
强大的文生图预训练模型缺乏可以指导合成图像的空间属性的控制方法。在这项工作引入了一种通用方法,通过在推理期间使用来自另一个域(例如草图)的空间图来指导预训练的文本到图像扩散模型。
论文题目:Sketch-Guided Text-to-Image Diffusion Models
论文链接:https://sketch-guided-diffusion.github.io/files/sketch-guided-preprint.pdf
项目链接:https://sketch-guided-diffusion.github.io/
作者:Andrey Voynov, Kfir Aberman等
内容整理:王寒
简介
文本到图像模型是机器学习发展中的一次飞跃,展示了根据给定文本提示的图像的高质量合成的能力。然而,这些强大的预训练模型缺乏可以指导合成图像的空间属性的控制方法。在这项工作中,作者引入了一种通用方法,通过在推理期间使用来自另一个域(例如草图)的空间图来指导预训练的文本到图像扩散模型。该方法不需要为任务训练专用模型或专门的编码器。
主要思想是引入一个潜在指导预测器Latent Guidance Predictor (LGP),它是一个像素级的多层感知机,将DDPM生成的潜在特征图和空间图建立映射。每像素训练提供了灵活性和局部性,使得该技术能够在域外草图上表现良好。
本文特别关注草图到图像的转换任务,揭示了一种稳健且富有表现力的方法来生成遵循任意风格草图指导的图像。
算法结构
为了便于描述,该部分以草图指导图像生成为例介绍。
该方法的关键思想是使用边缘预测器来指导预训练的文本到图像扩散模型的推理过程,该边缘预测器对扩散模型核心网络的内部激活进行操作,从而鼓励合成图像的边缘遵循参考草图。边缘预测器是一个多层感知网络,用于映射加噪图的特征到空间边缘图中。
潜在边缘预测器(Latent Edge Predictor)
首先训练 MLP,用目标边缘图指导图像生成过程。MLP 经过训练,可将去噪扩散模型网络的内部激活映射到空间边缘图,如图所示。
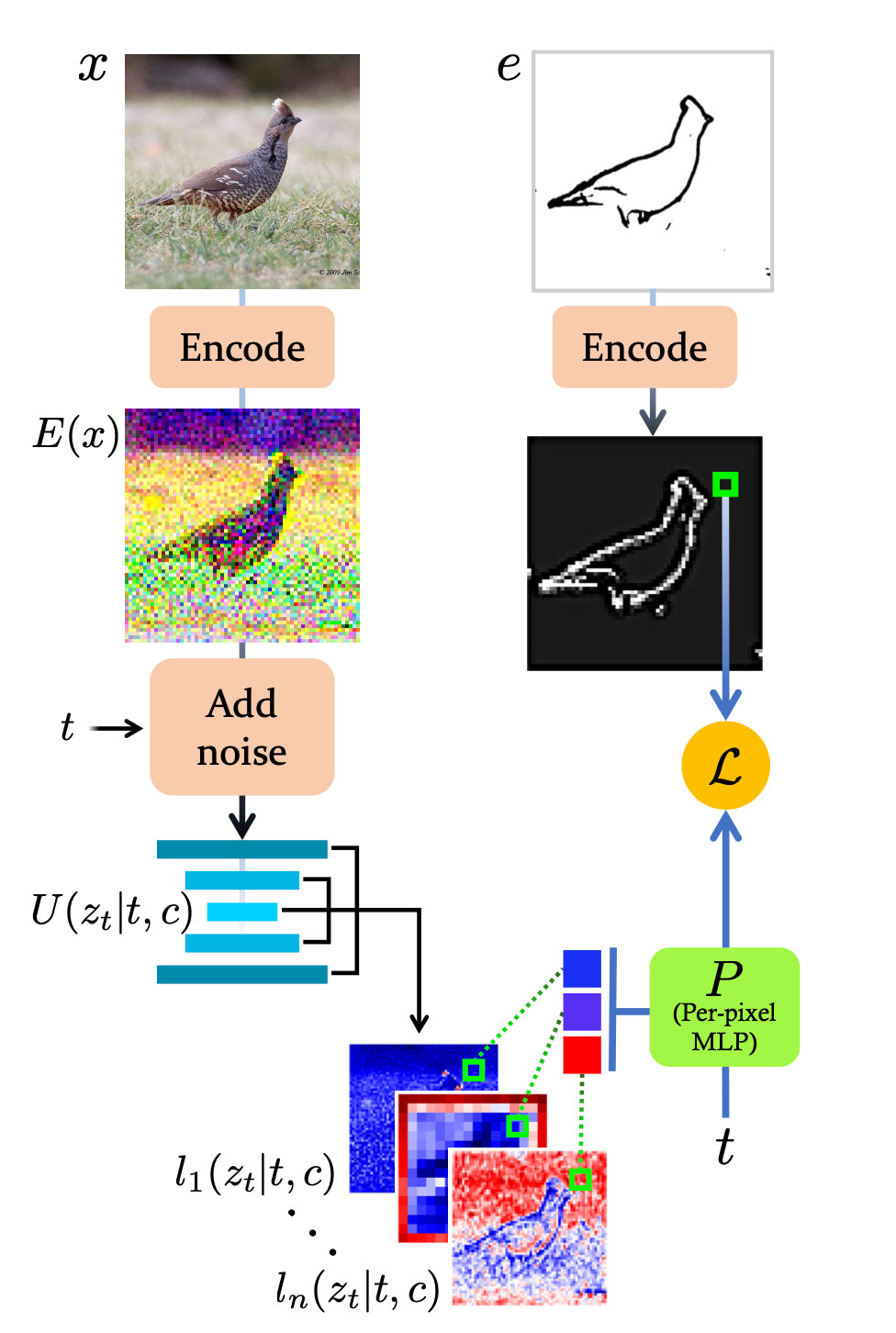

我们从扩散模型的核心 U-net 网络 U 中的固定中间层序列中提取激活值。
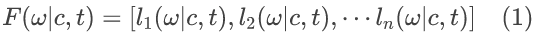
输入𝜔用上式表示选中的层数中的激活值的拼接。c代表文字提示,t代表噪声等级。考虑到不同噪声层中的激活值有不同的维度,作者将他们resize成与输入一致的大小,并在channel维度上进行拼接。MLP的输入维度是所选激活值的通道数量的和。训练所需的数据是一个包含输入图片x,边缘图e和文字标题c的三元组(x,e,c)。使用LDM的编码器对输入图片和边缘图进行预处理,为了使用相同的编码器,边缘图被复制了三遍转为三通道。U-Net实际上的输入是编码且加噪后的 zt = αtE(x) + μt. ξ ≤ αt,μt≤1是由扩散模型的噪声调度决定的混合标量,MLP 经过训练,将串联特征 F(zt|c,t)映射到编码边缘图 E (e)。为了考虑输入的噪声层级,MLP也接收参数t和与之对应的位置编码输出通道数和编码器的输出相同(4通道),latent-pixel的每个位置都通过P被转译到相关联的latent-edge,P的目标函数:

P会独立作用于隐空间中的每一个像素。不考虑整体,计算量比较小,A100一小时。
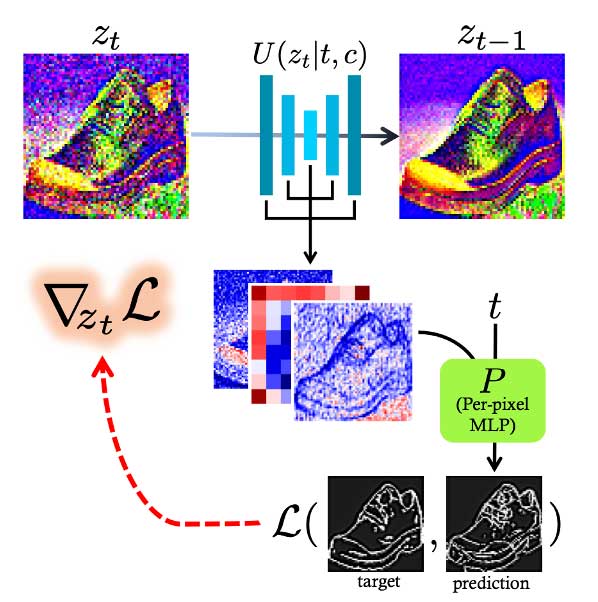
草图指导的文生图(Sketch-Guided Text-to-Image Synthesis)
在给定边缘图e和提示词c的基础上,我们希望根据边缘图获得具有较多细节的高分辨率图片。下面是这个mlp能起作用的原理:

实验与对比
实验细节
使用ImageNet数据,只用类别做caption。利用检测算法Pixel difference networks for efficient edge detection. 生成边缘,阈值0.5。潜在边缘预测器由 4 个全连接层组成,使用 ReLU 激活、批归一化,隐藏维度 512、256、128、64 ,输出维度 4。去噪模型的特征取自网络中的 9 个不同层:输入块[第 2、4、8 层],中间块[第 0、1、2 层],输出块[第 2、4、8 层]。执行训练 使用 Adam 优化器和批量大小 16 执行 3000 个步骤,在单个 A100 GPU 上花费不到一个小时。边缘引导尺度β = 1.6,停止步长S = 0.5T,prompt调节等于8(DDPM中的无分类器引导尺度) 这些参数可以根据用户要求进行修改,以在两者之间进行平衡边缘保真度和真实感。
效果与对比

上图展示了本文方法生成的一些图片,可以看到在忠实度和真实度上都很不错。
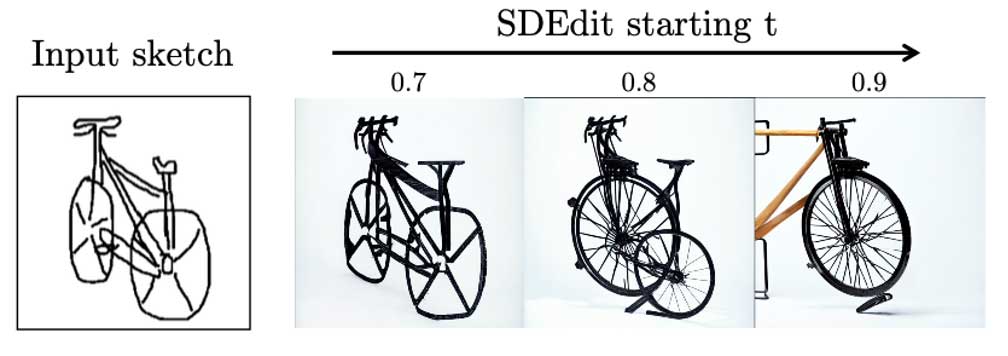
文章对比了 SDEdit,其结果如上图所示。SDEdit在输入上加噪 t 步,然后去噪声由于彩图和黑白草图的gap:t小的情况下不够真实,t 大的情况下会不忠于输入。本文也在忠实度和真实性上做了折衷,如下图,通过调整 β 来影响忠实度和真实性的侧重。

此外,作者发现轮廓在生成初期影响较大,后期细节生成时过多的边缘信息反而会影响图片质量,经实验选择在前50%的steps中加入边缘预测。
总结
提出了一种利用空间图指导预训练文本到图像模型扩散模型的技术。
本文专注于草图引导,并表明该技术可以很好地处理域外草图,这些草图可能具有与训练时看到的完全不同的多种风格。该技术的要点是轻量级 MLP 组件的每像素训练,该组件是在相当小的训练数据上进行训练的。每像素训练更像是一个差分边缘检测器,与常见的每图像训练不同,它不受特定的全局草图风格的约束。
该技术依托相关的文本到图像模型扩散模型,从而为用户提供了强大的多模式草图指导技术。从某种意义上说,该技术接受丰富多样的草图风格,同时提供丰富多样的输出,用户可以直观地控制输入,并对输出进行语义控制。
局限性
容易受到局部笔画风格的影响。该技术仍然难以处理复杂而杂乱的草图,因为它平等地对待所有笔划,而没有根据其显着性或语义对它们进行优先级排序。此外,由于文本图像扩散模型是随机的,因此随机种子和输入草图之间可能存在冲突,这可能导致生成与草图不太相符的输出。对于不同的初始化以及具有混合和模糊语义的复杂场景,结果的质量可能会下降。
可以通过添加草图反转步骤来改进该技术,以便为扩散过程产生更强的种子,从而更好地让输出符合输入草图的轮廓。另一个方向是仅使用几张照片即可快速学习个性化风格。通过快速训练,潜在草图预测器可以适应艺术家的笔画风格。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。