
内容摘要:chenhao 团队延续其 NeRV 相关工作,对 Position Encoding 的部分做了进一步的探索。在本文中,作者提出了一种混合神经表示视频(HNeRV),其中可学习的和内容自适应的嵌入充当解码器输入。
来源:CVPR 2023
作者:Hao Chen, Matthew Gwilliam, Ser-Nam Lim, Abhinav Shrivastava
原文链接:https://openreview.net/pdf?id=dOM_GHvkO2h
项目链接:https://github.com/haochen-rye/HNeRV
内容整理:何冰——煤矿工厂
背景介绍
隐式神经表示
计算机图形基本上由参数化外观的数学函数表示。数学表示法的质量和性能特性对视觉保真度至关重要。我们希望表示法能够保持快速和紧凑,同时捕获高频、局部细节。由多层感知器(MLPs)表示的函数,作为神经图形原语,已被证明符合这些标准。
在图像压缩方面,隐式神经表达最初的工作包括并不限于 SIREN,COIN,在视频压缩方面,有基于 NeRV 的一系列工作,在 3D 场景下,有基于 NeRF 的一系列工作。
本文的工作延续了作者的前作 NeRV 的思路,对 Position Encoding 的部分做了进一步的探索。
工作概述
隐式神经表示将视频存储为神经网络,并在视觉任务(如视频压缩和去噪)中表现良好。隐式表示(NeRV,E-NeRV 等)以帧索引和/或位置索引为输入,从固定的和与内容无关的嵌入中重建视频帧。这种嵌入在很大程度上限制了视频插值的回归能力和内部泛化。
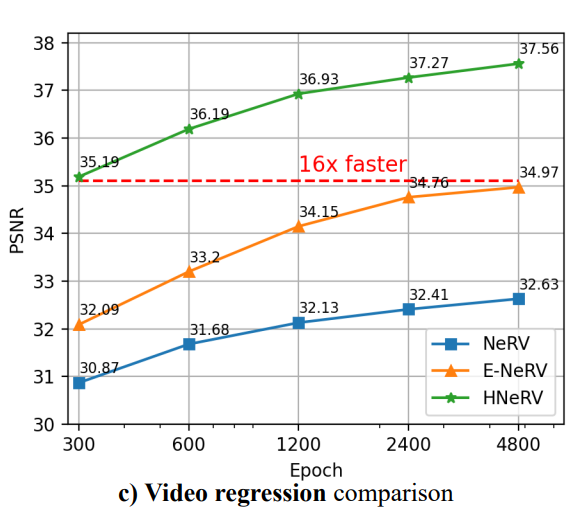
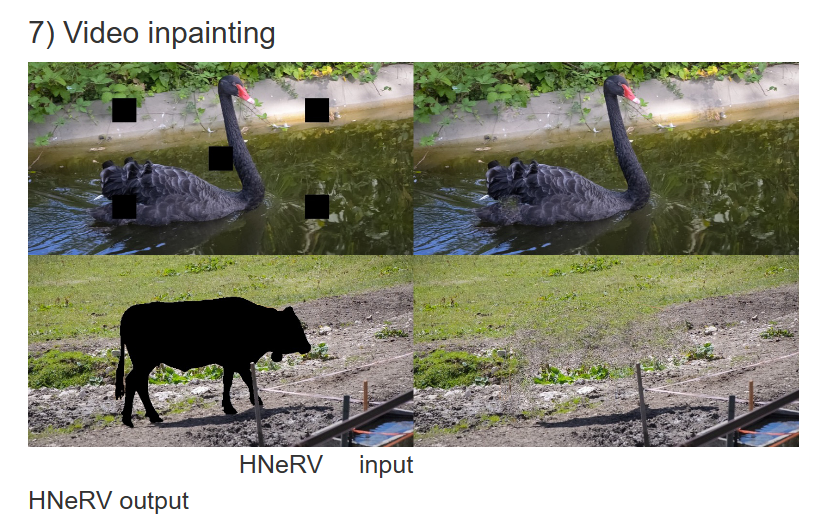
在本文中,作者提出了一种混合神经表示视频(HNeRV),其中可学习的和内容自适应的嵌入充当解码器输入。除了输入嵌入,作者还引入了一个 HNeRV 块,使模型参数在整个网络中均匀分布,因此更高层(靠近输出的层)可以有更多的容量来存储高分辨率内容和视频细节。借助内容自适应嵌入和重新设计的模型架构, HNeRV 在视频回归任务中优于隐式方法(NeRV,E-NeRV),无论是重建质量还是收敛速度,并显示出更好的内部泛化。作为一种简单而高效的视频表示,HNeRV 相比传统编解码器(H.264、H.265)和基于学习的压缩方法,在速度、灵活性和部署方面也显示出解码优势。最后,作者探讨了 HNeRV 在下游任务(如视频压缩和视频修复)上的有效性。
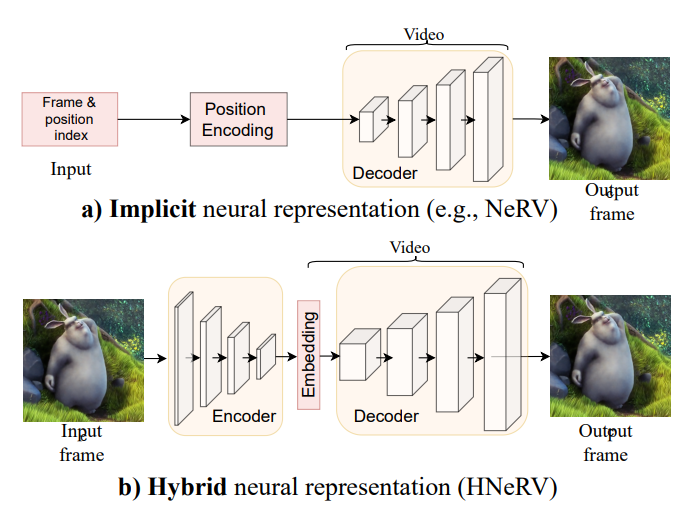

工作介绍
HNeRV 的工作其实很简单,可简单将其分为两部分进行分析。
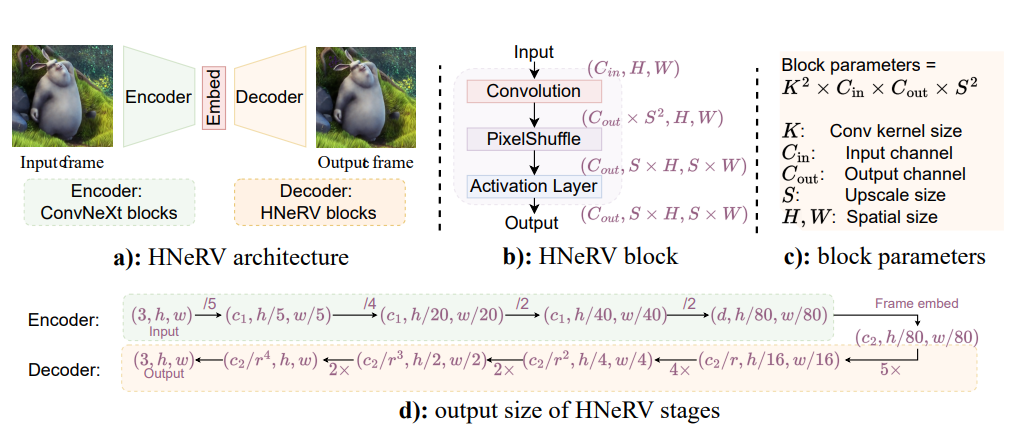
其 decoder 部分延续了 NeRV 工作,通过 conv 和 pixelshuffle 实现从特征到图像的升采样。
其 encoder 部分则是一个特征提取网络,通过多个 conv 层提取并压缩图像特征至一个 128 维的向量,与 decoder 中的网络参数组成整体的压缩结果。
encoder 与 decoder 是联合训练的,这一点与 GAN 很像,目的是高效地提取到紧凑的特征。

HNeRV 的时域空域插值效果明显优于前人工作,说明可学习特征的确使得神经网络代表的隐函数在时空域上更平滑。
整体来说 HNeRV 的工作相当简单,其在摘要中提到的 HNeRV block 也与先前论文 E-NeRV 中的 Conv-Up block 结构相似,但是由于去除了比较重的 MLP 层,HNeRV 的压缩性能有了比较大的提升,并且其在插值上的效果也显示出了隐式神经表示的连续性。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。