
本文分享了来自北京大学马思伟教授课题组的工作《Conceptual Compression via Deep Structure and Texture Synthesis》。该论文提出了一种新颖的概念压缩框架,将视觉数据编码为紧凑的结构表示和纹理表示,然后以深度合成方式解码,旨在实现更好的视觉重建质量,灵活的内容操作以及对视觉任务的支持。针对该框架设计了相应的编码方案与生成网络(HF-GAN),实验证明了所提框架能够使用极低比特率实现更高的主观重建质量,以及对内容编辑与分析任务的支持。该工作已被TIP期刊接收。

引言
研究表明,人类视觉系统(HVS)通过将信息处理并整合成抽象的高级概念(例如,结构,纹理,语义)中来感知视觉内容,这些概念构成了后续认知过程的基础。从机器视觉的实际应用中,高级视觉概念也比信号级像素起着更重要的作用。现有的压缩方法,包括传统的基于块的压缩方法和基于深度学习的端到端编码方法,主要集中在信号级冗余的建模和消除上,而通过将视觉分解建模来完成压缩任务的潜能尚待挖掘。而现有的关于概念压缩的研究[1]试图用一个潜在的向量捕获图像内容,将不同的概念组成部分混合在一起表示,导致获得的概念表示不具有可解释性和可编辑性,限制了其在下游图像处理和机器视觉任务上的潜力。
方法简介
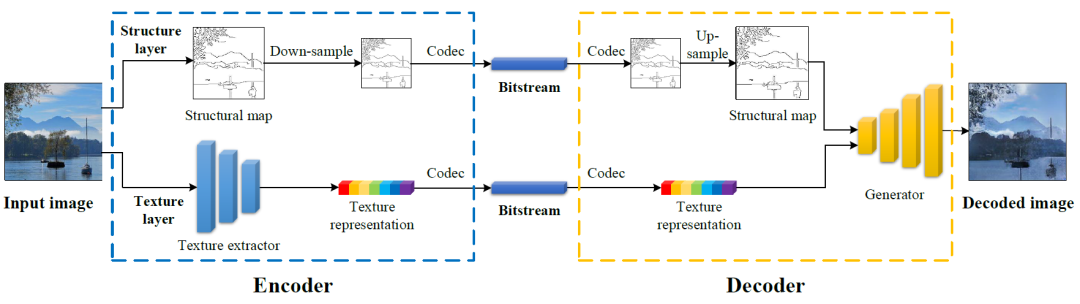
在编码端,本文通过边缘检测方法,提取边缘图作为结构层表示。考虑到结构图的稀疏性和二值化,我们采用下采样算法,进一步减小了结构层的数据量,并使用屏幕内容编码(SCC)将结构层编码为比特流。在解码端则需要反转上述过程来恢复结构图。为了重新获得原始分辨率的结构图,我们使用了超分辨率模型DBPN[2]对解码的低分辨率结构图进行上采样。DBPN模型中使用的MSE损失对稀疏二进制数据的波动不敏感,导致重建边缘的显著失真。为了提高以稀疏和二元边为特征的边缘图像的超分质量,本文采用二元交叉熵(BCE)损失训练DBPN模型。
图像纹理提取器则基于变分自动编码器设计,由几个残差块和卷积层构成,它将输入图像I建模为后验多元高斯分布, 纹理表示从后验分布中使用重参方法采样得到。随后通过标量量化和熵编码进一步压缩提取的纹理离散表示。
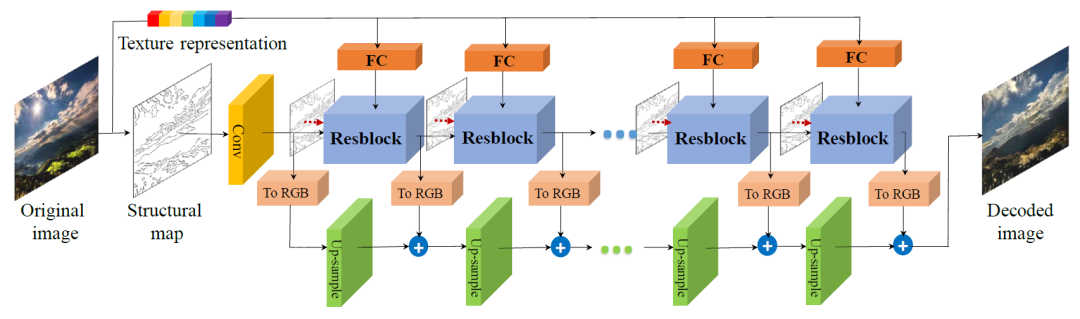
在图像合成方面,本文设计的生成器如下图所示,逐步提高合成特征图的分辨率。生成器由残差块组成,并含有跳层连接和分层融合。每个残差块包括三个全卷积层。结构图作为每个残差块的新输入连接到特征图。最后,通过将不同分辨率的RGB上采样并求和来获得目标图像。
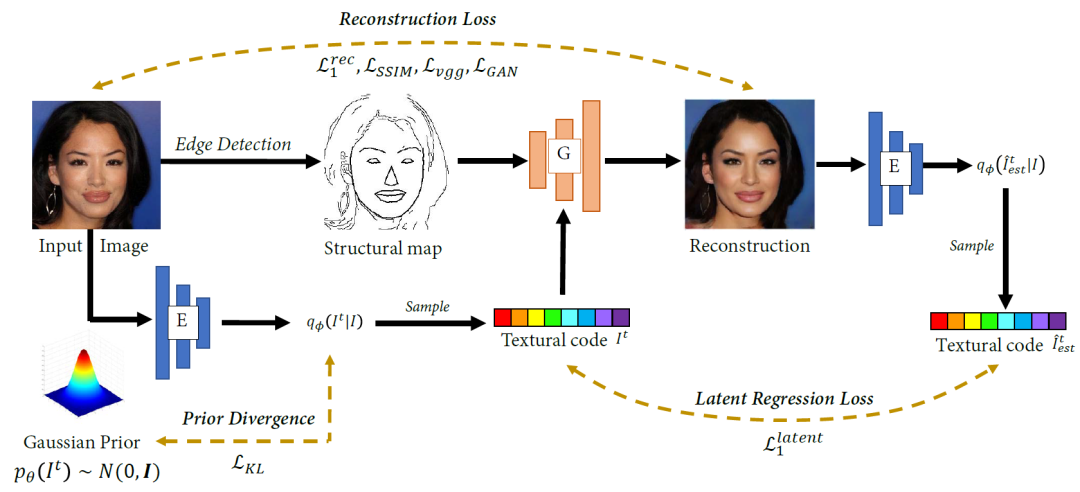
在目标函数上,纹理编码器与图像生成器引入一个多尺度判别器以端到端方式进行联合训练。如图3所示,图像压缩和重建任务主要针对三种类型的损失进行优化:1)旨在提高重建视觉质量和保真度的重建损失,包括像素损失、感知损失和对抗损失等不同层次的失真约束; 2)为纹理表示提供先验分布约束的KL散度;3)以及约束隐空间与合成纹理内容的回归损失。
实验
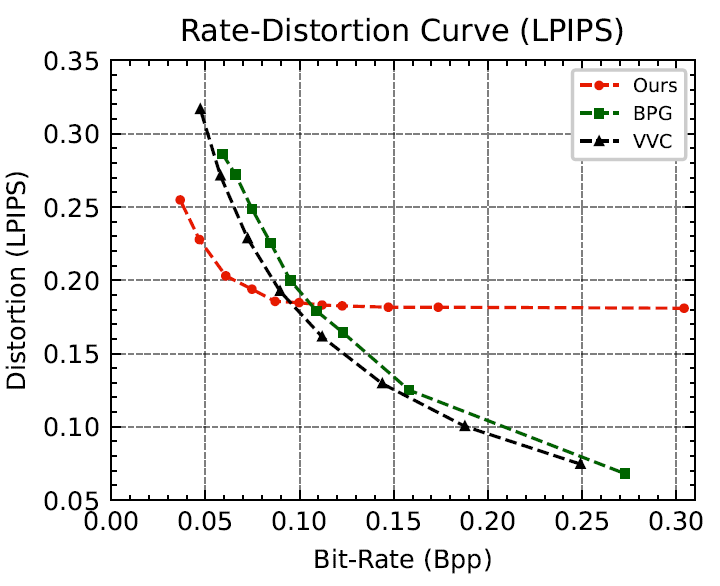
本文在三个内容特性不同的数据集上进行实验,测试所提框架的可行性,包括单目标图像edges2shoes&edges2handbags,人脸数据集CelebA-HQ和收集的以季节为主的自然场景数据集。所有图像的分辨率都调整为256×256。本项工作与八种最先进方法进行了比较,涵盖了经典的图像编码格式JPEG、JPEG2000、BPG、视频编码标准VVC (VTM参考软件),主观优化的VVC(VTM+QPA),以及多个神经网络图像压缩模型,定量感知质量评估指标采用LPIPS与DISTS。实验结果展示本文方法能在极低码率条件(<0.1 bpp)下实现比其他方法更高的视觉重建质量。除此之外,我们还在解码图像的特征点检测实验中验证了所提方法在图像分析任务中的优势。
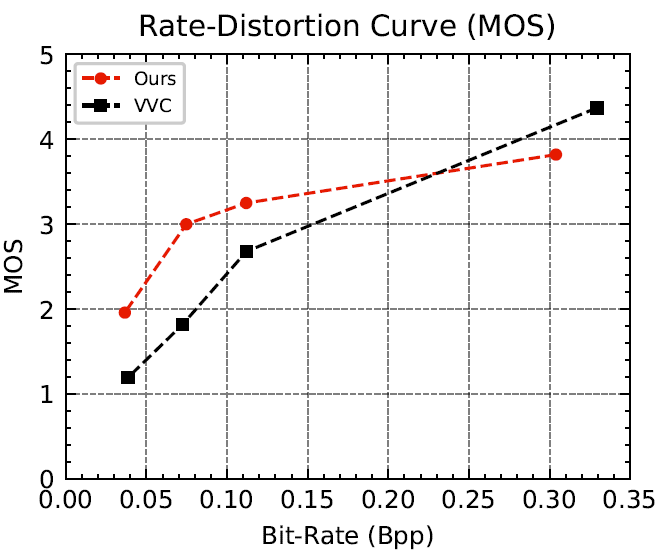
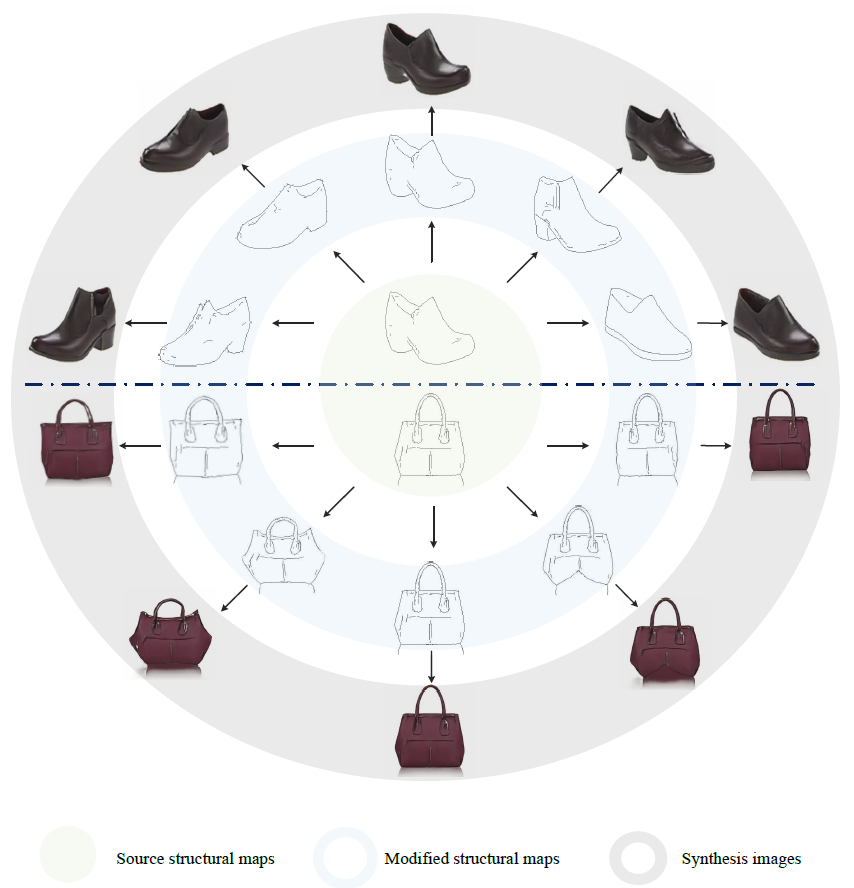
特别地,在提出的概念压缩框架中,图像被明确地分离到结构域和纹理域,并在解码端合成目标图像。结构和纹理表示既充当原始帧数据,又充当可编辑的视觉特征。得益于视觉组件的解耦和合成范式的学习,生成器能够按照任意结构图的逐步渲染给定纹理。因此,除了高效压缩外,所提出的框架还可以通过编辑结构和纹理表示应用于图像处理任务。
讨论
与基于信号变换的传统编码和端到端编码不同,目前本文所提出的框架的实现依赖深度生成模型,以数据驱动的方式捕获训练数据域的纹理分布,学习图像纹理表示。因此,纹理表示可以在具有与训练域相似分布的图像上进行推广。然而,受训练集的影响,当应用于语义差距较大的数据集时,原模型可能无法生成预期纹理。因此提高模型泛化能力具有相当大的意义,在这方面仍有许多工作要做。一方面,我们可以基于域泛化算法提高模型泛化能力,从而可以有效地压缩来自不同目标域的数据。另一方面,我们也可以将来自不同内容域的模型集成为更通用的编解码器,在应用时将需要压缩的图像分类到特定的域中,然后选择相应的模型进行压缩。比特流由图像的结构纹理表示以及编解码器子模型索引组成,从而有效地解码图像。
更多的方法及实验分析与讨论的细节请参考原文。论文地址为:https://ieeexplore.ieee.org/document/9738839。
参考文献:
[1] Karol Gregor, Frederic Besse, Danilo Jimenez Rezende, Ivo Danihelka, and Daan Wierstra, “Towards conceptual compression,” in Advances in Neural Information Processing Systems (NIPS), 2016, pp. 3549–3557.
[2] Muhammad Haris, Gregory Shakhnarovich, and Norimichi Ukita, “Deep back-projection networks for super-resolution,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 1664–1673.
来源公众号:PKUVCL
北京大学视频与视觉技术国家工程研究中心视频编码算法与标准研究室(PKUVCL)长期致力于我国AVS视频编码标准制定及智能视频压缩前沿技术探索,积极推动AVS3开源平台和产业化建设,为AVS3标准技术支撑的5G、8K超高清深化应用提供更高效的助力。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。