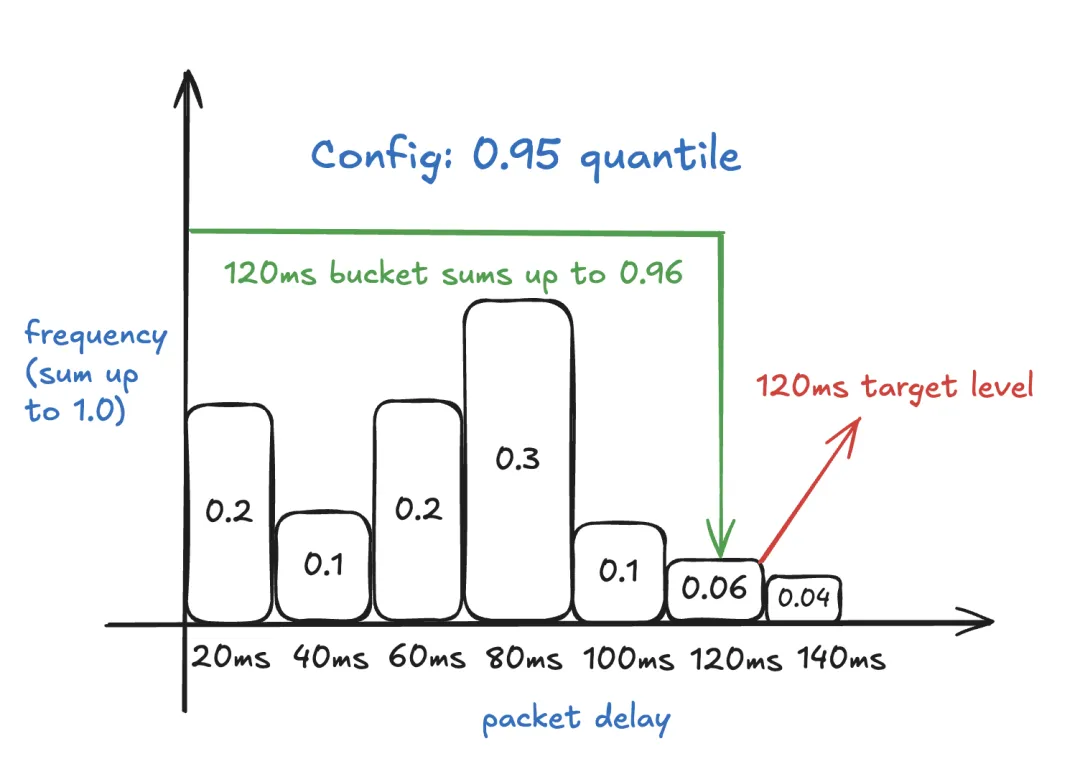
delay_manager取欠载直方图的分位数作为目标水平。例如,如果分位数为 0.95,那么选择 120 毫秒作为目标水平,因为该桶的累积值为 0.96,大于 0.95。分位数是原生应用中的良好调优旋钮,意味着 NetEQ 应该适应的网络延迟百分比。
7.3、乱序优化器
在连续 / 突发数据包丢失下,FEC 无法补偿所有丢失的数据包,因为它只包含前一个数据包的信息。在这种情况下,重传是恢复丢失音频的唯一机制。这时乱序直方图就派上用场了。
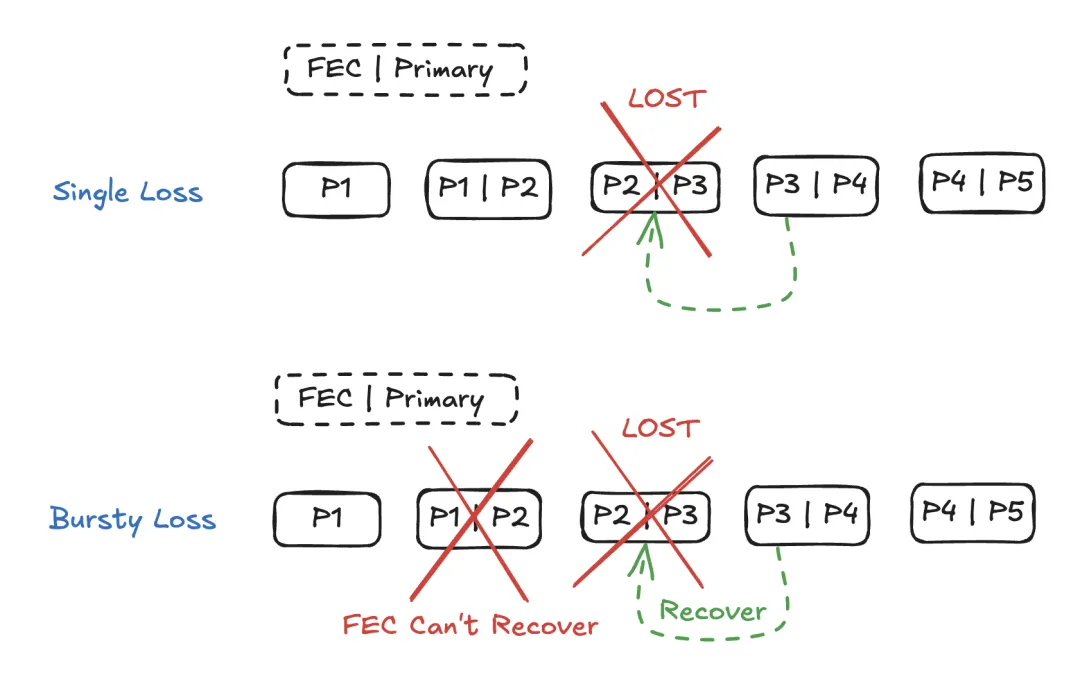
reorder_optimizer跟踪乱序数据包,并将顺序正确的数据包放入第一个桶中。VoIP 产品通常由于重传而经历数据包乱序。换句话说,reorder_optimizer是一个调优旋钮,用于适应重传数据包。
在延迟和丢失恢复之间存在权衡。即使请求的每个重传数据包都到达接收端,除非抖动缓冲区有足够的缓冲来适应延迟,否则这些数据包也无法被利用。reorder_optimizer提供了一个框架,用于在延迟和丢失恢复之间做出权衡决策。
reorder_optimizer不使用固定的分位数作为目标水平,而是使用 权衡函数 = 延迟 ms +20 毫秒 × 丢失百分比。丢失百分比默认为 20,但值得调优。
权衡函数计算延迟和数据包丢失之间的综合成本。然后,reorder_optimizer遍历所有潜在的延迟,并选择具有最小成本的最终目标延迟。
8、决策逻辑
delay_manager摄入网络数据并提供目标延迟,而 decision_logic实际上承担了维护抖动缓冲延迟的重任。
decision_logic.cc决定解码音频数据包的时机、后期处理音频样本、执行丢失隐藏以及进行抖动补偿。decision_logic在 2022 年与 delay_manager一起完全重构,我们将深入探讨。
8.1、决策逻辑状态机
在决策逻辑内部,NetEQ 可以执行的操作集是有限的。相应地,NetEQ 可能遇到的场景集也是有限的:
- 当前抖动缓冲延迟大于目标延迟 —— NetEQ 引入的延迟超过了必要水平。换句话说,缓冲区中的数据包比期望的多。在这种情况下,
decision_logic将执行 加速操作。它利用加速算法缩短每个数据包的播放时长。 - 当前抖动缓冲延迟小于目标延迟,因此存在音频欠载的高风险。与加速相反,
decision_logic执行 预防性扩展操作以减慢音频播放速度。 - 没有更多的音频数据包或音频样本可用。
decision_logic继续执行扩展操作,最初拉伸最后的音频样本,最终产生静音。注意 “扩展操作” 可以由 neteq 扩展或编解码器 plc 执行。 - 下一个数据包不可用,但未来数据包可用,这代表数据包丢失。
decision_logic执行与上述相同的 “扩展操作”。在执行一些 “扩展操作” 之后,decision_logic转而解码可用数据包。 - 毫无意外,最后一种场景是当抖动缓冲区没有丢失,且延迟如
delay_manager所指示的那样。decision_logic仅执行 正常操作,即解码数据包并播放音频样本,不进行任何时间拉伸算法。 - 对 DTX、静音状态等进行特殊处理。
8.2、数据包延迟与缓冲区长度
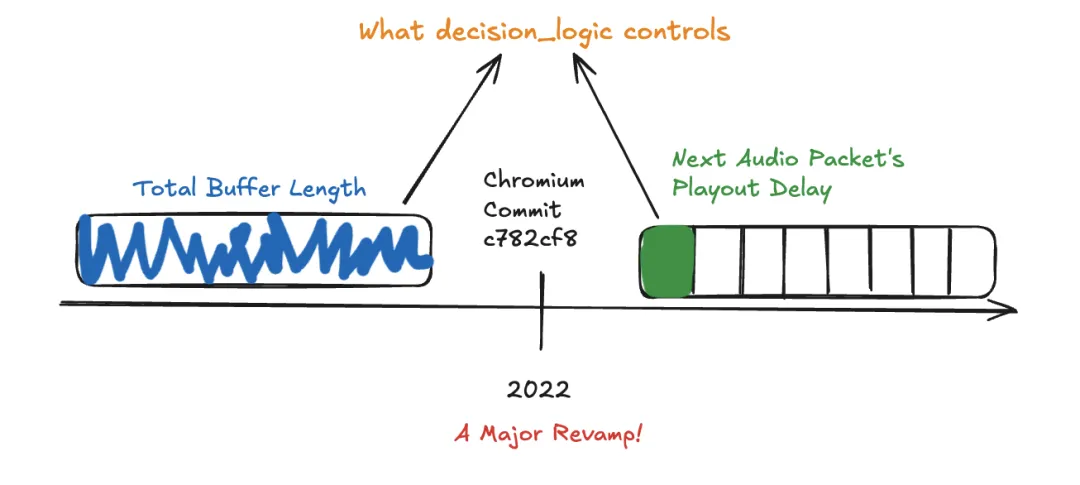
decision_logic是控制单个数据包的延迟,还是控制缓冲区中缓存的数据包数量?
在当今的 WebRTC NetEQ 实现中,decision_logic使用类似于相对延迟的函数来控制 当前播放延迟,这代表单个数据包的延迟。然而,在 2022 年之前,NetEQ 一直通过控制 总缓冲区长度来维护抖动缓冲延迟。
这两种机制本质上不同,因此导致不同的结果。我们将马上深入探讨其中的差异。
8.3、相对延迟之前 / 2022 年之前
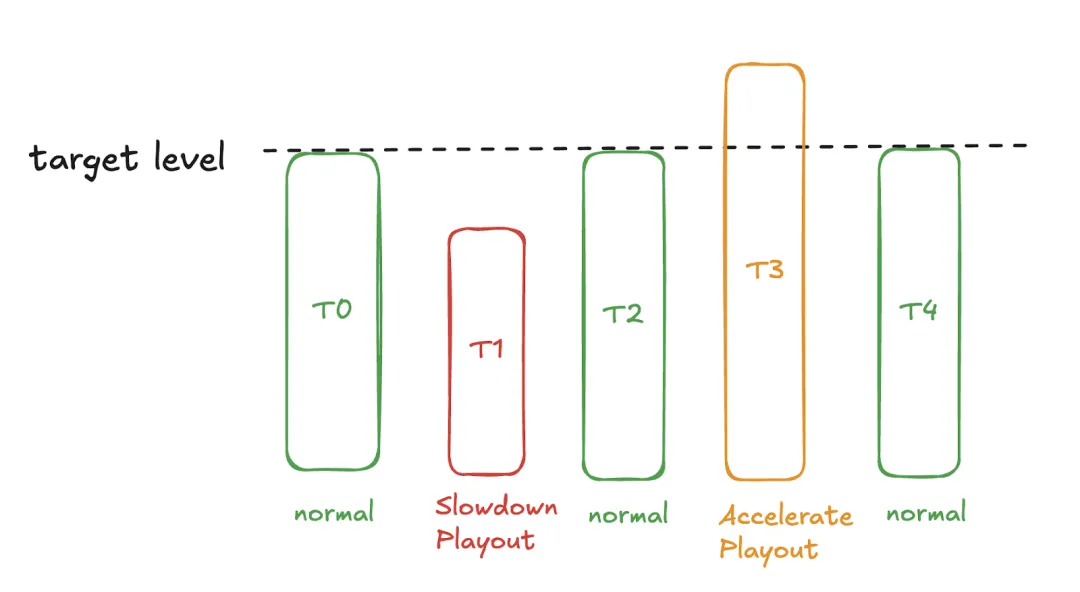
直观上,目标水平意味着缓冲区应该包含多少音频样本:
- 如果缓冲区包含的音频样本 多于目标水平值,则以 加速的速度播放音频。
- 如果缓冲区包含的音频样本 少于目标水平值,则以 减速的速度播放音频。
- 否则,以原始速度播放音频。
8.4、直接管理缓冲区长度的缺点
尽管直接管理缓冲区长度最为直观,但它会导致语音加速和减速带来的不必要音频失真。
假设目标水平为 120ms,分包长度为 60ms。P1延迟 60ms到达,与 P2一起到达。
当到达 P1的预定时间(60 毫秒时间戳)时,缓冲区长度为 60ms,开始执行预防性扩展以减慢音频播放速度。预防性扩展允许缓冲区在 120ms时间戳时保留 20ms的音频。然后 P1和 P2一起到达,这使得缓冲区包含 20 + 120 = 140ms的音频,并触发 语音加速。
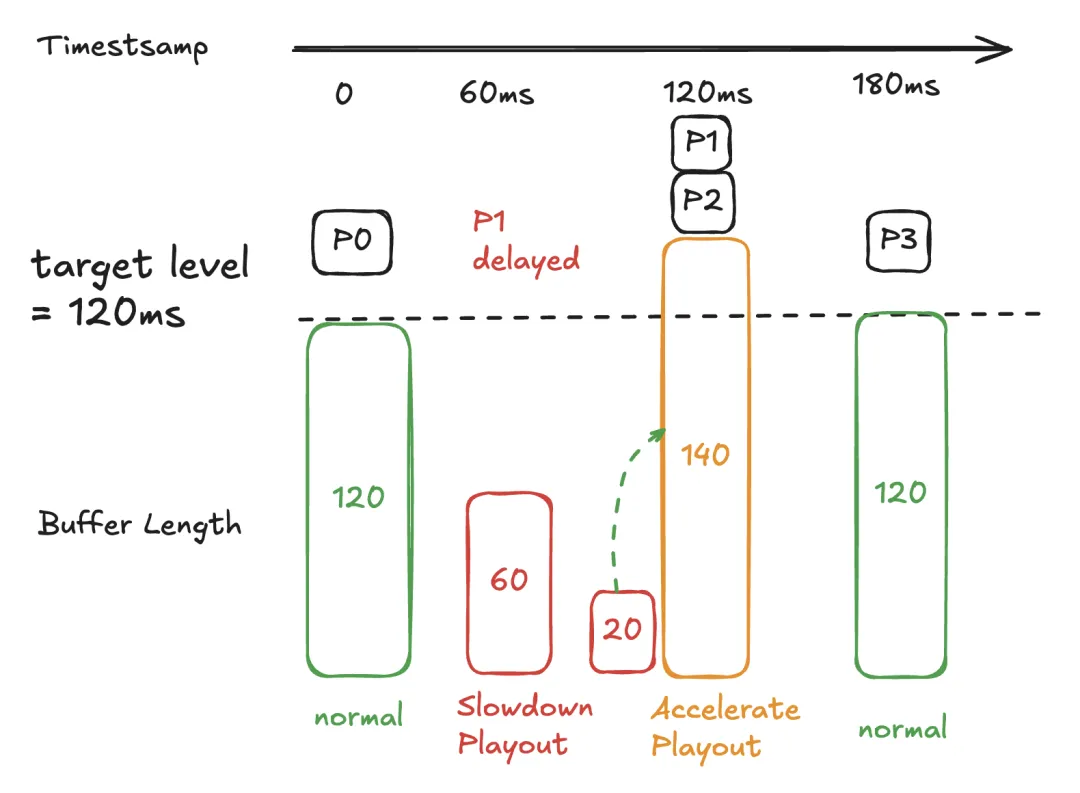
回顾来看,在网络准确估算 P1的延迟为 120 毫秒的情况下,预防性扩展其实并无必要。
8.5、更好的方法
现在,与其匹配缓冲区大小与目标水平,decision_logic使用 当前播放延迟与目标水平进行比较。直观上,当前播放延迟表明当前音频播放是超前于计划还是落后于计划。
设缓冲区中的下一个数据包为 Pn,时间窗口内的最快数据包为 Pf(与相对延迟计算中使用的相同数据包)。那么 Pn的播放延迟为:
(current_ntp_ms - Pn_rtp_ts/sampling_rate) - (Pf_arrival_ntp_ms - Pf_rtp_ts/sampling rate)然后决策逻辑将数据包延迟与目标水平进行比较:
- 如果缓冲区中不存在
Pn(下一个数据包),则执行 数据包丢失隐藏(PLC)。 - 当
Pn_packet_delay< 目标水平时,这意味着播放这个数据包还为时过早,但它的前驱数据包都已消失 —— 我们不得不以更慢的速度播放它。 - 当
Pn_packet_delay> 目标水平时,这意味着这个数据包早就应该播放了,我们应该加速它的播放。
在下面的例子中,在 60 毫秒的时间标记处,下一个数据包是 P0,其延迟正好与目标延迟相同。因此,P0被正常解码和播放;P1、P2和 P3也是如此。这比 “先减速,再加速” 更高效。
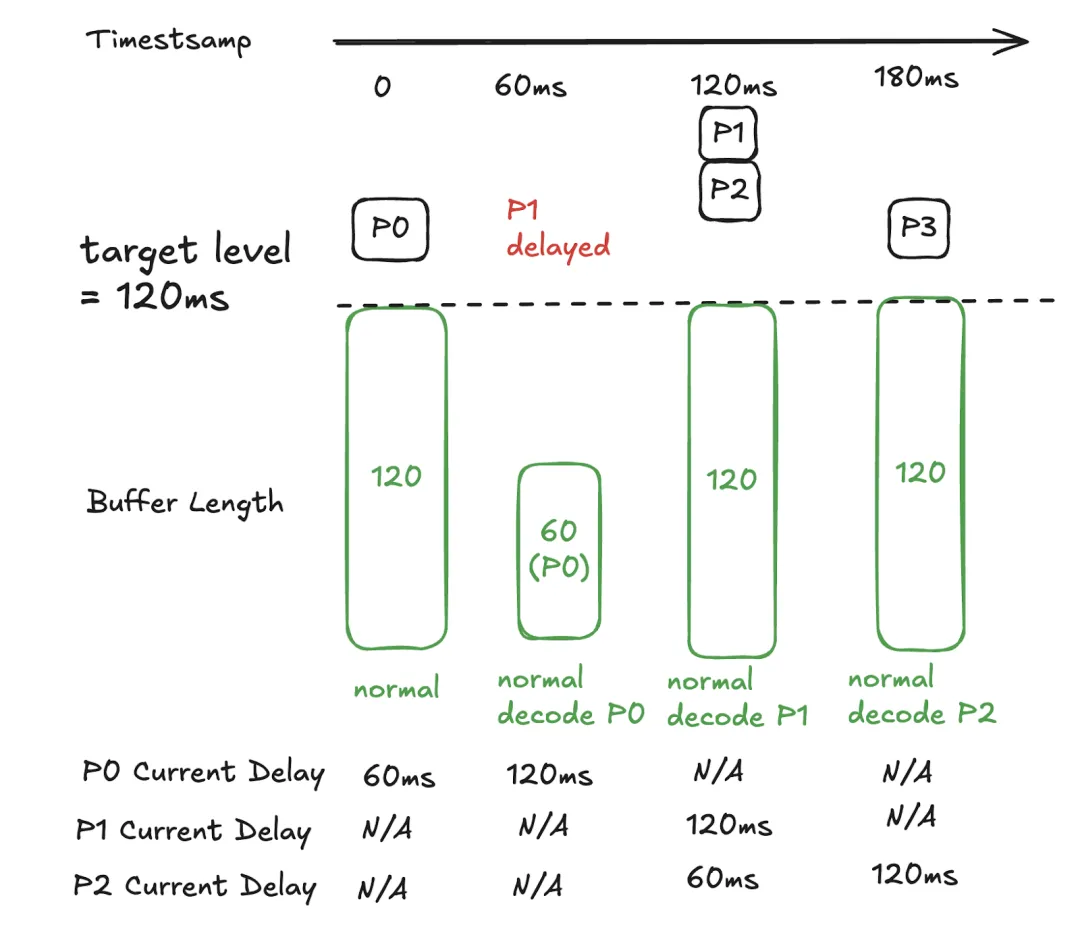
* 注意,实际的 neteq 代码并不一定抓取下一个数据包来计算当前延迟。它也可能抓取同步缓冲区中的下一个音频样本。
9、结论
NetEQ 提供了一个坚实的音频抖动缓冲框架。它涵盖了所有关键组件(数据包管理、延迟估计、数字信号处理、协调等),并且高度灵活,便于修改。
开箱即用时,它对大多数应用来说运行合理良好。当扩展到数百万用户时,高延迟和音频卡顿问题可能会在长尾分布中出现。没有一种固定公式能适用于所有场景。
理解 delay_manager和 decision_logic的基础知识只是开始。要让 NetEQ 为你的应用完美运行,需要仔细思考你的应用特定需求。有时是其他组件(如拥塞和设备)导致 NetEQ 出现故障。阅读日志,添加日志,亲自动手,享受调试吧!
音视频方向学习、求职,欢迎加入我们的星球
丰富的音视频知识、面试题、技术方案干货分享,还可以进行面试辅导

版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。