
Ring all-reduce算法被广泛应用在分布式机器学习之中,其同步过程会受到慢节点的影响进而降低整个系统的效率。对Ring all-reduce中的Reduce_Scatter和Allgather 2个阶段进行分析,针对Reduce_Scatter数据汇总过程提出优化策略,其主要思想是将慢节点多出的计算时间与通信时间进行重叠。使用OMNet++对Ring all-reduce和优化策略进行对比仿真,仿真结果与理论分析相一致,该策略相比Ring all-reduce算法最高能缩短25.3%的训练时间。
01 概述
近些年随着互联网的蓬勃发展及大数据技术的不断演进,在图像识别、语言翻译、自动驾驶等相关领域,机器学习取得了众多突破并被广泛成功应用。在进行机器学习训练时,通常需要大量的数据用于计算,以保证模型的准确性。在海量数据的背景下,训练所使用的数据集的规模越来越大,训练的模型越来越复杂,单个机器无法满足存储与算力的需求,分布式机器学习将是未来发展的必然趋势。分布式机器学习需要快速、高效的连接网络作为支撑,该网络结构有2种主要的并行方式:数据并行与模型并行。数据并行是最为常见的并行模式,广泛应用于大规模分布式系统中。在采用数据并行的方式进行训练时,各个机器之间需要对大量的数据进行同步,例如GPT-3就拥有超过1 750亿个机器学习参数。通信时间在训练时间中占比较大,如何减少通信开销成为了热门课题。数据并行使用all-reduce操作进行梯度同步,其中Ring all-reduce算法在高性能计算领域得到广泛应用。
Ring all-reduce基于同步通信,在计算节点的性能存在差异时,整体的计算性能会被较慢的计算节点拖慢。为解决同步通信的这一弊端,异步并行(ASP)与延迟同步并行(SSP)被相继提出,但Ring all-reduce架构难以支持ASP和SSP等模型的一致性协议。本文进一步分析Ring all-reduce算法特性,提出一种对其同步参数的过程进行加速的优化方案,降低慢节点带来的影响。
02 优化策略及理论分析
2.1 Ring all-reduce基本分析
百度在2017年提出将Ring all-reduce架构引入到分布式机器学习中来,使这个架构受到广泛关注。
Ring all-reduce算法分为2个部分:Reduce_Scatter和Allgather。Reduce_Scatter阶段按照n个训练节点数将数据划分为n个chunk,将从上一相邻节点接收到的chunk同本地chunk进行reduce操作并发,该阶段包含n-1个步骤,如图1所示。Allgather阶段是将汇总后的梯度段依次传递,用接收到的内容替换本地内容,该阶段包含n-1个步骤(见图2)。
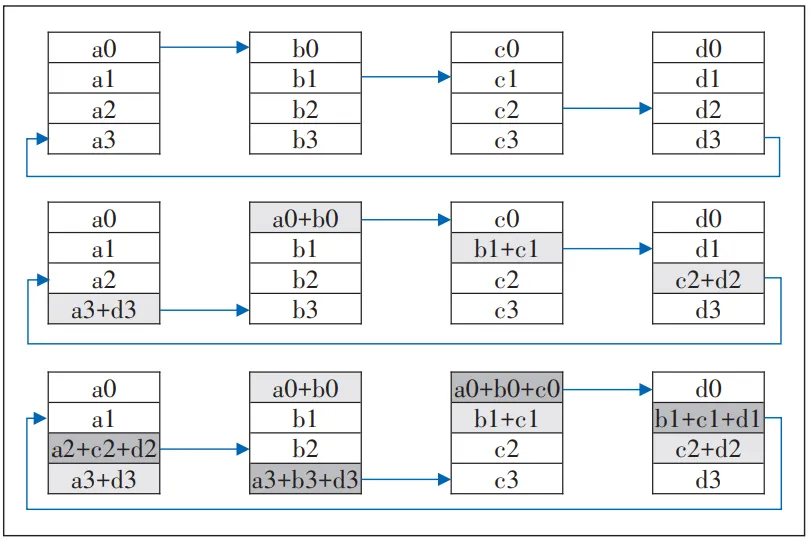

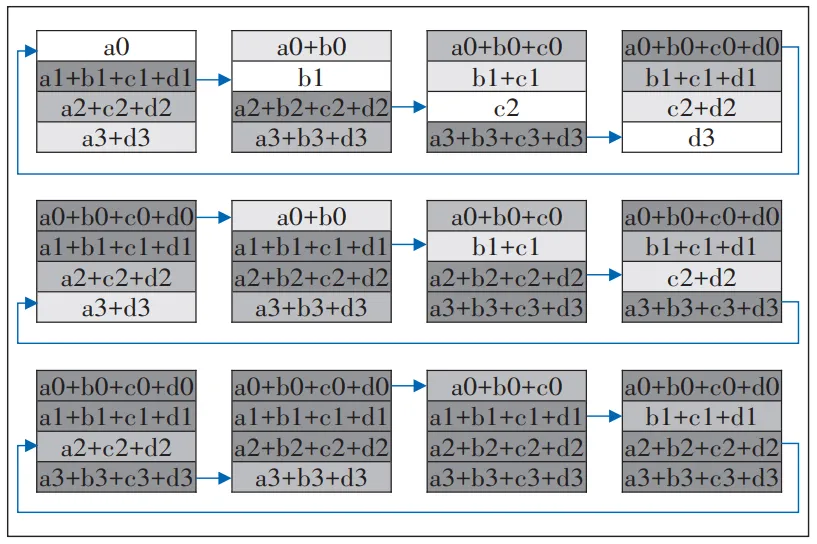
在Github上百度公开给出名为baidu-allreduce的小型c++库,具体演示了环形的all-reduce与Allgather过程。Ring all-reduce的同步过程体现在进行reduce时,调用了同步CUDA流(cudaStreamSynchronize)来等待所有GPU都完成操作。reduce操作执行完毕也就意味着完成了一轮同步过程,随后向后一个节点进行发送操作。
当某个节点的reduce阶段所用时间显著变长,即该节点为慢节点时,若按照Ring all-reduce过程进行同步,则需要等慢节点多产生的时间,而这多出的时间将直接加在Ring all-reduce原有的时间开销上,影响到Ring all-reduce算法的执行效率。为了减轻慢节点带来的负面影响,如何利用慢节点较正常节点多出来的时间便成为了关键,下文给出一种优化策略思路。
2.2 优化策略
以4节点为例对Ring all-reduce的Reduce_Scatter阶段进行分析。设置TRS为节点接收数据、进行reduce操作和发送数据的时间,Ttrans为传输数据的时间。A节点将a0发送至B节点,B节点将收到的a0与本地的b0进行汇总,并在下一次通信时将汇总的内容发送至C节点(见图3)。在这一时期,B节点因reduce过程缓慢而成为慢节点,TRS变长,C节点需要等待的TRS+Ttrans时间也随之变长,将导致训练效率下降。

本文提出一种优化策略,设置T表示在没有慢节点情况下的TRS的平均值,则Reduce_Scatter阶段1个步骤的实际开销TRS=T+△T,其中△T为因外在因素导致的时间波动;αT为节点触发策略的时间阈值,α>1。当出现慢节点时,△T变大;当TRS=T+△T>αT时,则触发策略,具体过程如图4所示。

假设B节点是慢节点,Tt为C节点等待时间。当TRS=T+△T>Tt=αT+Ttrans时,改变C节点的操作步骤。此时C节点将不再等待接收B节点发送的a0+b0,而是直接将本地的c0发送至d0;B节点达到TRS时将跳过C节点直接与D节点进行通信。为了更直观地分析时间上的重叠,假设如下。
a)各个结点之间传输数据的时间Ttrans都一致。
b)若节点为慢节点,其TRS=T+△T且△T>0。
c)若节点为非慢节点,其TRS=T。
d)设定B节点为慢节点。
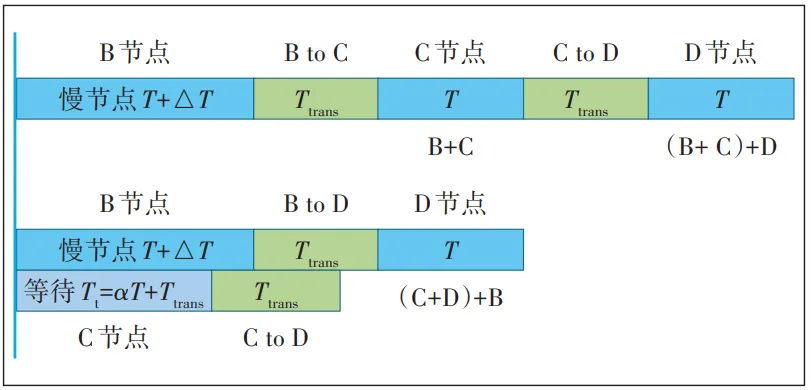
如图5所示,当B节点是慢节点且C节点等待至αT+Ttrans时,C节点直接向D节点传递数据,D节点先收到来自C节点的数据并等待B节点发送来的数据。在收到2份数据后,D节点一并进行汇总。截至D节点汇总所有数据时,策略带来的时间减少值如式(1)所示。
Tdec=T+∆T+2Ttrans+2T−(T+∆T+Ttrans+T)=Ttrans+T(1)
由式(1)可知,当△T较大时,在T+△T>αT+Ttrans情况下策略带来的时间减少值为固定时间。
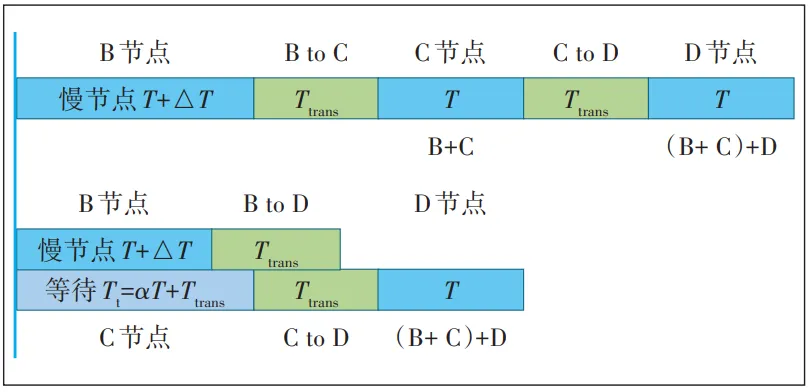
如图6所示,当TRS=T+△T<Tt=αt+Ttrans时,慢节点b发送的消息先到,等到c节点发送的数据到达后,d节点一并进行汇总。此时策略带来的时间减少值为:
Tdec=T+∆T+2Ttrans+2T−(αT+2Ttrans+T)=∆T+(2−α)T (2)
当△T与α取合适的值时,可以使Tdec取得一个较大值,即在有慢节点的情况下能减轻慢节点带来的负面影响,达到优化效果。
03 仿真实验设置及结果分析
采用OMNet++框架对Ring all-reduce算法和改进策略进行模拟。因为Allgather阶段这2种方式的开销相同,故仅比较2种方式完成Reduce_Scatter所用的时间(分别是TRing和TStrategy)。基于第2.2节做出的基本假设,对相关的仿真参数进行设定:T=3μs;Ttrans为固定链路时延5μs与数据包传递时间之和;数据包大小取8 KB;链路带宽为100 Gbit/s。设置不同的△T与α的值,优化效果即Tdec与TRing的比值。
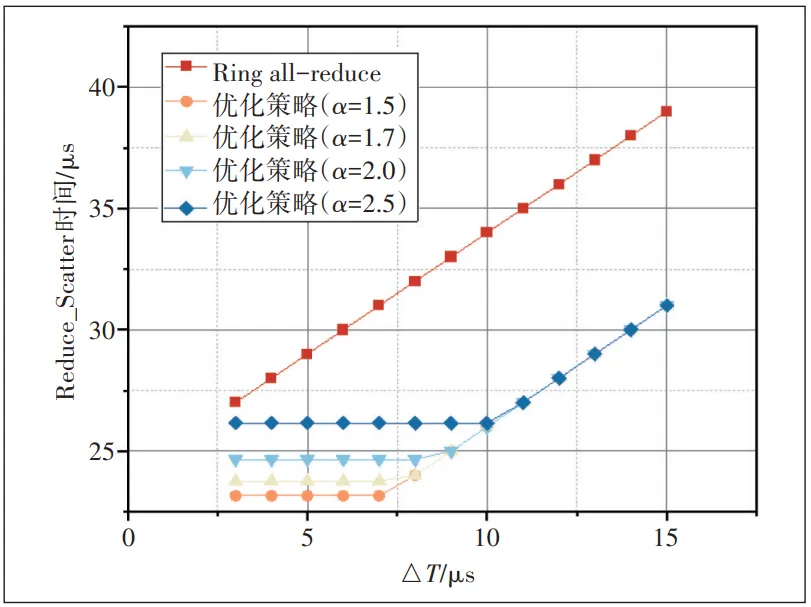
如图7所示,Ring all-reduce算法完成Reduce_Scatter阶段所用时间随着△T的增加而线性增加,而采用优化策略完成Reduce_Scatter阶段所用时间均得到减少,说明采取优化策略能减少时间开销。
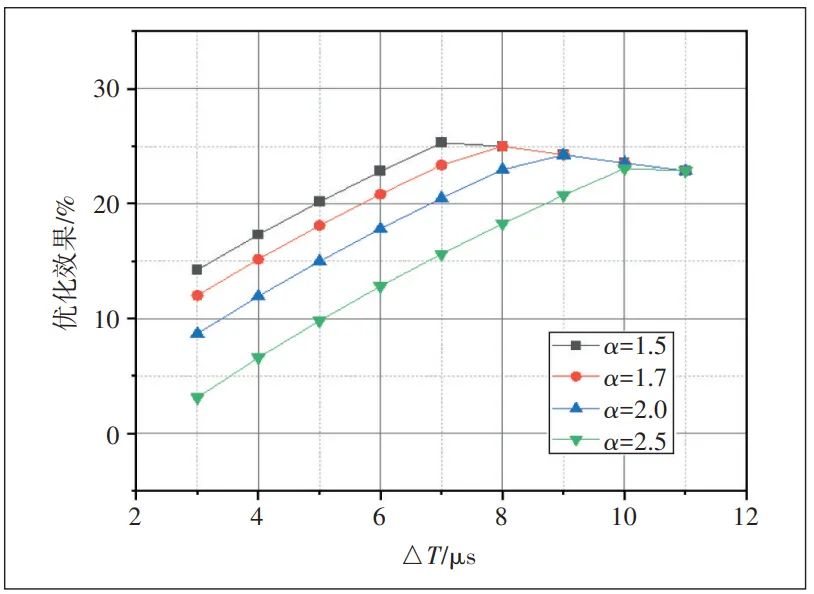
进一步分析,如图8所示,当α不变时,优化效果大体上随着△T的增大而先增后减。当△T较小时,TRS=T+△T<Tt=αt+Ttrans,优化效果会随着α的增大而减小。结果符合式(2)预期。
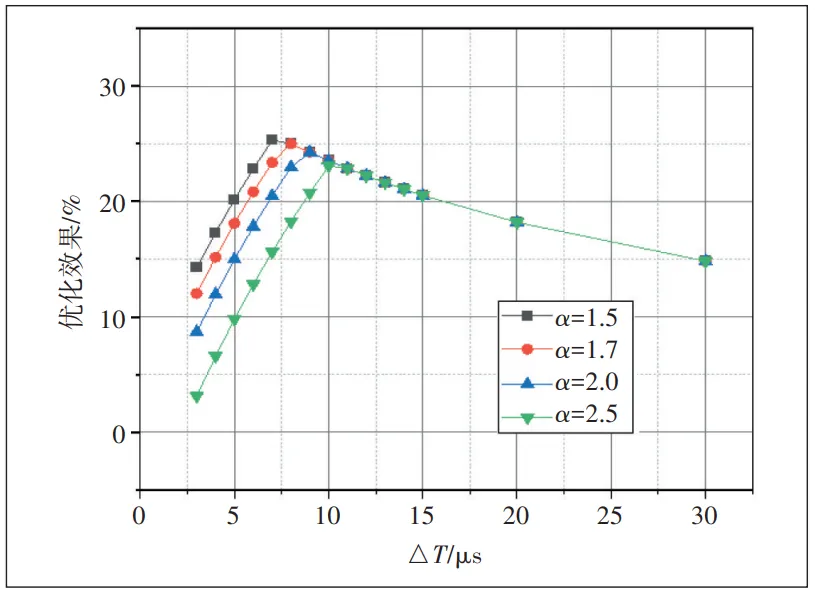
当TRS=T+△T>Tt=αT+Ttrans,优化效果与α的变化无关(见图9),结果符合式(1)预期。
T+△T<αT+Ttrans时,即慢节点跳过后一节点发送的数据先到达,α增大,说明后一节点最长等待时间将延长,触发机制的机会将相对减少,机制带来的增益受到限制,优化效果随之减弱。
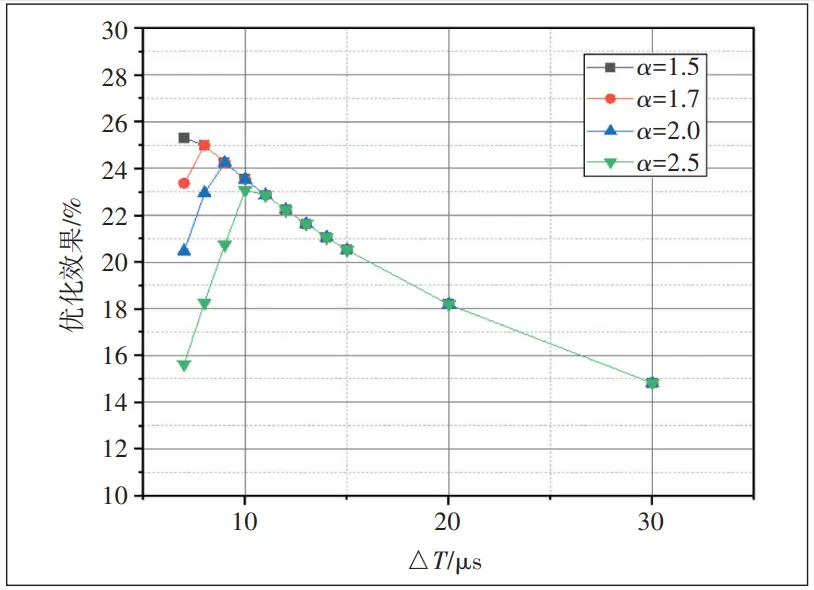
当△T是一个较大偏置时,有T+△T>αT+Ttrans,即后一节点发送的数据先到达而慢节点发送的数据后到达,此时获得的时间减少值Tdec是一个定值。△T的增加会导致TRing的时间线性增加,Tdec与TRing的比值也随之减少,即优化效果减弱(见图10)。
04 总结
在分布式计算中,Ring all-reduce是一种常用的通信模式,然而由于网络中存在慢节点,通信延迟分布不均匀,会影响整体性能。本文聚焦Ring all-reduce算法的Reduce_Scatter阶段,提出一种创新性的优化策略实现对慢节点的感知与通信调整,减小慢节点对整体通信性能的负面影响。仿真结果显示,相较于传统的Ring all-reduce算法,本文提出的优化策略成功降低了通信的时间开销,训练时长最高节省了25.3%。
作者简介
张汉钢,北京邮电大学硕士在读,主要从事分布式训练通信加速机制的研究工作;
邓鑫源,北京邮电大学硕士在读,主要从事OMNet++仿真网络的相关工作;
宋晔,北京邮电大学硕士在读,主要从事仿真算力节点网络的研究工作;
薛旭伟,拔尖人才教授,博士生导师,主要研究方向为面向数据中心和高性能计算的超快全光交换技术、可调谐硅光器件设计、高精度时频同步技术等;
郭秉礼,副教授,硕士生导师,主要从事数据中心与高性能计算中的光互联网络技术的相关研究工作;
黄善国,教授,博士生导师,主要从事多维光交换与光网络的研究工作。
论文地址:https://image.c114.com.cn/file/ys2024-02-05.pdf
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。