
在AISPEECH,我们为广泛的实体提供对话式人工智能服务和自然语言交互解决方案,包括金融机构、政府和IoV和IoT公司。如果你相信大数据是人工智能的燃料这一观点,你会发现一个高性能的数据处理架构对我们来说是多么重要。在这篇文章中,我将与你分享我们使用哪些数据工具和技术来支持我们的人工智能服务。
实时与离线:从分离到统一
2019年之前,我们使用 Apache Hive + Apache Kylin 搭建我们的离线数仓,Apache
Spark + MySQL 作为实时分析数据仓库:
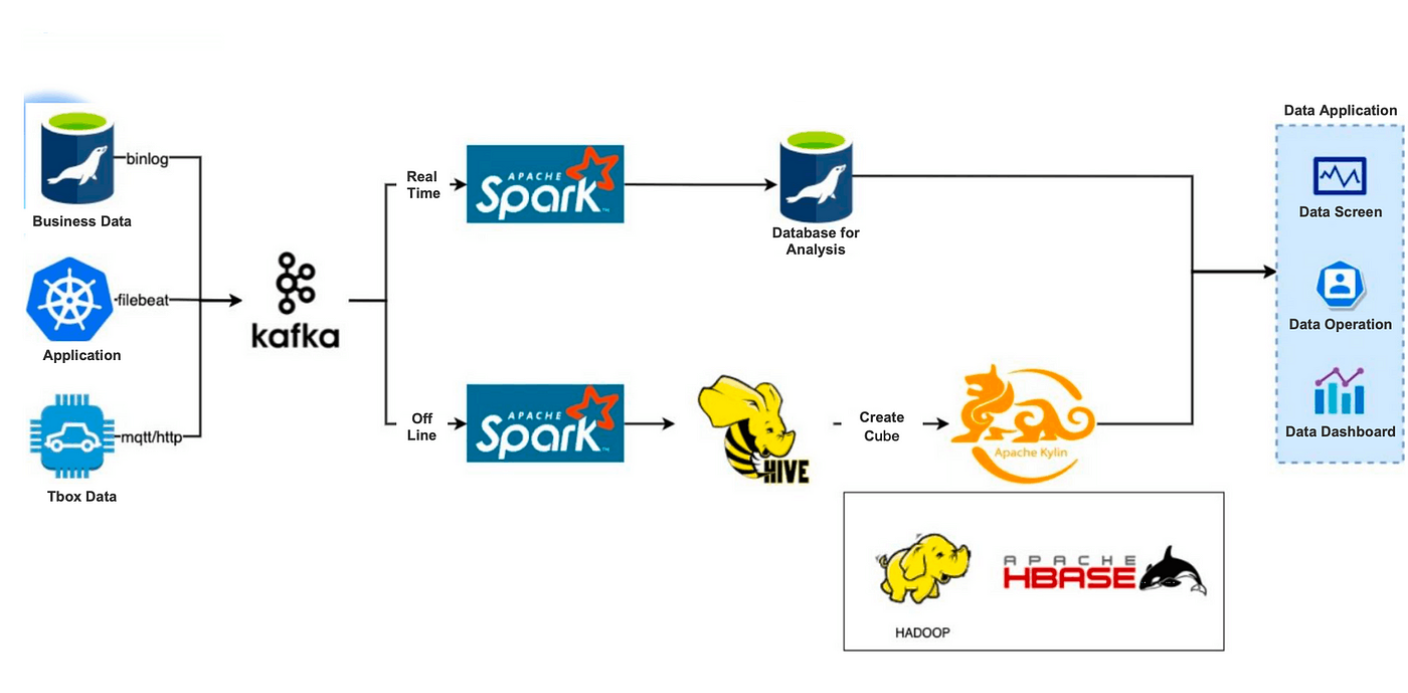

大致来说,我们有三个数据源:
- MySQL等业务数据库
- K8s容器日志等应用系统
- Automotive T-Box logs
我们将这些数据通过 MQTT/HTTP 协议、业务数据库 Binlog、Filebeat 日志采集写入到Kafka中。然后,数据将被分流到两个链接:实时和离线。
实时数据链接:Kafka 缓存的数据会被Spark 计算并放入MySQL 做进一步分析。
离线数据链接:Kafka清洗后的数据会放到 Hive 中。然后,我们使用Apache Kylin创建Cubes,但在此之前我们需要预先构建一个数据模型,其中包含关联表、维表、索引字段和相关的聚合函数。立方体的创建是由调度系统定期触发的。创建的 Cube 将存储在 HBase 中。
该架构与Hadoop技术无缝集成,Apache Kylin在预计算、聚合、精准去重、高并发场景下表现出色。但随着时间的推移,一些不愉快的问题暴露出来:
- 依赖太多:Kylin 2.x 和 3.x 严重依赖 Hadoop 和 HBase。太多的组件带来更长的开发环节,更高的不稳定性,以及更多的维护成本。
- Kylin 中复杂的 Cube 创建:这是一个繁琐的过程,包括所有平面表创建、列去重和 Cube 创建。每天跑1000~2000个任务,至少有10个任务失败,不得不花大量时间编写自动化运维脚本。
- Dimension/dictionary expansion : Dimension expansion是指当数据分析模型涉及的字段过多而没有进行数据剪枝时,Cubes的创建时间变长;当全局精确重复数据删除花费的时间太长并导致更大的字典和更长的创建时间时,就会发生字典扩展。两者都会拖累整体数据分析性能。
- 数据分析模型灵活性低:计算领域或业务场景的任何变化都可能导致数据回溯。
- 不支持细分查询:我们无法使用此架构查询数据细分。一种可能的解决方案是将这些查询下推到 Presto,但是引入 Presto 将意味着更多的运维麻烦。
因此,我们开始寻找最能满足我们需求的新 OLAP 引擎。后来,我们将选择范围缩小到 ClickHouse 和 Apache Doris。由于运维复杂度高,表类型多,ClickHouse不支持关联查询,最终选择了Apache Doris。
2019年,我们搭建了基于Apache Doris的数据处理架构,实时数据和离线数据都会被注入Apache Doris进行分析:
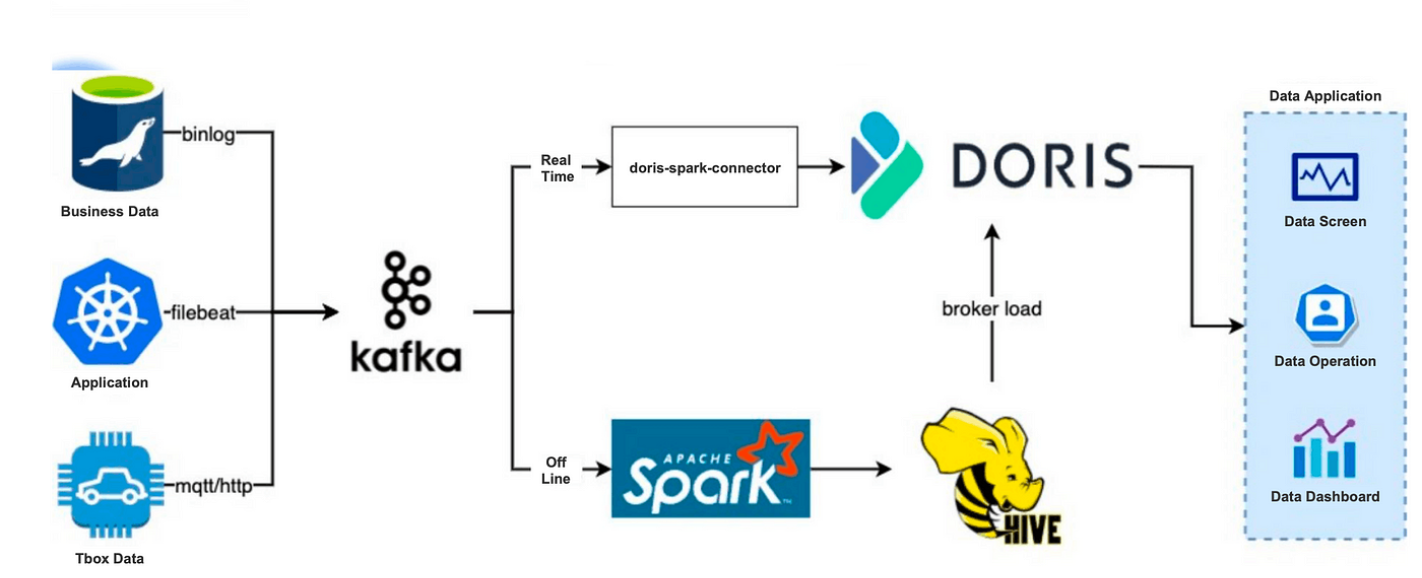
我们可以直接在 Apache Doris 中创建一个离线数据仓库,但是由于遗留原因,很难将我们所有的数据迁移到那里,所以我们决定保留我们之前离线数据链接的上半部分。
不同的是 Hive 中的离线数据将写入 Apache Doris 而不是 Apache Kylin。Doris 的 Broker Load 方法很快。每天需要 10~20 分钟,将 100~200G 的数据摄取到 Doris 中。
至于实时数据链路,我们使用 Doris-Spark-Connector 将数据从 Kafka 摄取到 Doris。
新架构有什么好处?
- 运维简单,不依赖Hadoop组件。 部署 Apache Doris 很容易,因为它只有 Frontend 和 Backend 进程。这两种进程都可以横向扩展,所以我们可以只创建一个集群来处理数百台机器和几十PB的数据。我们已经使用 Apache Doris 三年了,但只花了很少的时间进行维护。
- 轻松排除故障。拥有实时数据服务、交互式数据分析、离线数据处理的一站式数据仓库,让开发环节变得更短、更简单。如果出现任何问题,我们只需要检查几个地方就可以找到根本原因。
- 支持运行时格式的 JOIN 查询。这类似于 MySQL 中的表关联。这在需要频繁更改数据分析模型的场景中很有帮助。
- 支持 JOIN、聚合和细分查询。
- 支持多种查询加速方式。 这些包括汇总索引和物化视图。Rollup 索引允许我们实现二级索引来加速查询。
- 支持跨数据湖(例如 Hive 、Iceberg、Hudi)和数据库(例如 MySQL 和 Elasticsearch)的联合查询。
Apache Doris 如何赋能 AI
在 AISPEECH 中,我们使用 Apache Doris 进行实时数据查询和用户自定义对话数据分析。
实时数据查询
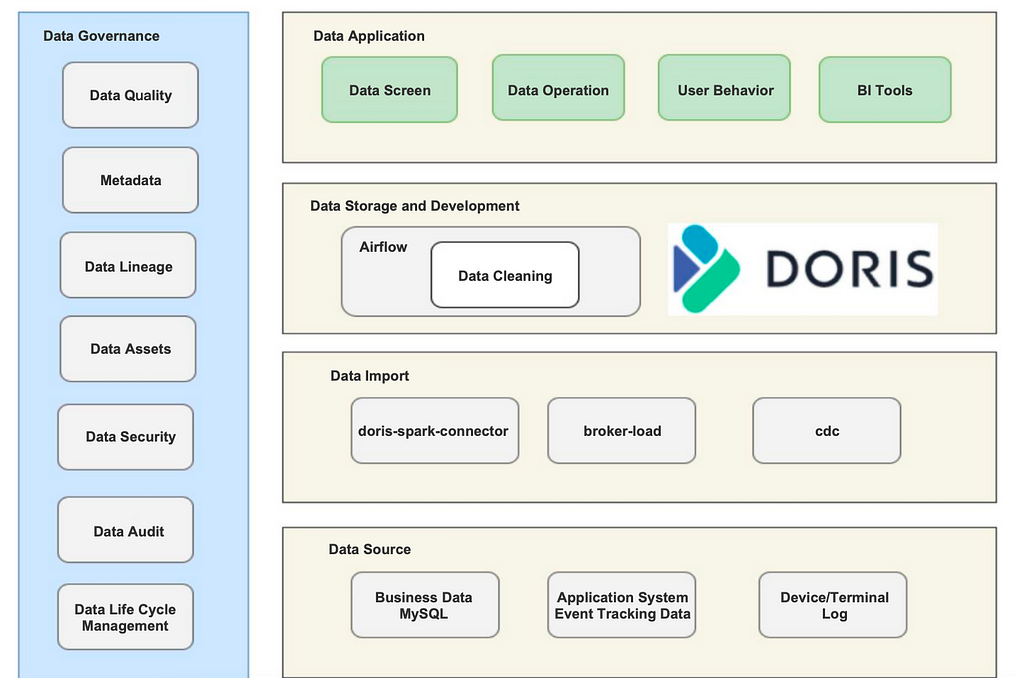
实时数据处理流水线的工作原理如上。我们通过 Broker Load 获取离线数据,通过 Doris-Spark-Connector 获取实时数据。我们几乎所有的实时数据都放在 Apache Doris 中,部分离线数据放在 Airflow 中用于 DAG 批处理任务。
我们的实时数据是海量的,所以我们确实需要一个保证高查询效率的解决方案。同时,我们有一个20人的数据运营团队,需要为所有人提供数据看盘服务。这对于实时数据写入和要求苛刻的查询并发性来说可能具有挑战性。幸运的是,Apache Doris 让这一切成为可能。
用户定义的会话数据分析
这是我最喜欢的部分,因为我们自豪地在数据查询中利用了我们的自然语言处理 (NLP) 功能。
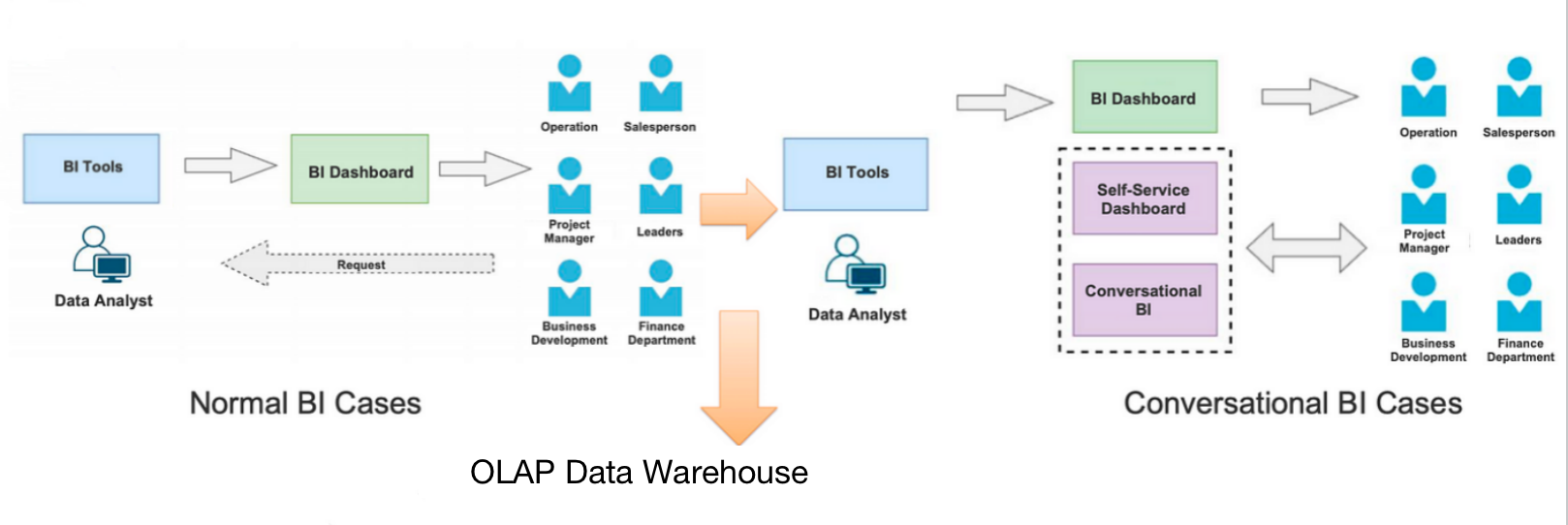
正常的 BI 场景是这样工作的:数据分析师根据数据用户(例如,财务部门和产品经理)的需求在 BI 平台上自定义仪表板。但我们想要更多。我们希望满足数据用户的更多独特需求,例如在任何指定维度上进行汇总和向下钻取。这就是我们启用用户定义的对话数据分析的原因。
与普通的 BI 案例不同,与 BI 工具对话的是数据用户,而不是数据分析师。他们只需要用自然语言描述他们的需求,我们利用我们的NLP能力,将他们变成SQL。听起来很熟悉?是的,这就像特定领域的 GPT-4。除此之外,我们长期以来一直在优化它并对其进行微调以更好地与 Apache Doris 集成,以便我们的数据用户可以期待更高的命中率和更准确的解析结果。然后,将生成的 SQL 发送给 Apache Doris 执行。通过这种方式,数据用户可以查看任何细分详细信息并向上滚动或向下钻取任何字段。
Apache Doris 如何使这项工作顺利进行?
与 Apache Kylin、Apache Druid 等预计算 OLAP 引擎相比,Apache Doris 具有以下优势:
- 支持用户自定义场景的灵活查询模型
- 支持表关联、聚合计算、细分查询
- 快速响应时间
我们的内部用户一直对这种对话数据分析给予积极的反馈。
建议
我们在Apache Doris的使用上积累了一些实践经验,相信可以让你少走一些弯路。
表设计
- 对小数据量(例如,少于 1000 万行)使用重复表。重复表同时支持聚合查询和细分查询,因此您无需生成包含所有明细数据的额外表。
- 对大数据量使用聚合表。然后你可以进行汇总索引,通过物化视图加速查询,并优化聚合表顶部的聚合字段。一个缺点是,由于聚合表是预先计算的表,您将需要一个额外的细分表来进行详细查询。
- 在处理关联表多的海量数据时,通过ETL生成一个平面表,然后将其摄取到Apache Doris,您可以在Apache Doris中根据聚合表类型做进一步的优化。或者你可以按照Doris 社区推荐的Join 优化。
贮存
我们在存储中隔离热数据和暖数据。过去一年的数据存储在 SSD 中,较旧的数据存储在 HDD 中。Apache Doris 允许我们为分区设置冷却时间,但相关配置只能在创建分区时进行。我们目前的解决方案是自动同步,我们将一部分历史数据从SSD迁移到HDD,确保过去一年的数据都放在SSD上。
升级
确保在升级前备份元数据。另一种方法是启动一个新的集群,通过Broker将数据文件备份到远程存储系统,如S3或HDFS,然后通过备份恢复的方式将旧集群数据导入新集群。
版本升级后性能
从 Apache Doris 0.12 开始,我们一直在赶上 Apache Doris 的发布。在我们的使用场景中,最新版本可以提供比早期版本高数倍的性能,特别是在复杂函数查询和涉及多个字段的语句中。我们非常感谢Apache Doris社区的努力,强烈建议您升级到最新版本。
概括
总结我们从 Apache Doris 中获得的东西:
- Apache Doris可以做一个实时+离线的数仓,所以我们只需要一个ETL脚本。它为我们节省了大量的开发工作和存储成本,也避免了实时和离线指标之间的不一致。
- Apache Doris 1.1.x 支持矢量化,因此可以提供比旧版本高 2~3 倍的性能。测试结果表明,Apache Doris 1.1.x 在平表查询性能上与 ClickHouse 相当。
- Apache Doris 本身很强大,不依赖于其他组件。与 Apache Kylin、Apache Druid 和 ClickHouse 不同,Apache Doris 不需要其他组件来填补任何技术空白。它支持聚合、细分查询和关联查询。我们已经将超过 90% 的分析迁移到了 Apache Doris,这让我们的运维变得更加轻量和容易。
- Apache Doris 易于使用,因为它支持 MySQL 协议和标准 SQL。
作者:Wei Zhao
原文链接:https://dzone.com/articles/what-database-we-use-to-support-our-ai-chatbots
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/20327.html