
1.背景
随着B站业务的高速发展,业务产生的数据每天以PB级的速度持续增长,之前主要应对方法是分析数据的使用频率,把数据分为热冷俩类数据,对冷数据进行高密存储来降低存储成本,以及对部分非核心的冷数据进行数据周期管理。随着体量的增大,即使TTL机制的运行,冷数据的存储量也越来越多,这部分数据长时间未有访问,但仍然具有一定的价值,不能随意清理,且占总体数据量的30%以上,现有的高密存储机制虽然能一定程度上降低存储成本,但是为了进一步的降本增效,我们计划用技术手段进一步节省存储成本。
目前社区针对降低存储容量的手段主要就是EC策略,我们为此推动了HDFS EC在B站存储上进行实践。
EC是什么?Erasure Code(EC),即纠删码,是一种前向错误纠正技术(Forward Error Correction,FEC),是一种可通过计算降存储的技术,相比多副本复制而言, 纠删码能够以更小的数据冗余度获得更高数据可靠性,但编码方式较复杂,需要大量计算。纠删码只能容忍数据丢失,无法容忍数据篡改,纠删码正是得名与此。Erasure Code可以将n份原始数据,增加m份数据,并能通过n+m份中的任意n份数据,还原为原始数据。即如果有任意小于等于m份的数据失效,仍然能通过剩下的数据还原出来。
就B站目前存储的情况来看,Erasure Code能有效减少HDFS存储空间,一个 256MB 的文件按三副本方式存储,需要在不同 DN 上存放 3 份完整的数据块,消耗768M的空间,如果采用RS-6-3-1024k策略只需要384M,能降低50%的存储,非常有利于实现降本增效的大目标。
2.HDFS EC整体方案
2.1 面临的问题
HDFS在 3.0 版本中发布了EC的重要特性,而我们当前是基于社区2.8.4版本,来构建B站的大数据生态,推动HDFS存储支持EC存储策略我们面临一定的挑战。主要有以下问题:
- HDFS集群版本较低,不兼容EC。目前B站基于社区2.8.4版本,而HDFS 3.0版本为了支持EC做了大量的修改,底层接口也发生了很大变化,而我们也在社区2.8.4版本的基础上做了很多修改,如果将现有的集群版本从2.8.4升级到3.x,不仅升级过程复杂,而且升级带来的开发工作也非常巨大,我们需要在这个版本上进行取舍。
- 用户使用的HDFS Client使用较杂乱,还有C++等版本的Client,难以兼容而且还会给后续的开发。目前B站使用的HDFS Client主要有和集群版本一致的2.8.4版本,presto使用的3.2版本,还有部分用户使用的C++版本,相对较为复杂,统一使用版本从短期来看不太可能,为了尽快推动EC上线,缓解存储压力,我们需要支持部分非标的Client读取EC数据。
2.2 设计选型
如上所述,推动HDFS EC策略在B站使用的主要矛盾是在于2.8.4版本的HDFS 集群无法支持EC存储策略,各种版本的HDFS Client无法支持读写EC存储策略,解决该主要矛盾面临的核心问题是如何使得HDFS存储集群和HDFS Client均能支持EC存储策略,读取EC数据。带着上面的核心问题,我们调研了业界大厂的EC存储策略解决方案,主要集中在集群升级为3.x版本以上(京东,快手等),相对代价较大耗时较久,考虑到我们已经引入了RBF,支持多个集群之间进行数据迁移和数据读写,因此我们结合社区的Hadoop 3.3 版本实现了B站自身的HDFS EC策略实现方案,如图2-1所示。
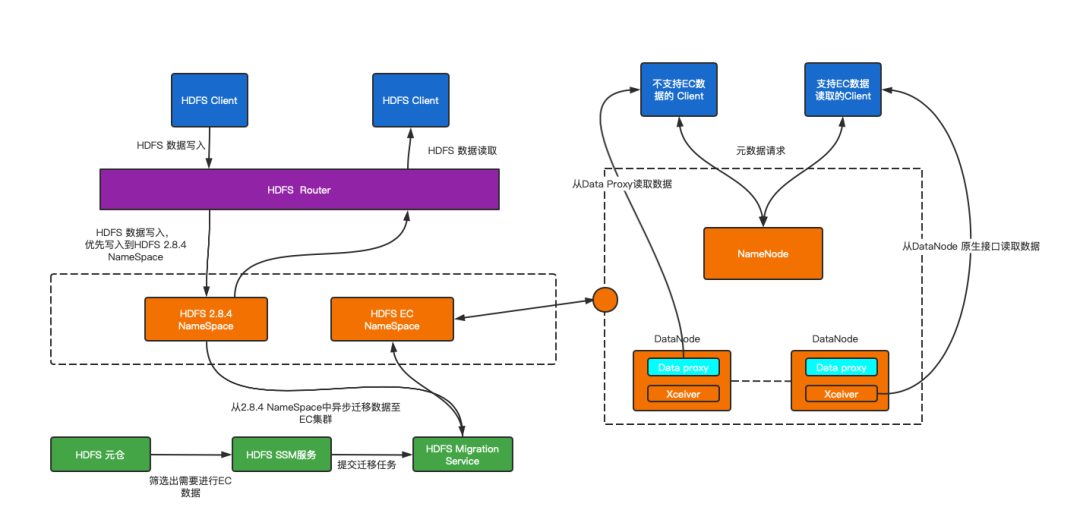

图2-1 HDFS EC转换总体架构
- Hadoop HDFS 3.3 原生支持EC数据读写,我们backport 之前在2.8.4版本上进行部分改动,部署了3.x版本的HDFS集群;
- HDFS Router 新增EC挂载点,支持新增数据写入2.8.4集群,历史数据进行EC转换,存放在3.3版本的HDFS集群中;
- 2.8.4 版本的HDFS Client 合并 EC相关Patch ,支持对EC数据的读写操作;
- 开发EC Data Proxy 服务,兼容老版本HDFS Client 以及C++ 等Client 读取EC数据;
- 构建HDFS Block Checker机制,确保EC数据的可靠性;
- 构建智能EC冷备策略,从元仓中筛选出可EC的数据,推动EC数据转换。
2.3 总体流程
图2-2展示我们在推动B站 HDFS EC 策略落地的总体流程,我们部署了3.3版本的EC集群,在RBF侧改造了挂载点支持EC数据转换对用户透明,改造了2.8.4版本的HDFS Client支持EC数据读写,落地了DataProxyServer服务用于野生客户端,推动智能EC转换工具的实现,协调各个部门推进大量的冷数据转换为EC存储。
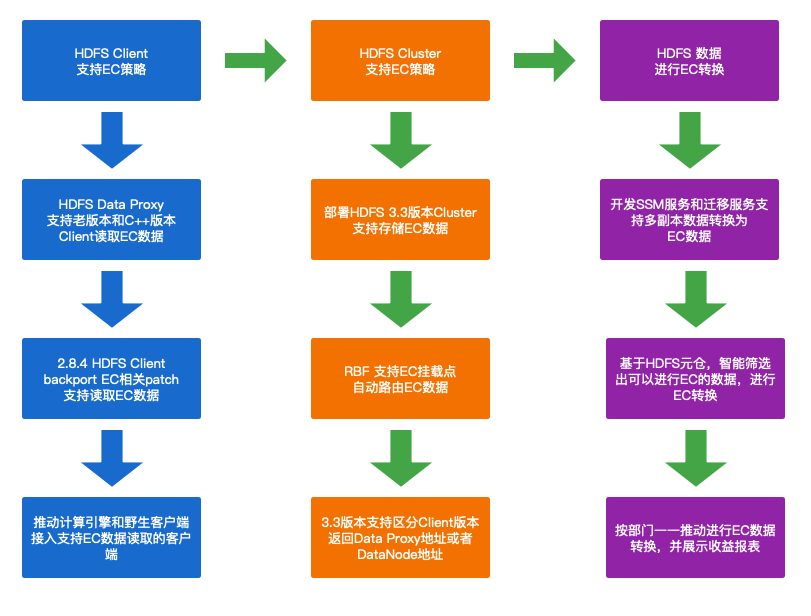
图2-2 HDFS EC实践总体流程
3.HDFS EC方案实现
下面章节会对HDFS EC方案的整体实现环节进行介绍, 包括Data Proxy,智能数据路由服务,HDFS EC Block Checker,智能EC数据转换服务。
3.1 DN Proxy实现
在B站使用HDFS存储服务的相关业务中,除了标准的Java 客户端外,还有C++,Python的客户端,由于低版本的HDFS Client 和 C++等客户端并不兼容读取EC数据,而推动业务升级非管控的野生客户端非常费时费力,还极有可能出现无法兼容的场景(如修改C++的client支持EC数据,工作量巨大收益极小),但如果不兼容这类客户端的数据读取便无法做到对上层业务透明,为了确保整个数据EC迁移的过程对上层业务透明,减少迁移的阻力,我们调研了业界的相关方案,自研实现了Data Proxy 服务,支持2.8.4版本HDFS pb协议的所有客户端都能读取EC数据。
以下简单介绍一下Data Proxy服务,如图3-1所示:
- 首先在2.8.4版本的HDFS Client 的基础上,移植EC数据读写的相关Patch,支持读取EC数据,同时配置HDFS Client对NameNode的访问通过CallerContext透传Client Version信息,并约定某个版本之后的Client 支持读取EC数据;
- 其次,EC集群的NameNode 对访问EC数据的Client验证版本信息,对低于设定版本的Client和未设定版本的Client(如C++版本的HDFS Client)返回Data Proxy端口,让其访问Data Proxy Server,对高于设定版本的HDFS Client (已经知道EC数据读取的Client)返回 DataNode Xceiver 端口,正常访问EC数据;
- 我们在3.3 版本HDFS DataNode服务基础上,仿照DataXceiver实现了ErasureCodingDataXceiver新增单独端口用于转化EC数据,当使用Replication-Based Data Transfer Protocol 协议支持低版本Client 请求时,Data Proxy服务根据请求信息读取多个DN的EC数据,聚合后按照Replication-Based Data Transfer Protocol 协议返回Client对应的数据流。
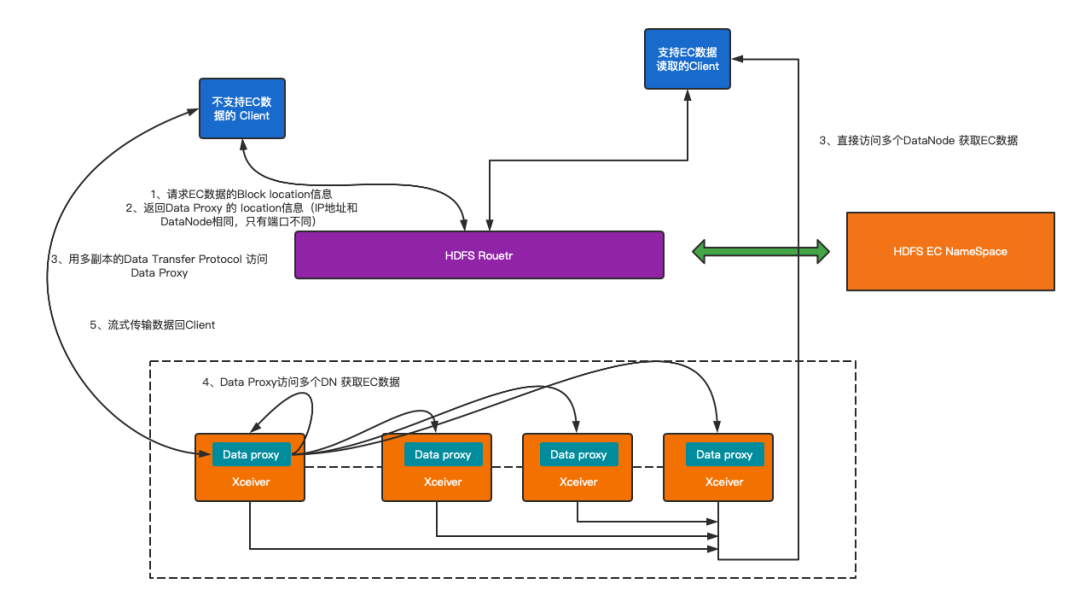
图3-1 Data Proxy 总体架构
3.2 智能数据路由体系
在之前的工作中,我们已经推动HDFS Client接入HDFS DFSRouter服务来访问后端多达20组的NameSpace,当前用户数据访问99.9% 通过RBF透传到后端的HDFS,因此我们在RBF侧配置智能数据路由体系,支持用户透明访问EC数据,同时方便我们进行EC数据转换,如图3-2所示。
- 在社区版本的HDFS Router 基础上,定制化开发EC挂载点类型支持EC数据迁移,该挂载点支持一个挂载点配置多个NameSpace,新写入数据会按规则路由到最靠前的HOT的NameSpace中,但历史数据和EC数据仍然可见,通过这种方式,我们能确保数据读取的一致性;
- 建设了EC迁移工具,能在业务低峰时期自动化的异步迁移多副本的冷数据到支持EC的NameSpace中,将冷数据转换成EC存储,节省存储空间;
- 基于HDFS元仓,不断分析出需要转换的EC数据,用于指导哪些数据需要迁移。
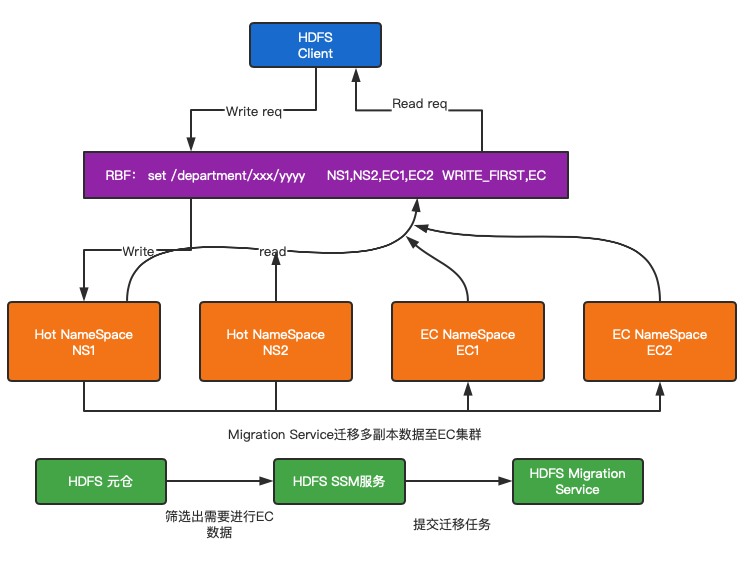
图3-2 智能数据路由服务
3.3 Block Checker
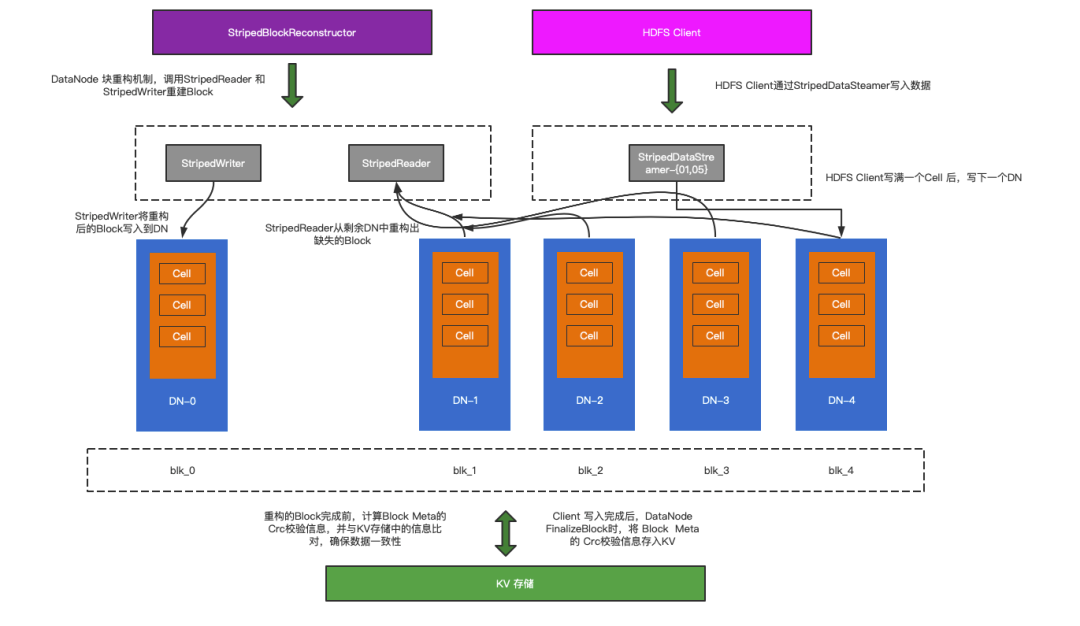
HDFS EC存储策略,采用编码的方式对数据进行拆分,在B站的实践中,主要采用了RS6-3的编码方式,将一个Block拆分成9个副本进行存储,其中包括6个数据块和3个校验块,损失3个副本内都能通过设定的算法重构丢失的副本,但同行的经验和HDFS EC的发展过程中都曾经出现过因某些原因导致数据损坏的场景出现,一旦发生数据块的数据错误,而无法及时发现,导致下游数据错乱,将会造成更大的影响,为了确保数据的准确性和完整性,我们自研的HDFS BlockChecker 组件(图3-3),确保EC数据的每个Block在重建后数据的准确性。
- 由HDFS EC数据的写入原理上来看,每个写入的Block存在真实数据和meta信息,meta信息记录了Block真实数据的校验信息,每512字节生成1个字节的校验信息,HDFS 本身的checksum机制就是读取block的meta信息进行校验;
- HDFS DataNode在接收Block副本写入完成后,会进行finalizeBlock操作,此时,我们获取副本meta信息的 Crc 校验值,存储到kv存储服务中;
- 当HDFS进行数据重构时,DataNode 收到来自 Namenode 的重建命令,从满足重构要求的最少DN节点读取数据,根据获取的数据通过算法解码出目标DN的数据,将数据以packet为单位传输至目标DN,在这个过程中,我们通过ComposedCrc 计算每个packet的checksum信息,最后当数据块传输完成后,我们可以获得这个重构副本的meta信息的crc校验值,我们将这个校验值和kv存储中的校验值进行对比,确保数据的准确性。
3.4 智能EC冷备策略
在上线EC策略过程中,我们在完成了基础的EC实现方案上线后,如何推动用户配置EC策略就成了我们日常运营的一部分工作。当前我们的 HDFS集群上存储着分区表、无分区表和非表结构的数据,我们初期只针对有分区表进行EC存储策略转换,按照分区级别的力度进行转换。实践过程中我们发现,推动用户按表级别配置EC策略相对困难,且非常耗费人力且成效不足,为此我们在支持用户配置表级别的EC转换策略的基础上,实现了智能EC的筛选策略,配合HDFS元仓,筛选出我们定义为冷数据的数据进行EC转换。
我们定义的冷数据主要由以下几点特性:
- 分区路径下所有文件距今未修改的天数 < 冷备期限 ;
- 最近x天表分区的 cmd= ‘OPEN’ 操作次数 < EC冷存阈值;
- 最近x天表分区被查询引擎读取的次数 < EC冷存阈值;
在制定出需要进行EC的规则后,我们实现了如下图所示的EC转换流程。
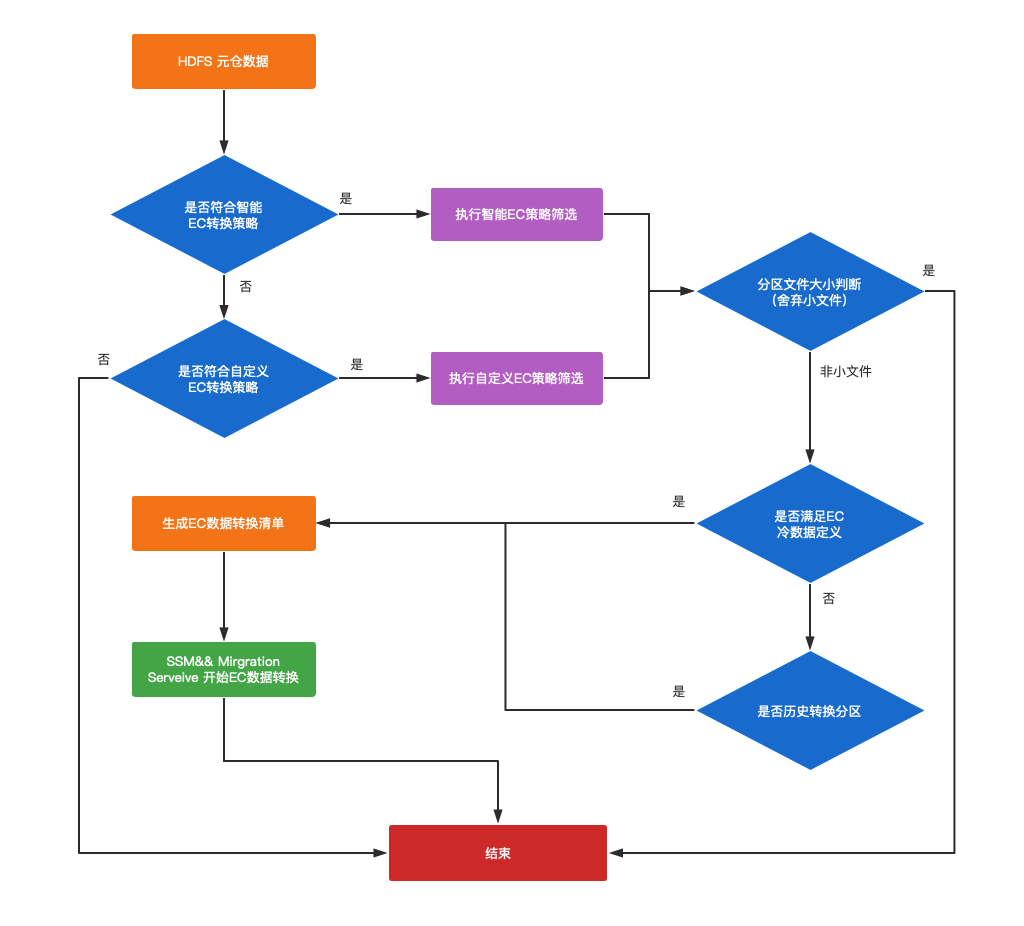
图3-4 分区冷备流程图
- HDFS 元仓记录了表分区的冷备标识,读写次数、数据年龄、冷备期限等信息;
- 根据用户选择 自定义冷备(用户指定) OR “智能冷备”(由管理员负责按策略冷备),依据不同的冷备参数(EC冷备期限,EC冷存阈值)筛选出需要进行冷存的表;
- 判断分区下平均文件大小,过滤文件Size小于3M的文件的分区;
- 由于其他数据治理服务会影响已经转成EC的数据(如zstd转表任务、z-order重组织任务会重写EC数据为多副本数据;数据迁移服务,回刷任务等会破坏数据年龄的判定条件等),我们会根据历史数据是否满足EC冷存条件将这类分区重新进行EC转换;
- 对于满足冷分区的定义的分区最终会由EC转换服务进行EC转换。
4.总结与展望
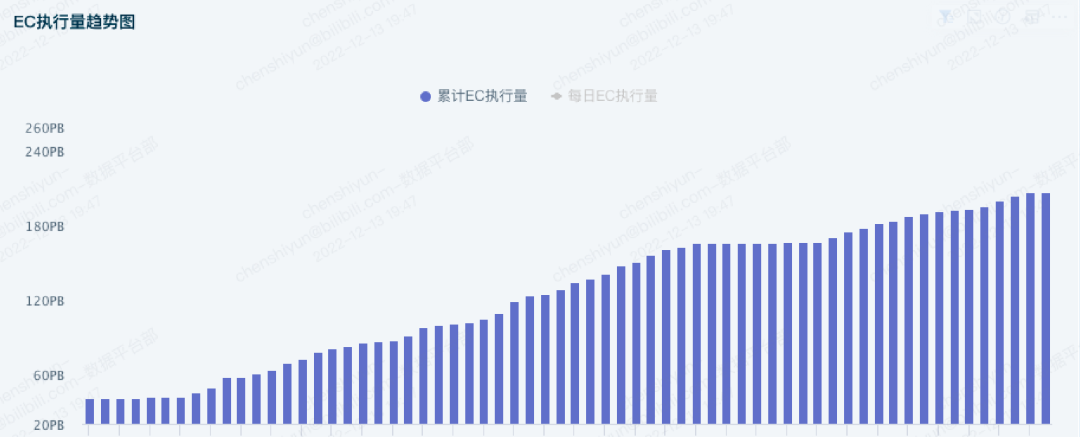
经过上述EC相关策略和工具的不断落地,我们的EC功能已经在生产环境下运行了不短的时间,已经将大量的数据进行EC转换,迄今为止,存储了上百PB的数据(如图4-1所示),为公司节省了上千台服务器成本。从当前的结果来看该方案能有效降低HDFS存储成本,但较之前的多副本存储相比,EC存储也有一定的不足之处,如写性能损失,小文件不适合进行EC转换,EC集群DataNode节点上块数量的暴增等,但相信随着技术的发展,EC技术也会不断进步。
随着EC集群数据量的不断增长,在接下来的时间里,我们也将推动使用 native 方法加速 EC 数据的编解码效率,同时提升EC功能的稳定性,向社区回馈我们的改造,与社区一起努力建设更加稳定,更加效率的HDFS存储系统。
作者:陈世云——哔哩哔哩资深开发工程师
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。