
先进的学习图像压缩方法以空间上下文模型为特色,与超先验方法相比,在率失真方面取得了巨大的改进。然而,自回归上下文模型需要串行解码,限制了运行性能。Checkerboard 上下文模型允许并行解码,但代价是降低 RD 性能。本文提出了一系列多级空间上下文模型,可以实现快速解码和更好的 RD 性能。
题目:MULTISTAGE SPATIAL CONTEXT MODELS FOR LEARNED IMAGE COMPRESSION
作者:Fangzheng Lin, Heming Sun 等
文章地址:https://arxiv.org/abs/2302.09263v1
内容整理:杨晓璇
引言
学习图像压缩 (LIC) 具有最先进的率失真 (RD) 性能,许多最新方法的性能优于 BPG 和 VVC 等最佳手工方法。许多最新的 LIC 编解码器利用空间上下文模型,该模型根据已解码的周围潜在编码推断当前潜在编码的概率分布代码,大大优于基于超先验的方法。
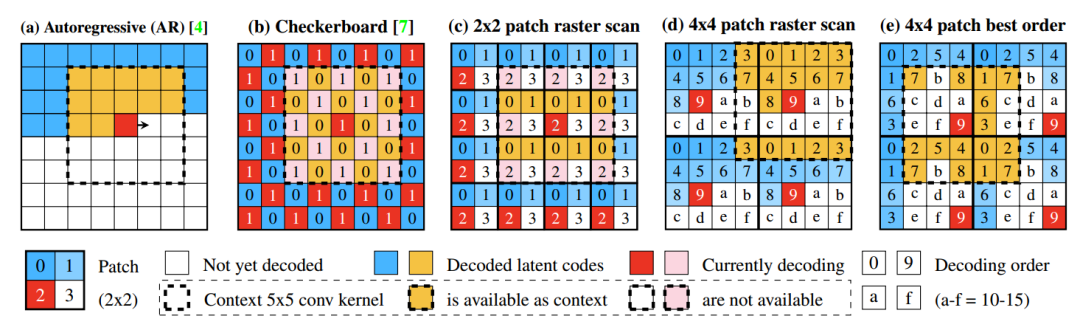
以前的许多空间上下文模型都具有自回归结构:如图 1(a) 所示,潜在代码按光栅扫描顺序进行解码。然而,由于后续潜在代码的解码始终依赖于先前潜在代码的信息,因此这些模型只能串行运行并且解码速度较慢。
如图 1(b) 所示,Checkerboard 上下文模型通过仅使用超先验解码一半的潜在表示来加速此过程。然后,使用超先验和已解码的潜在代码作为上下文来解码剩余的一半。它支持并行执行且具有快速的解码速度,但代价是率失真性能降低。
是否有可能在拥有良好的 RD 性能的同时仍然保持快速?本文通过提出一系列具有不同数量的解码阶段的空间上下文模型来证明这是可能的。本文提出的上下文模型将图像潜在空间分割成方形块,然后仅在每个块内进行自回归解码。由于不同块中的潜在代码彼此不依赖,因此不同块可以并行解码。
每个块中的解码顺序必须仔细决定,因为错误的解码顺序会损害性能。本文提出了一种优化算法,通过估计不同顺序对随机掩码模型的影响来找到最佳解码顺序。本文作者证明,提出的上下文模型在优化解码顺序后,性能优于 Checkerboard,并达到自回归上下文模型的 RD 性能,甚至还优于它。

模型
使用空间上下文模型对 LIC 中的图像进行解码包括:
- 熵解码和超先验的合成;
- 通过卷积层检索空间上下文信息(如果有),并从超先验和上下文共同推断潜在概率分布,以及潜在代码的熵解码;
- 从潜在空间合成图像。
重点讨论第二步,一个可能成为性能瓶颈的循环过程。如果第二步重复 m 次,将上下文模型称为 m 阶段。
本文的讨论基于 Cheng2020 模型,但本文的方法不限于此架构。由于专注于讨论不同的上下文模型,因此不修改其他模型结构并使用 5×5 卷积核来提取上下文。
多阶段上下文模型
关于 RD 性能,Checkerboard 的主要限制是锚定潜码的比例较高。由于无法从空间上下文中受益,锚定潜码通常需要更多比特来进行编码。如图 1(b) 所示,Checkerboard 可以看作是一个 2 阶段上下文模型;50% 的潜在代码在阶段 0 中被解码为锚点,以充当阶段 1 的空间上下文信息。这意味着一半的潜在表示无法从上下文模型提供的比特率降低中受益。
因此,直观的,减少锚点的比例可以提高 RD 性能。本文模型通过更多的解码阶段来实现这一点。将潜在空间分割成 n x n 的相等正方形块,并在 n2 个阶段对其进行解码。在每个阶段,从每个块中解码一个潜在代码;也就是说,在每个阶段对 h x w / n2 个潜在代码进行解码。举两个例子,将潜在空间用 2×2 的块进行划分,如图 1(c) 所示,其中解码分 4 个阶段进行;用 4×4 的块进行划分的情况如图 1(d) 和 (e) 所示,并分 16 个阶段进行解码。
潜在代码的解码按照十六进制数字升序显示的顺序执行。例如,(c) 和 (d) 显示的是光栅扫描顺序。只有前一阶段解码的潜在代码可用,并通过 5×5 卷积用作上下文信息。例如,在(c)中,每个块的第 2 阶段的所有潜在代码正在被并行解码;在 5×5 感受野中,前阶段 0 和 1 的潜在代码可以用作上下文;相反,阶段 2 和阶段 3 则不能,因为它们尚未被解码。
这样,只有阶段 0 的潜在代码必须被解码,而无需任何上下文信息。多阶段上下文模型将锚点的比例减少到 1/n2 x 100%,在 2×2 模型的情况下减少至 25%,在 4×4 的情况下减少至 6.25%。
解码顺序优化算法
本文提出的多级上下文模型中有许多可能的解码顺序。图 1(d) 和 (e) 显示了 4×4 块中两种不同的可能顺序。在不同的解码顺序中,可用作上下文信息的潜在代码也不同。例如,图 2 示出了图 1(c) 所示的解码顺序的解码阶段和对应的可用上下文位置;其他解码顺序可能无法访问那些相同的上下文位置。这导致某些解码顺序比其他解码顺序表现更好,因为它们可以更好地利用上下文信息。
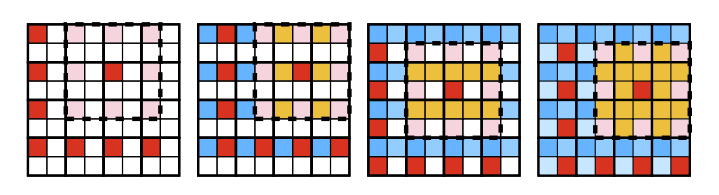
然而,在所有解码顺序中训练模型并对其进行最佳评估是不可能的,尤其是在阶段较多的情况下。对于 4×4 模型,即 16 级,有 16!种可能的安排;即使使用超级计算机也不可能训练这么多模型。
因此,本文提出一种模拟不同解码顺序效果的估计算法。引入随机掩模模型,该模型遵循空间上下文模型的典型结构,但允许额外的输入以在上下文卷积中暂时将内核权重为零。如图 3 所示,在每个训练步骤中,随机生成 5×5 掩码,并对上下文卷积核中非掩码位置下的权重进行备份和归零,以便模型只允许使用掩码潜在代码位置作为上下文信息。每一步之后都会恢复归零的权重。在反向传播期间,仅更新屏蔽位置下的权重。上下文模型逐渐学习为 5×5 内核中任何一组给定的潜在代码位置生成足够好的推理。
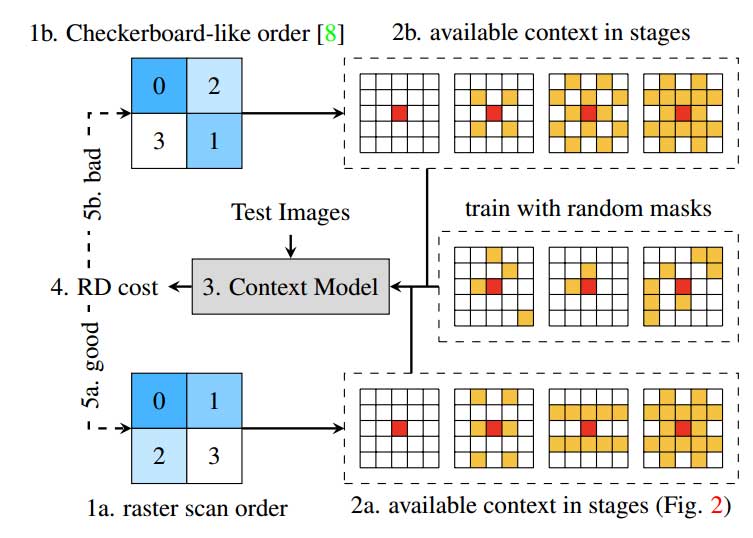
评估解码顺序的方法如图 3 所示:
- 通过深度优先搜索枚举 n×n 块中解码顺序的所有排列。
- 对于每个解码顺序,通过图 2 所示的过程找到每个阶段中哪些上下文位置可用作上下文。始终使用 5×5 卷积核中的所有可用位置。
- 将位置掩码输入随机掩码模型,以限制其仅使用这些位置作为上下文。
- 随机掩模模型通过使用这些掩模位置的上下文对测试图像进行编码来评估 RD 成本。
- 通过比较 RD 成本来估计每种解码模式的性能,越低越好。
这里选择了 5×5 卷积核,因为学习和搜索更大的掩模(例如 7×7)的计算量太大;5×5 是最佳位置。还值得注意的是,随机掩模模型仅用于实验,并不用于实际压缩,因为对模型进行了优化,以使其在任何掩模上都能表现良好。然后,将找到的最佳解码顺序硬编码到编解码器中,并训练专门针对它优化的模型,以实现最佳的 RD 性能。
实用的块尺寸
典型的合成变换将 3×H×W 的图像缩小为 M × H/16 ×W/16 。要将此类潜在空间分割为 n×n 个块,必须将 H 和 W 填充为 16n 的倍数。典型的超先验变换将潜在空间进一步缩小到 N × H/64 × W/64 ,因此在基于超先验的 LIC 中已经要求 H 和 W 填充到 64 的倍数。
添加上下文模型后,图像必须填充到 lcm(16n, 64) 倍数的大小。例如,当 n=3 时,这会带来问题,因为 lcm(48, 64)=192 需要对许多图像进行大量填充,使得这样的块大小在实际使用中不切实际。2×2 和 4×4 的块大小不受此影响,因为两种大小的 lcm(16n, 64) 都是完美的 64,因此不需要额外的填充。
实验
对上下文模型的两种变体进行了实验:2×2 块分割 和 4×4 块分割。模型的实现基于 CompressAI 的 Cheng2020Attention,但将其更改为使用正态分布数量 K = 3 的 GMM 来遵循原始设置,并用本文提出的方法替换自回归上下文模型。
最佳解码顺序
使用图 3 中描述的方法来搜索 2×2 和 4×4 变化中的最佳解码顺序。使用质量参数 λ = 0.0035 对随机掩模模型的变体进行评估,并使用一些随机图像作为输入。
结果发现,对于 2×2 模型,图 1(c) 所示的光栅扫描顺序已经是最佳解码顺序。对于 4×4,图 1(d) 中所示的光栅扫描顺序并不是最佳的。最佳解码顺序之一如图 1(e) 所示。使用最好的解码顺序进行后续实验。
需要注意,良好的解码顺序总是涉及每个阶段的四个邻接。这解释了为什么 2×2 的光栅扫描顺序优于 Checkerboard 模式:后者未能引用阶段 1 中的任何四个邻接,如图 3(2b)所示,因此该阶段无法达到良好的压缩效果。从不同方向参考空间背景也有利于准确性;由于 4×4 光栅扫描主要涉及顶部和左侧潜在代码,因此它的性能优于利用多个方向的空间依赖性的最佳顺序。
率失真性能
从 Open Image Dataset 中随机选择的约 360,000 张图像的子集上训练本文的模型。训练了 6 个 2×2 和 4×4 模型的变体,每个模型都有一个质量参数 λ ∈{0.018,0.035,0,0067,0.013,0.025,0.0483} 并针对 PSNR 进行优化。对于前 3 个 值,使用 N=M=128,其余的使用 N=M=192,其中 N 是卷积中的通道数,M 是熵估计中的通道数。在 Kodak 图像数据集 和 CLIC Professional 上评估本文模型。将本文的两个模型与两个 baseline 进行比较:图 1(a) 中的自回归(AR)和图 1(b) 中的 Checkerboard。对于基线,使用相应论文中的数据。
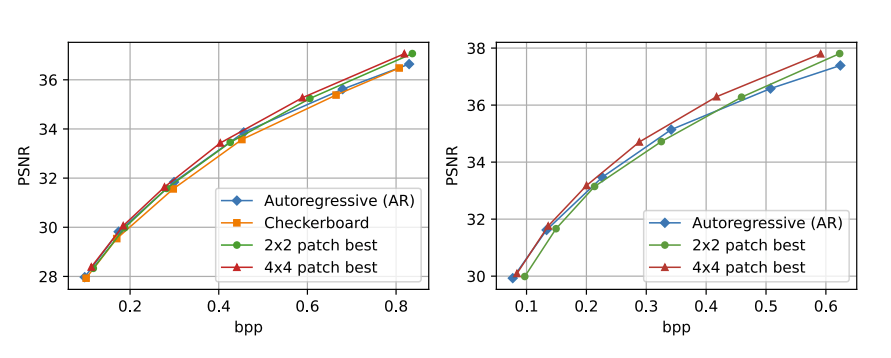
图 4 显示了不同上下文模型的 RD 曲线。在 Kodak 上,所提出的上下文模型优于 Checkerboard,并且 2×2 和 4×4 变体都达到了自回归(AR)的 RD 性能。在更高的比特率下,本文上下文模型优于 AR,并且 4×4 在所有码率点均超过 2×2 并显示出约 -2% 的 RD 成本节约。在 CLIC 上,与 AR 相比,尽管 2×2 在较低比特率下表现出性能下降,但 4×4 大大优于 AR,并且在所有码率点超过 2×2 ,显示出 -5% 的 RD 成本节约。
运行时间
本文还评估了所提出的上下文模型的解码速度,并将其与自回归(AR)和 Checkerboard 进行比较。使用 N = M = 128 的模型,并平均在柯达数据集上的运行时间。为了公平比较,除了上下文模型中必要的差异之外,其余均使用相同的实现。如表 1 所示,本文的模型比 AR 快得多,并且由于级数增加而仅比 Checkerboard 稍慢,由于出色的 RD 性能,这是一个可以接受的权衡。

消融实验
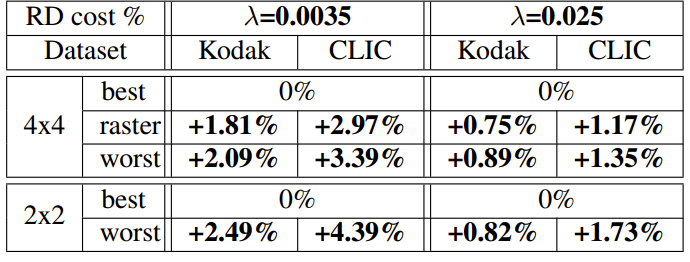
进行了一项消融研究以显示良好解码顺序的重要性。为了与最佳解码顺序进行比较,在 λ ∈{0.0035,0.025} 处训练一组额外的模型。对于 4×4,将最佳解码顺序与图 1(d) 所示的光栅扫描解码顺序以及效率最低(最差)的解码顺序进行比较。对于 2×2,将图 1(c)、2 和 3(a) 所示的最佳解码顺序(光栅扫描顺序)与图 3(b) 所示的 Checkerboard 顺序进行比较,将其评估为效率最低(最差)的。如表 2 所示,解码顺序效率较低时,RD 成本会增加,尤其是 λ 在较小时。
结论
在这项工作中,作者建议将潜在空间分割成均匀大小的正方形块,并在块内以优化的顺序进行解码。所提出的上下文模型可以具有与自回归上下文模型相当甚至优于自回归上下文模型的 RD 性能和快速并行解码的能力。
在未来的研究中,本文的工作可以与最新的具有空间上下文的 SOTA 架构集成,或者与通道上下文相结合,以创建更好的通道空间上下文模型,以实现更好的效果研发性能。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。