
UUID是国际标准化组织(ISO)提出的一个概念。UUID用来识别属性类型,在所有空间和时间上被视为唯一的标识。本文将从UUID的构成方式、现行版本、生成策略、应用案例等方面作介绍。
作者:钱江奇 李鸣扬
单位:中国移动智慧家庭运营中心 智慧互联产品部
什么是UUID
UUID全称Universal Unique Identifier是一串128位数字码,用于唯一识别网络对象或者事件。由于其独特的生成机制和使用场景,UUID可以确保全局唯一性,避免重复。UUID广泛应用于各种需要唯一识别的场景,例如数据库主键、系统实例ID, 识别生命周期短暂的蓝牙配置文件和对象等。
UUID是类似于GUID的术语,最初由微软引入的GUID实际上是UUID的一种变体,在RFC 4122规范中将这两个术语定义为同义词。随后,开放软件基金会(OSF)对UUID进行了标准化,使其成为分布式计算网络中的重要组成部分,衍生出的各个UUID版本都遵循RFC 4122规范。
UUID的构成方式
但如果计UUID通常通过特定算法生成,例如基于时间戳或网络地址等。UUID通过特定的组合排列方式确保其唯一性,由32个16进制数字(包括数字0到9和字母A到F)和4个连字符构成。每个连字符的字符数是8-4-4-4-12,其中最后4位或者N位表示格式和编码:
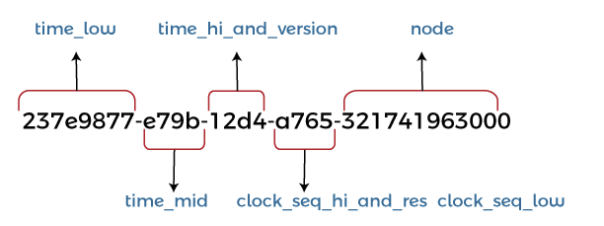

UUID也可以用十进制或者二进制格式表示:

传统的UUID大致分成3种变体:
➤ 变体0:为了兼容80年代未过时的阿波罗网络计算系统而保留,它的结构与目前使用的version 1相似。
➤ 变体1:目前主要使用的变体,在Internet工程文档规范中被定义为RFC 4122/DCE 1.1 UUID或Leach-Salz UUID,例如微软的GUID就是UUID的变体1。
➤ 变体2:为了兼容微软后续发展而保留,尽管现有的微软GUID是UUID的变体1,但早期Windows平台使用的是变体2。变体1和变体2在N位位置的比特数字不同,例如变体1使用2位比特位,而变体2使用3位比特位。
UUID的现行版本
现有的UUID主要是基于变体1衍生出来的,由5个不同版本组成,不同版本的UUID生成方式有所区别,具体包括:
Version1:基于时间戳和节点生成的UUID。它使用当前时间和计算机的MAC地址来生成唯一标识符。这个版本的UUID保证了全局唯一性和时间排序性,但在某些情况下可能存在安全性和隐私问题。
Version2:基于DCE安全标识符(DCE Security Identifier)生成的UUID。这个版本的UUID将标识符的角色和权限信息编码到UUID中,使其能够表示用户、组和ACL(访问控制列表)。然而,这个版本的UUID并不常见,也没有得到广泛支持。
Version3:基于名称和命名空间生成的UUID。它使用MD5散列函数对名称和命名空间进行处理,生成唯一的标识符。这个版本的UUID可用于标识命名空间中的对象,如URL、域名等。
Version4:基于随机数生成的UUID。这个版本的UUID使用随机数生成算法生成,因此具有很高的随机性和唯一性。它是目前最常用的UUID版本,广泛应用于各种领域。
Version5:基于名称和命名空间生成的UUID。它与Version 3相似,但使用的是SHA-1散列函数,提供更强的散列算法。这个版本的UUID也可用于标识命名空间中的对象。
现有UID的生成策略
4.1 Mysql生成ID
Mysql使用主键auto_increment方式生成ID,ID之间的步长固定,但可以自定义步长。这种方式简单易用,可以保证ID的递增性和唯一性,但是存在单点故障和数据一致性问题、在扩展性方面也存在一定的挑战。
4.2 MongoDB生成ID
MongoDB生成的UUID是由12字节十六进制数字组成,具体组成:4字节–以秒为单位的时间戳,3字节–机器标识符,2字节–进程ID,3字节–计数器(从一个随机值开始)。比传统的UUID短,但比MYSQL自动增量字段(64位Bigint值)长。
4.3 Redis生成ID
Redis通常使用原子操作INCR或INCRBY实现ID生成。如果是Redis集群可以设置ID初始值并自定义每个节点ID的步长。由于Redis是单线程模型,可以保证生成的ID具备唯一性。
4.4 Zookeeper生成ID
Zookeeper主要通过ZNODE数据版本生成ID,此ID通常是32位或者64位字符串构成,客户端可以使用该ID作为UID使用。由于需要强依赖Zookeeper,在高并发的场景多的情况下很少考虑使用这种方式。
UUID的应用案例分析
5.1 Twitter生成UUID
Twitter使用雪花算法作为专业服务来统一生成64位唯一标识符,用于分布式系统中的对象标识,例如推特、直接消息、列表等。这些ID是基于时间的的唯一无符号64位整数,完整的ID定义主要组成方式如下:
- 41位–时间戳以毫秒为单位(相对于任何自定义纪元,通常可以使用69年)
- 10位–已配置的机器/节点/分片ID
- 12位–序列号(每台机器的本地计算器,每4096个值后设置为0)
- 1位–额外保留位,一般被设置为0来确保总数为正值
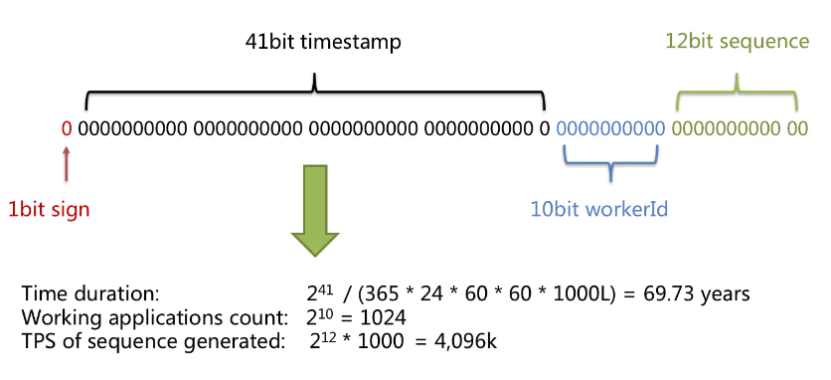
按着这种方法构成的UID不仅提高可用性,因为使用时间戳为首部分,还可以根据时间进行排序。默认情况下,雪花算法生成一个64位的无符号长整型,也就是长度为19的ID。有时具体项目中可能不需要这么长,也可以根据自身需要修改该算法。
5.2 百度生成UUID
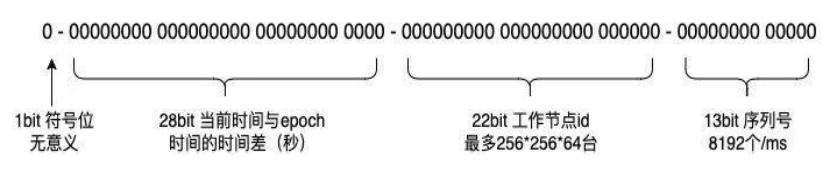
百度基于雪花算法改进生成UID,对UID的bit位进行调整,将时间戳部分修改为28位,用于表示当前时间与初始上线生成的时间的时间差(单位为秒),其中初始时间可以手工配置。使用22位表示工作节点ID,实例启动的时候生成分布式ID,写入数据库中得到的自增长序列值。使用13位序列号来解决时间回拨等问题,如果当前时间和上一次是时间相同则序列自增,超过阈值则自旋。
5.3 美团生成UUID
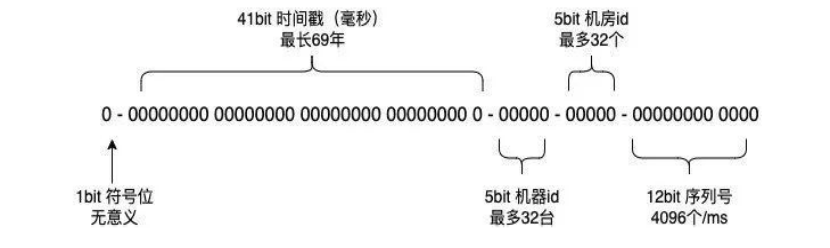
美团基于雪花算法改进,使用“1+41+5+5+12”的方式构成UID,在原雪花算法的基础上,使用5位bit代表机器ID,5位bit代表机房ID,12位序列号代表自增值,由于集群较大,基于Zookeeper组件特性配置机器ID。对于时间回拨问题的解决方案,设定阈值5毫秒,回拨时间小于5毫秒则等待回拨后重新生成新的UID,超过阈值则抛出异常。
省级宽带电视会员管理平台的应用实践
省级宽带电视会员管理平台主要管理各省宽带电视的会员用户,是一个大型分布式平台,服务器跨省分布,数量众多,存在时钟回退问题。因此,本平台在雪花算法基础上进行改进,增加时间线的概念,可以同时支持多条时间线并行,很好地解决了时钟回退问题。具体方案如下:
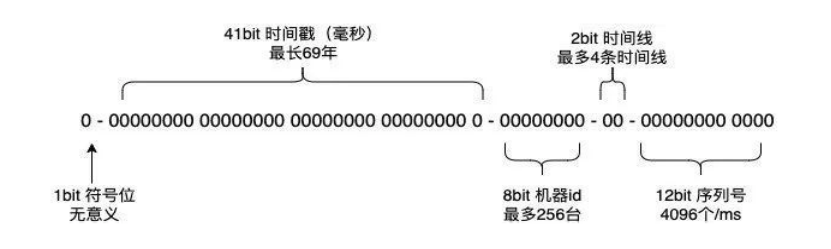
调整2位bit代表时间线,最多支持4条时间线,所有时间线设定统一初始时间,指定一条时间线为统一时间线,根据该时间线生成相应的ID,推进时间进度。机器发生时钟回拨时,当回拨时间间隔大于设定的阈值,切换到另一条时间线继续生成ID。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。