
在推出ChatGPT一年多后,OpenAI近日发布文生视频大模型Sora,成为龙年科技界的“第一把火”,并以惊人的速度持续发热,再次引发全球瞩目。Sora可根据用户输入的指令,生成一段长达60秒的视频,并且在保证视频时长的同时,加强了视频质量的稳定性。OpenAI官网发布的多个视频示例,均以逼真的画面令人很难区分它们是真实拍摄的,还是由AI生成。
事实上,文生视频大模型不是一条新赛道,Sora也并非是首个AI生成视频的大模型。2023年年初,视频生成模型还只能满足将多个图像拼接成几秒长的视频的需求;同年6月,Runway Gen-2已经可以生成几秒长的电影级影片;2023年11月,动画视频生成公司Pika推出了可以生成分钟级高质动画视频的产品。2024年1月,Google推出名为Lumiere 的“文生视频”扩散模型,采用自家最新开发的“Space-Time U-Net”基础架构,号称能够一次生成“完整、真实、动作连贯”的视频。
据不完全统计,在Sora发布前,全球能实现文生视频的大模型包括Runway、Pika、Stable Video Diffusion等就已超过20个,而Sora则凭借着视频长度的突破以及在细节处理、语言理解能力、视频扩展功能等方面的表现带来“史诗级颠覆”,引爆科技圈。
Sora的发布一石激起千层浪,在一片赞誉与期待之中,也引发不少业内人士的担心。加利福尼亚大学伯克利分校信息学院副院长法里德就表示:“当新闻、图像、音频、视频——任何事情都可以伪造时,那么在那个世界里,就没有什么是真实的。”国内著名媒体人胡锡进在评论Sora时,也明确提到“内容安全”的问题。
01 Sora背后的内容风险,不容小觑
AI生成的视频内容往往基于大量的文本、图片以及视频数据筛选和模型训练,本身不具备价值导向,但数据的筛选、清洗,以及不同地区的内容监管尺度差异,加上用户提问和设定条件的差异,会“诱导”AI创作出可能存在风险的内容。AI生成视频的内容风险主要包括但不限于以下几个方面:
1.深度伪造(Deepfake)风险:
由于Sora能够基于文本自动生成逼真的视频,这可能导致深度伪造内容的制作门槛大幅降低,使得伪造他人的言行变得更为容易,进而可能被用于诈骗、诽谤、色情等违法活动,破坏社会秩序,损害公民权益,甚至威胁国家安全。
2.不当或违法内容:
AI生成的视频画面可能包含恶俗、暴恐、色情或其他违反法律法规的内容。
3.伦理道德风险:
模型自主生成的内容有可能挑战人类社会的伦理道德规范,如生成涉及歧视、仇恨或者不尊重人权的内容。
4.虚假信息传播:
Sora生成的内容如果不加以有效监管和真实性验证,可能会加速错误信息、假新闻等不实内容在网络上的扩散,影响社会舆论和公众判断。
5.版权与隐私侵犯:
如果模型在未经许可的情况下使用了受版权保护的素材或者生成了涉及他人隐私权的内容,则存在法律风险。国内去年7月发布的《生成式人工智能服务管理暂行办法》(以下称“办法”)中也提前预判了AI生成视频的技术创新,只是之前AI视频技术尚未出现现象级大模型产品。《办法》原文中涉及视频内容的相关条文见如下:
第二条 利用生成式人工智能技术向中华人民共和国境内公众提供生成文本、图片,音频、视频等内容的服务(以下称生成式人工智能服务),适用本办法。第十二条 提供者应当按照《互联网信息服务深度合成管理规定》对图片、视频等生成内容进行标识第二十二条 本办法下列用语的含义是:(一)生成式人工智能技术,是指具有文本、图片、音频、视频等内容生成能力的模型及相关技术。
AIGC需要有自己的内容审核系统,这一点毋庸置疑,OpenAI也承诺,在Sora正式开放前,将采取安全措施,包括由“错误信息、仇恨内容和偏见等领域的专家”对模型进行对抗性测试来评估危害或风险;核查并拒绝包含极端暴力、性内容、仇恨图像、他人IP等文本输入提示等。但AI生成视频审核过程在技术上和成本上都面临巨大的挑战,面对此类文生视频大模型的内容审核难题,数美科技基于在内容风控领域的深厚积淀以及在AIGC领域的实践经验,升级多模态AIGC内容风控解决方案,为文生视频大模型提供内容审核支持。
02 数美科技解决方案 筛选-输入-输出全流程、多模态内容审核
与之前AI生成文字、图片等静态内容不同的是,对AI生成的动态视频内容审核不仅在技术层面更复杂,对审核的时效性和专业性要求更高,因此需要投入更多的时间、人力和技术资源,构建更加智能高效的审核系统来应对这些挑战。但整体流程是相似的,主要分为三大块:数据筛选-用户输入-内容输出,走好这关键三步,便能守住内容安全合规的底线,才能获得健康可持续的发展。
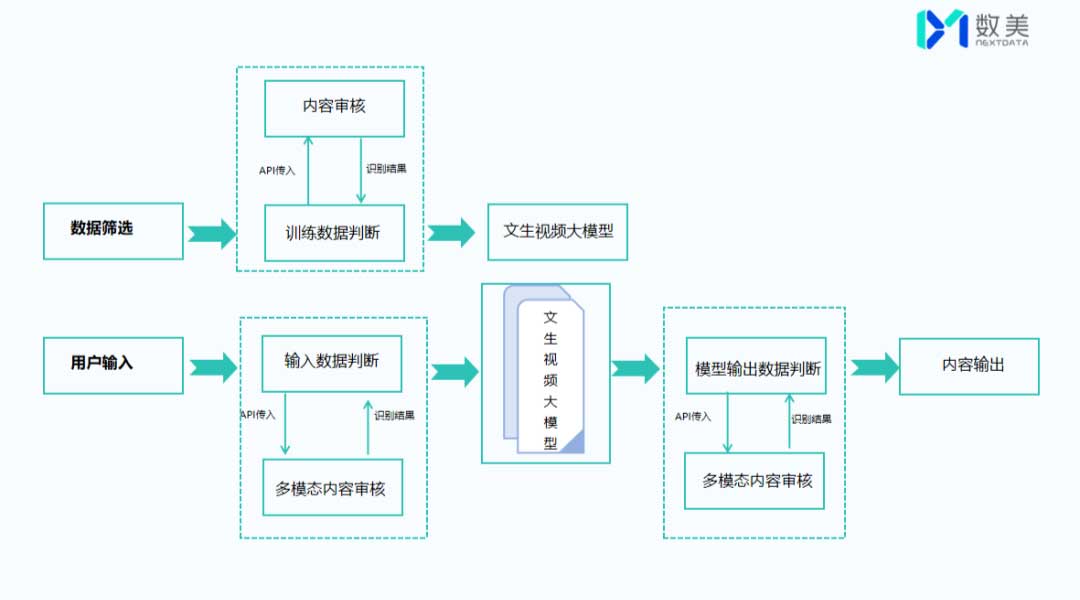

1.数据筛选
在这个阶段与之前的模型产品并没有太大区别,主要可以从筛选、清洗训练数据、内容审核来对训练数据进行三重“防护”,只是训练文生视频大模型需要大量的视频以及文本描述,因此在审核中需要调用更多资源,审核成本加大,审核技术要求更高,同时相较于静态的文字或图片,动态视频中微妙的表情变化、肢体语言等非文字信息增加了判断难度,通常需要更专业的人工与机器审核协同来确保训练数据的准确性和合规性。
2. 用户输入
从目前Sora来看,在输入阶段支持文字、图片以及视频不同模态的提示内容,这为输入阶段的审核加大了难度,面对用户输入的存在违规、敏感的内容,大模型是直接拒绝用户生成视频还是引导换话题?如何结合国家国情、各地区政策去做到更精细化的审核?数美可根据用户输入的提示内容类型采取对应的审核策略:
(1)文本内容
敏感词匹配拦截:创建敏感词或短语黑名单库,阻止AI生成涉及这些内容的文本。需要注意的是,用户输入的字词可能有同音、形近等各种变体,黑名单也要包含这些变体词库,确保违规数据的有效召回。
NLP语义模型:如短语无法通过敏感词识别,则需要依赖语义理解能力,对人物、事件、组织机构、违法违禁意图以及对语义情感倾向(辱骂诋毁,戏谑轻浮,赞扬肯定,客观中立等)进行识别判断,结合对提问者意图的分析来审核具体的提问内容,具备更好的黑数据识别泛化性。
(2)视觉内容
视觉分类识别模型:针对不同场景的视频,对视觉内容正确分类可减少视觉内容误杀,如有效区分动漫场景和真实场景中的枪支刀具,避免对动漫场景中枪支刀具的误杀。
目标检测模型:通过找到视频画面中的“目标物”,快速判断每一类目标物的属性及是否违规,提升视频内容审核的效率。
特殊场景分级标签:通过精细化的场景分级,提升视频审核的准确率和时效性。如针对血腥场景,已细化到三级标签,十多个分支标签。另外,针对某些恶意用户可能会通过采用“分段发”或者不同模态提示内容混开发的方式,绕过识别规则,这就需要系统在审核内容的时候也需要关联上下文信息。
3.生成内容
一般来说,如果训练语料的质量可靠,用户输入的提示内容也尽可能确保安全,模型生成内容的风险就相对有限和可控。但无论是文生文、文生图、图生图,还是多模态的内容,它都是强交互的内容,深度学习算法的不可解释性以及模型的不可预测性,要求模型在保障用户体验的同时,还要对生成的内容进行过滤。
03 数美科技解决方案优势 多模态覆盖、全方位检测、高实时响应
1. 360度全方位检测:基于数美音频、文本、图片审核能力,可对视频内容中的画面、声音、文字进行全方位分析过滤。
2. 高实时响应:支持视频流/视频文件审核,视频识别单帧画面可实现毫秒级迅速响应,视频文件处理实时率高,60s视频最快18s即可完成审核。
3. 覆盖类型全:支持多种视频流类型,普通流,即构流,TRTC,声网流;支持多种视频文件格式,AVI、FLV、MP4、MPG、WMV、MOV、RMVB、M3U8等。
4. 海量场景数据:数美利用在AIGC行业积淀的先发优势积累了上千亿包括AI对话、AI绘画、智能体等AIGC场景的内容数据,并且每周迭代20万+图片数据。
5. 业界最全的3级标签体系:600+视觉内容标签,并可根据AIGC最新趋势开发训练产品,支持最新内容审核需求。
6. 人机协同:人机协同全栈式内容审核方案,提升效率和准确度,人工审核确保最后一道防线。
7. 服务体系完善:定制化策略运营服务以及7*24小时的在线服务支持,case解决t+0,快速响应,保证方案落地与预期效果达成。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。