
写在前面:视频数据作为视觉信息处理中最大的大数据类别,正以指数级速度增长,长期主导全球网络流量。新兴应用场景如超高清视频、交互式视频会议与远程屏幕共享,对视频编解码提出了更高要求。人工智能技术的融合为该领域提供了全新的研究方向,依托深度学习实现高效压缩、智能传输和优质体验,成为推动视频通信与多媒体处理演进的重要驱动力。
作者:马丽萌;审核:毕蕾 邢刚 徐嵩 郭佩佩
来源:咪咕灯塔智库
原文:https://mp.weixin.qq.com/s/IJR9uIM3h14BiTZy9lqR9Q
背景篇
在移动互联网和5G技术的推动下,视频已成为现代社会最重要的信息载体。从抖音、快手的短视频狂欢,到腾讯会议、钉钉的远程办公,从咪咕视频、爱奇艺、腾讯等高清影视,到即将到来的元宇宙应用,视频内容正以前所未有的速度增长。这种爆炸式增长不仅体现在数量上,更体现在质量要求上。用户对4K、8K超高清视频的需求日益增长,120fps高帧率、HDR高动态范围等技术不断普及,VR/AR应用对视频质量提出了更苛刻的要求。然而,更高的视频质量意味着更大的数据量,这对网络传输、存储空间和计算资源都带来了巨大挑战。
传统视频编码
为了解决视频数据的存储和传输问题,视频编码技术应运而生。几十年来,从早期的H.264/AVC到H.265/HEVC,再到最新的H.266/VVC标准,传统视频编码技术不断演进,形成了一套成熟的”混合编码框架”。现有的传统视频编码标准采用基于块的变换-预测混合编码框架,在帧内预测中,编码器将帧划分为块,并基于相邻已重建块选择最佳预测模式(如方向性预测)来预测当前块内容,仅传输模式索引和微小的残差。在帧间预测中,编码器通过运动估计在参考帧中找到一个最相似的块作为预测假设,仅传输运动矢量(位移信息)和残差。通过这种预测来去除视频中的空间和时间冗余,再对极少的残差进行编码,从而实现高效压缩。这一框架的核心思想是通过多个模块协同工作来消除视频中的冗余信息:
- 预测编码消除时间和空间冗余。消除空间冗余,通过帧内预测,利用帧内已编码区域的信息来预测当前区域。消除时间冗余,通过运动估计和运动补偿,利用相邻帧的相似信息来预测当前帧,只编码预测后的残差。
- 变换与量化将残差信号从空间域转换到频率域,通过量化去除人眼不敏感的高频信息,实现有损压缩。
- 熵编码对量化后的系数进行无损压缩,进一步减少数据量。
- 环路滤波在解码端消除编码过程中产生的块效应等伪影,提升视觉质量。
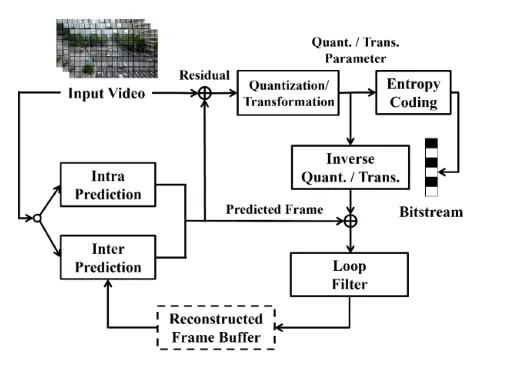

尽管传统的视频编码标准取得了巨大的成功,但在有限的编码复杂度增加下实现较大的压缩性能提升越来越具有挑战性。
- 模块化设计带来协同优化难题,当前编码流程由预测、变换、量化、熵编码等独立模块组成,各模块通常在局部目标下优化,缺乏跨模块的联合调优机制。例如,提升运动估计精度虽有助于降低残差能量,但也可能增加运动信息的编码开销,整体收益未必最优。
- 编码工具激增推高实现复杂度,为追求更高压缩率,新一代标准(如H.266/VVC)引入了大量编码工具与模式选项,需通过复杂决策搜索确定最优配置。这使得编码复杂度相较前代标准增长数倍,不仅对云端转码资源提出更高要求,也对移动端设备的功耗与实时性构成压力,限制了在资源受限场景的广泛应用。
- 固定规则难以适配多样化内容。现有编码器主要依赖人工设计的算法和预设参数,面对自然视频、动画、屏幕内容、游戏画面等不同特性时,缺乏动态适配能力。
- 现有架构对新兴场景支持有限。在VR/AR、云游戏、元宇宙等新应用中,视频呈现形式与交互方式发生根本变化(如360度全景投影、视口自适应、超低延迟编码等需求)。
人工智能的破局之道
上述挑战并非偶然,而是传统“人工规则+模块割裂+静态优化”架构在面对海量多样视频内容与新兴场景时的必然局限。AI的引入,正是从方法论层面,用“数据驱动+端到端学习+内容自适应”,对这些系统性瓶颈进行的针对性回应。人工智能技术为视频压缩领域提供了新的优化思路和工具,尤其在提升压缩效率、降低复杂度、内容自适应等方面展现出显著潜力。
- 从人工设计到自动学习:传统编码器的每个模块都基于专家经验和数学理论设计,而AI可以从海量数据中自动学习最优的编码策略,无需人工干预,从而解决了传统方法的自适应性差和人工调参耗时的问题。
- 从局部优化到全局优化:神经网络支持端到端训练,可以将整个编码流程作为一个整体进行优化,突破传统模块化设计的局限,从而突破了传统模块化设计的全局优化瓶颈,实现更高效的整体性能。
这种范式转变正在催生两条并行的技术路径:一是AI辅助编码,尝试在传统编码模型中引入神经网络模块,来优化预测、环路滤波等关键组件,形成了一系列混合编码框架及标准,提高了压缩效率并降低了编码时间;二是AI端到端编码,构建完全基于神经网络的端到端的视频编码,通过端到端的训练和优化,能够提高编码工具的灵活性,通过统一的率失真函数来实现更高的压缩效率。
技术篇
为了更清晰地理解人工智能在视频编解码中的作用,本篇将从两个层面展开:一方面介绍当前的主要技术路径,包括如何在传统框架中引入人工智能工具,以及端到端神经网络压缩的最新探索;另一方面结合MPEG(Moving Picture Experts Group)、MPAI(Moving Picture, Audio and Data Coding by Artificial Intelligence)、AVS(Audio Video coding Standards)等标准化组织的工作,梳理国际国内在AI编解码方向上的研究与推进情况。
技术路径一:AI辅助编码
AI辅助编码是将AI技术作为“插件”嵌入到现有的传统编码框架中,以提升特定模块的性能。这种渐进式的方法可以利用深度学习的优势,同时保留现有编码标准的兼容性和互操作性,被视为AI赋能视频编码的当下主流方向,主要应用在以下环节。
- 深度学习环路滤波: 这是AI在传统编码中应用最成功的领域之一。深度学习环路滤波是AI在传统视频编码中应用最成功的方向之一。传统滤波器(如去块效应滤波、样点自适应偏移)虽然能够在一定程度上缓解压缩伪影,但设计复杂且效果有限;而基于深度学习的方法则通过大规模数据训练,让模型自动学习伪影的统计特征,从而更高效地去除块效应、振铃效应和噪声,并在此基础上不断演进。最初的研究多采用卷积神经网络来替代或增强传统滤波器,随后逐渐引入循环神经网络和Transformer,以捕捉跨帧时序关系和长程依赖;在此基础上,又出现了残差学习、多尺度卷积、注意力机制等改进结构,以进一步提升画质与压缩效率之间的平衡[1]。
- 智能编码单元划分: 在传统视频编码框架中,编码单元是将图像分块并进行预测、变换和量化处理的基本结构,其划分方式直接决定了编码的灵活性与效率。然而,传统的CU划分方法(如基于四叉树的规则划分)在适应不同内容复杂度时存在局限。AI的引入使得编码单元划分更加智能化。AI可以学习视频内容的复杂性,智能地调整编码单元的划分,以实现更精细、更高效的编码。例如,块重要性映射(Block Importance Mapping, BIM)技术可以根据一个编码单元对未来帧的重要性来为其分配不同的量化参数,将码率智能地分配给关键区域,提升视觉质量[2]。
- AI辅助的运动估计与预测: 通过引入深度学习模型来替代或增强传统基于块匹配与光流的运动补偿方法。其核心原理是利用神经网络自动学习视频序列中的时空相关性和运动特征,将已解码帧作为输入,输出更精确的运动矢量或预测块。与传统线性模型不同,AI方法能够刻画复杂的非线性运动模式(如旋转、变形、遮挡),并可结合生成模型预测潜在参考区域,从而提升运动预测精度、降低残差能量,显著提高视频编码的压缩效率[3]。
- 基于超分网络的空域变分辨率编码:其核心思想是,编码器不再对原始高分辨率视频进行直接编码,而是首先将其下采样到较低分辨率,然后进行编码,从而大幅减少需要传输的数据量。在解码端,一个经过训练的超分辨率神经网络负责将低分辨率的重建视频,智能地恢复到原始的高分辨率。这种方法利用了超分网络强大的细节重建能力,可以在保持甚至优化人眼感知质量的同时,实现更高的压缩比[4]。
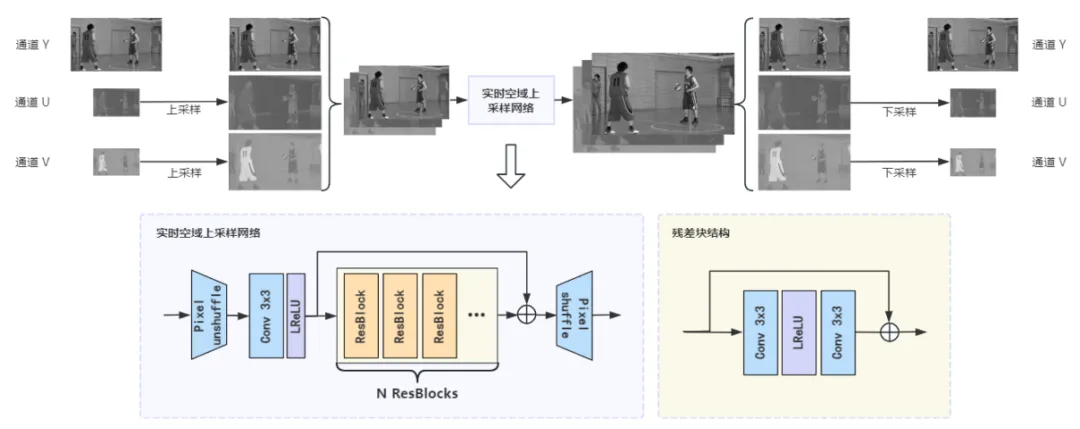
- 基于神经网络的帧内预测:通过利用深度学习模型(如卷积神经网络、Transformer 等)学习图像块间的空间相关性,替代或增强传统视频编码中的线性插值预测方法。其核心原理是在编码过程中,以已解码的相邻像素块或参考区域作为输入,神经网络根据上下文信息生成目标块的预测结果,从而更好地捕捉复杂纹理和非线性结构关系,降低残差能量,提高压缩效率。
- 虚拟参考帧:利用已解码的参考帧和运动信息,通过插值、生成模型或神经网络方法合成出一个未曾真实传输或存储的“虚拟”参考图像,用来增强后续帧的预测精度。这样可以在参考帧有限的情况下,提供额外的预测候选,尤其能够更好地表示复杂运动、遮挡或场景切换,从而减少残差数据量,提高视频压缩效率[6]。
技术路径二:AI端到端编码
AI端到端视频编码依托深度学习技术,打破传统编码中模块独立设计的局限,通过神经网络实现从视频帧输入到压缩码流输出的全流程优化,核心目标是在保证重建质量的前提下最小化码率,同时兼顾编码效率与复杂度。其核心逻辑是将视频压缩的运动估计、运动补偿、熵编码等关键环节融入统一的神经网络框架,通过端到端训练学习数据的内在相关性,从而更高效地去除时空冗余。近年来,端到端视频编码在P帧(基于前一个参考帧进行运动补偿预测的帧)领域已取得显著突破,部分方案性能超越传统H.266/VVC标准;但B帧(同时参考前一个和后一个参考帧进行双向预测的帧,通过结合前向和后向的运动补偿,生成更准确的预测帧)编码因需处理双向参考帧的复杂时空关系,性能仍落后于传统codec,成为当前研究的重点方向。
P帧编码方案
P帧编码方案包括运动矢量编码器(Motion Encoder)、运动矢量解码器(Motion Decoder)、运动熵模型(Motion Entropy Model)、时域上下文挖掘模块(Temporal Context Mining)、上下文编码器(Contextual Encoder)、上下文解码器(Contextual Decoder)、上下文熵模型(Contextual Entropy Model)、帧生成器(Frame Generator)。
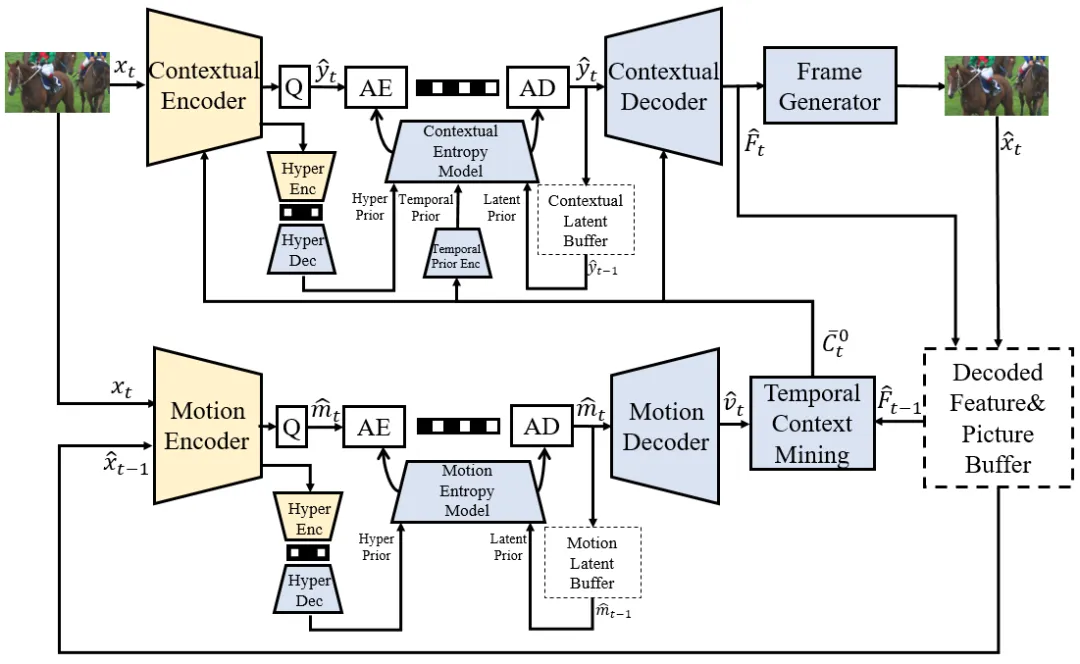
其关键技术包含以下内容:
- 运动估计与补偿技术,P帧的运动估计与补偿技术负责在当前帧与前面参考帧之间建立准确的运动关系,是去除时间冗余的第一步。人工智能视频编码方法通常采用光流网络(如SpyNet、PWC-Net)进行端到端的运动估计,并结合可变形卷积提升对复杂运动的建模能力,从而生成高质量的预测帧,显著降低后续编码模块的负担。
- 上下文建模技术,上下文建模技术通过将预测帧作为条件信息引入编码过程,替代传统的残差编码方式,使网络能够更灵活地利用时序信息。该方法不再简单做帧间差值,而是让编码器自主决定哪些信息需要保留或压缩,从而提升压缩效率并增强对复杂场景的适应能力。
- 上下文熵建模技术,熵建模的目标是为编码符号提供更精确的概率估计,从而提高压缩效率。P帧编码中常采用超先验结构提取潜在表示的统计特性,并结合空间上下文(如邻域像素)和时间上下文(如历史帧信息)共同估计符号分布,使算术编码更接近信息熵下限,显著节省码率。
- 训练策略技术,P帧模型的训练策略通常采用分阶段训练方式,先优化运动估计模块,再训练上下文和重建模块,最后进行联合微调,以降低训练难度并提升收敛稳定性。同时引入多帧联合训练机制,通过平均多个帧的损失来缓解误差传播问题,并周期性调整拉格朗日乘子以提升关键帧质量,增强长序列的鲁棒性。
B帧编码方案
B 帧双向预测帧是视频编码标准中实现高压缩效率的关键。与只能参考单向(前向或后向)的预测帧不同,B 帧最大的特点是可以同时参考序列中位于其之前和之后的两个已编码帧。如图4所示,编码器对 B 帧中的每一个块都会执行双向运动搜索:一次是向前一帧寻找最匹配的块(前向预测),另一次是向后一帧寻找最匹配的块(后向预测)。B 帧的最终预测信号并非简单地选择其中之一,而是将这两个方向上的预测块进行加权平均,以生成一个更加精确的综合预测。这种机制能够有效地处理画面中对象的遮挡、暴露或复杂的平移、旋转等运动,因为它能综合利用两个时间点的上下文信息,从而产生比单向预测更小的残差,为整个视频流带来最高的压缩增益。
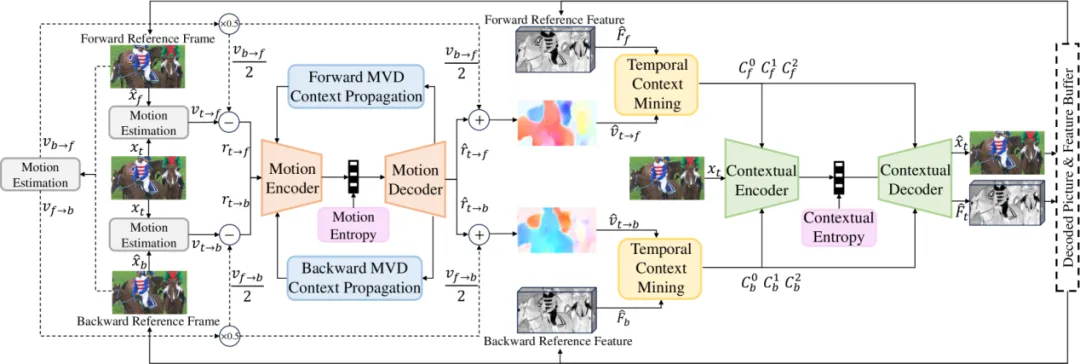
其关键技术包含以下内容:
- 双向运动估计与压缩技术,B帧的双向运动估计技术通过同时利用前后参考帧进行运动补偿,提升预测精度,但也带来了更高的运动信息编码成本。为降低码率,采用运动矢量差分编码,仅传输预测误差,并结合双向运动差分上下文传播机制,利用参考帧的运动信息作为上下文,通过可学习适配器动态融合,显著减少运动比特开销[9]。
- 双向时间上下文挖掘技术,双向时间上下文挖掘技术旨在从前向和后向参考帧中提取多尺度特征域上下文信息,替代传统的像素域预测方式。通过在多个空间分辨率下进行运动补偿并独立生成双向上下文,该方法使编码器能够灵活利用“过去”和“未来”信息,提高预测准确性,同时避免引入额外码率负担[10]。
- 双向上下文压缩模型技术,双向上下文压缩模型通过将前向与后向上下文信息注入编码器与解码器的多个层级,替代传统残差编码方式,使网络能够自主学习如何融合双向预测信息以去除冗余。该方法通常采用通道级拼接方式融合上下文,并结合非线性变换模块,有效提升压缩效率和重建质量[11]。
- 双向时间熵模型技术,双向时间熵模型通过结合前向和后向参考帧的上下文信息,构建更精确的符号概率模型。该模型从双向上下文和已解码的潜在表示中提取时间先验,并通过先验特征适配器动态生成概率分布参数,与超先验和空间上下文共同用于熵编码,显著提升压缩性能,尤其适用于高结构化视频内容[12]。
- 分层质量结构训练策略技术,分层质量结构训练策略通过为不同时间层的B帧分配差异化的质量权重,引导模型在训练过程中合理分配码率。具体做法是在损失函数中对不同层帧引入可调质量系数,并结合轻量级质量适配器对输入特征进行尺度调整,使参考帧质量更高、误差传播更小,从而提升整体GOP的率失真性能,增强模型在实际应用中的稳定性与泛化能力。
标准化进展
面对AI技术的快速发展,各大标准化组织并未选择完全推倒重来,而是积极探索如何在现有编解码框架基础上融入AI技术。这种渐进式的演进既保证了与现有生态的兼容性,又为未来的技术革新预留了空间。MPEG作为传统视频编码标准的制定者,正在探索神经网络编码工具与现有框架的融合;MPAI是一个致力于利用人工智能提升多媒体数据压缩和处理效率的国际标准化组织;AVS作为中国音视频技术标准标准化组织,在混合神经网络编码和端到端神经网络编码两个方向同步推进。
MPEG标准组织
MPEG NNVC(Neural Network-based Video Compression)基于神经网络的视频压缩描述了在 JVET(Joint Video Exploration Team) 框架下探索的神经网络编码工具,包括低复杂度、极低复杂度与高复杂度多种神经网络环路滤波器、神经网络帧内预测、内容自适应滤波、超分辨率等模块,同时给出了训练方法和推理实现细节[13]。
MPAI标准组织
MPAI-EVC( AI-Enhanced Video Coding)基于AI增加的编码标准项目旨在从MPEG-5 EVC 基线出发,通过训练神经网络编码工具并与混合框架进行联合调优,积极致力于改进增强型帧内预测(利用同一图像中的冗余)、环路滤波器(增强重建图像)和超分辨率(空间升级)技术的研究[14]。MPAI-EEV(End-to-End Video Coding)基于AI 的端到端视频编码标准项目,通过利用经过数据训练的神经编码技术来压缩表示高保真视频数据所需的比特数,这种方法不受传统混合框架中数据编码应用方式的限制。自2021年12月启动以来,MPAI-EEV 项目已发布了 5 个版本的验证模型(EEV-0.1 至 EEV-0.5),并在自然场景视频编码和无人机视频编码中都取得了显著的编码效率提升[15]。
AVS标准组织
AVS视频组的智能编码专题组,针对混合神经网络编码,建立了智能编码平台 ModAI,现在已更新至 ModAI15.0。借助ModAI平台对基于卷积神经网络的环路滤波、虚拟参考帧(帧间预测)、帧内预测、基于超分网络的空域变分辨率编码方法进行了深入研究,以替代传统码滤波器并具有更好的性能。针对端到端神经网络编码,建立了端到端智能编码探索平台EEM(End-to-end Exploration Model),现已更新到EEM8.1,借助EEM平台对上下文熵模型、光流估计网络、自适应量化策略展开深入研究以替代传统编码模式并具有更好的性能[16]。
MPEG标准组织
MPEG NNVC(Neural Network-based Video Compression)基于神经网络的视频压缩描述了在 JVET(Joint Video Exploration Team) 框架下探索的神经网络编码工具,包括低复杂度、极低复杂度与高复杂度多种神经网络环路滤波器、神经网络帧内预测、内容自适应滤波、超分辨率等模块,同时给出了训练方法和推理实现细节[13]。
MPAI标准组织
MPAI-EVC( AI-Enhanced Video Coding)基于AI增加的编码标准项目旨在从MPEG-5 EVC 基线出发,通过训练神经网络编码工具并与混合框架进行联合调优,积极致力于改进增强型帧内预测(利用同一图像中的冗余)、环路滤波器(增强重建图像)和超分辨率(空间升级)技术的研究[14]。MPAI-EEV(End-to-End Video Coding)基于AI 的端到端视频编码标准项目,通过利用经过数据训练的神经编码技术来压缩表示高保真视频数据所需的比特数,这种方法不受传统混合框架中数据编码应用方式的限制。自2021年12月启动以来,MPAI-EEV 项目已发布了 5 个版本的验证模型(EEV-0.1 至 EEV-0.5),并在自然场景视频编码和无人机视频编码中都取得了显著的编码效率提升[15]。
AVS标准组织
AVS视频组的智能编码专题组,针对混合神经网络编码,建立了智能编码平台 ModAI,现在已更新至 ModAI15.0。借助ModAI平台对基于卷积神经网络的环路滤波、虚拟参考帧(帧间预测)、帧内预测、基于超分网络的空域变分辨率编码方法进行了深入研究,以替代传统码滤波器并具有更好的性能。针对端到端神经网络编码,建立了端到端智能编码探索平台EEM(End-to-end Exploration Model),现已更新到EEM8.1,借助EEM平台对上下文熵模型、光流估计网络、自适应量化策略展开深入研究以替代传统编码模式并具有更好的性能[16]。
应用篇
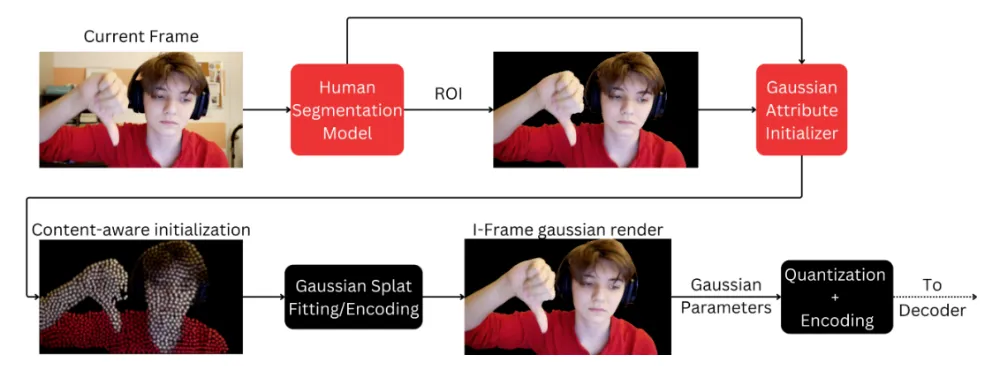
在实时视频通信(视频会议、实时流媒体)场景中,AI 编解码技术正加速落地。面对带宽敏感与超低时延等约束,传统方案往往难以同时兼顾编码效率与人像区域(人脸、手势)的感知质量,易出现码率波动、细节丢失与画质不一致。基于 2D 高斯散射的智能编码方案提供了新的实现路径:在编码侧将视频帧转换为一组高效的显式高斯参数表示,并与感兴趣区域策略联动,围绕人像主体进行内容自适应聚焦。通过内容感知初始化与选择性高斯优化,系统在保证关键区域清晰度的同时,显著减少冗余计算与传输比特开销,使在受限带宽下的人脸纹理、表情与手势动态得到更稳定的保留,提升码率利用率与感知质量一致性。这类基于 2D 高斯 的 NNVC 方案可直接集成于客户端(个人电脑或移动终端)编码模组,支持逐帧比特流传输与实时解码,在不显著增加带宽的前提下提升编码速度与端到端时延稳定性,成为化解“高计算需求—低时延要求”矛盾、支撑下一代视频会议体验的重要演进方向。
在无人机视频回传场景中,AI 编解码技术正在加速落地应用。无人机巡检、航拍、应急救援等业务中,视频链路往往面临空地信道不稳定、带宽受限、画面内容高速变化等挑战,传统压缩方案容易出现码率波动大、画质不一致、关键细节丢失的问题。基于 AI 的智能编码策略,可在编码侧实时“理解”画面特征,使系统能够根据场景复杂度、运动强度、信道带宽变化动态调整压缩目标,从而在有限的回传带宽下,更稳定地保留路况纹理、电力线、目标物边缘、地标细节等巡检关键视觉信息。这类 AI编解码方案可以直接部署在无人机机载编码模组、空地回传链路与云端解码平台中,提升视频回传的码率平稳性、抗干扰鲁棒性与感知质量稳定输出能力,降低回传断流与画质失真风险,使无人机在真实任务中实现低带宽占用下的高效可靠视频传输,成为低空视频压缩应用的重要演进方向。

在体育赛事直播中,AI 编解码技术的融合正显著提升观众体验。面对多路4K/8K信号并发、高码率+低延时+大规模多端分发的三重挑战,传统编解码往往需要在画质与带宽间妥协。AI 编解码技术通过在环路滤波、运动估计/补偿、帧内/帧间预测等关键模块引入可学习神经网络工具,更精准建模复杂时空依赖,从而降低残差能量,使码率分配更具内容与网络条件自适应能力,在不明显增加带宽的前提下保持高速运动细节与边缘清晰度,并更有效抑制抖动、模糊、块效应等伪影。这类AI编解码方案已在世界杯、亚运会、欧洲杯、世俱杯等国际重大赛事中参与应用实践,验证了其在超高清、低时延、大分发场景下的压缩效率、鲁棒性与感知质量提升能力,成为多媒体直播技术升级的重要方向。

展望篇
随着视频业务需求不断增长和 AI 技术的全面渗透,未来的视频编解码将不再局限于传统的像素压缩,而是走向智能化、语义化和可持续化的新阶段。边缘计算与智能算法的结合、大模型与编码技术的深度融合、语义驱动的差异化压缩、以及绿色低碳的可持续发展,都将构成未来编解码演进的核心方向。这些趋势不仅会重塑技术体系,也将深刻影响产业生态和标准制定,为下一代视频服务奠定基础。
边缘智能:计算与压缩的协同
随着边缘计算和智能终端的普及,未来视频编解码将更多在靠近用户的一侧完成。边缘节点不仅具备视频预处理和智能分析能力,还能够结合本地场景特征进行压缩优化,从而减少回传带宽、降低传输时延。例如,在移动直播或云游戏场景中,边缘节点可以根据实时网络条件选择合适的码率与分辨率,并结合智能预测机制减少卡顿。未来,端、边、云的协同将成为主流架构:终端侧强调实时性和个性化,边缘侧负责快速处理与适配,云端则提供全局优化与模型更新。这种分层协作模式不仅提升用户体验,也能有效降低整体能耗。
大模型与编码融合:知识驱动压缩
大模型的引入将推动视频编解码从像素压缩走向知识压缩。依托大规模多模态预训练模型,系统可以理解视频中的场景、对象与语义关系,从而以更少的比特表达更丰富的信息。在超低码率场景下,大模型甚至能够利用生成能力“补全”画面,实现少量传输、多端还原。未来有望出现专门面向视频压缩的大模型(Compression Foundation Models, CFM),它们具备跨场景自学习和迁移能力,可在分布式环境下不断优化压缩效率。同时,结合隐私保护与联邦学习,这些模型能够在保证数据安全的前提下广泛应用,开启“理解后压缩、生成式重建”的新范式。
语义驱动智能编码:场景感知压缩
未来的视频应用场景日益多样化,传统的平衡编码比特率与重建质量损失的优化方法已无法充分应对差异化需求。语义驱动的智能编码通过引入场景理解能力,使系统能够根据内容的重要性灵活分配比特。例如,在体育转播中,球员与球的区域获得更高码率,而背景观众则以较低码率处理;在视频会议中,系统会优先保证人脸区域清晰度。实现路径包括增加“语义副通道”,在传输过程中同时携带像素数据和语义标签,解码端利用标签进行条件重建。这种方式不仅显著提高码率利用率,还能实现贴合应用需求的个性化优化,是视频编码从像素层到语义层的关键跃迁。
绿色节能与可持续发展:低碳使命
在“双碳”战略和可持续发展目标的驱动下,绿色节能已成为未来视频编解码的重要使命。随着视频流量持续增长,AI 编解码需要在性能提升与能耗控制之间取得平衡。一方面,通过模型剪枝、蒸馏、量化等技术,实现神经网络的轻量化和低功耗推理;另一方面,结合能耗感知的调度机制,将任务在云、边、端之间灵活分配,最大限度降低整体碳排放。同时,未来行业有望建立统一的能效评估体系,将压缩效率、能耗和碳排放纳入综合指标,以引导产业绿色转型。绿色智能编码不仅是技术发展的必然趋势,更是视频产业承担社会责任的重要体现。
【参考资料】
[1]Dong, C., Loy, C. C., He, K., & Tang, X. (2015). Image super-resolution using deep convolutional networks. IEEE TPAMI, 38(2), 295–307.
[2]Liu, Z., Li, S., & Li, Y. (2018). CU partition mode decision for HEVC hardwired encoder using convolutional neural network. IEEE Transactions on Image Processing, 27(5), 2510–2521.
[3]Ilg, E., Mayer, N., Saikia, T., Keuper, M., Dosovitskiy, A., & Brox, T. (2017). FlowNet 2.0: Evolution of optical flow estimation with deep networks. CVPR, 2462–2470.
[4] Wang, H., Pan, X., Feng, R., Guo, Z., & Chen, Z. (2024). Conditional Neural Video Coding with Spatial-Temporal Super-Resolution. arXiv:2401.13959.
[5] AVS M8258基于超分网络的空域变分辨率编码方法探索
[6] Liu, H., Wang, Y., & Ma, S. (2020). Deep learning-based virtual reference frame generation for video coding. IEEE International Conference on Multimedia and Expo (ICME), 1–6.
[7]AVS M7995 AVS端到端视频编码参考模型EEM-v0.1.
[8] X. Sheng, L. Li, D. Liu, and S. Wang, “Bi-directional deep contextual video compression[12],” IEEE Trans. Multimedia, arXiv:2408.08604v5, Jan. 2025.
[9] Feng Ye, Li Zhang, and Chuanmin Jia. 2024. Deep Video Compression with Scaled Hierarchical Bi-directional Motion Model. In Proceedings of the 32nd ACM International Conference on Multimedia (MM ’24), October 28-November 1, 2024, Melbourne, VIC, Australia. ACM, New York, NY, USA, 4 pages.
[10] X. Sheng et al., “Temporal context mining for learned video compression[8],” IEEE Trans. Multimedia, 2022.
[11]Sheng, X., Li, L., Liu, D., & Wang, S. (2025).Bi-directional deep contextual video compression. IEEE Transactions on Multimedia, arXiv:2408.08604.
[12]Li, J., Li, B., & Lu, Y. (2023).Neural video compression with diverse contexts. In CVPR, 22063–22072
[13] ITU-T SG16 ISO/IEC JTC 1/SC29/WG5 N308 Exploration experiment on neural network-based video coding
[14] https://mpai.community/standards/mpai-evc/about-mpai-evc/
[15] https://mpai.community/standards/mpai-eev/
[16] AVS N4057 AVS端到端智能编码探索平台算法描述文档8.0
[17] L. Gupta and I. N. Junejo, “Neural Video Compression Using 2D Gaussian Splatting,” arXiv preprint arXiv:2505.09324, May 2025.
[18] Z. Lan, J. Li, Y. Zhang, and H. Liu, “Reinforcement learning-based rate control for UAV video compression,” arXiv preprint arXiv:2301.06115, 2023.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。