
引言
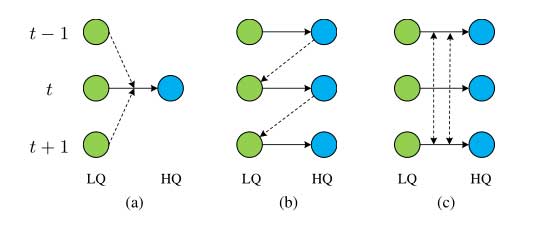

视频恢复(如视频超分辨率)旨在从低质量帧恢复高质量帧。与单个图像恢复不同,视频恢复通常需要利用多个相邻但通常不对齐的视频帧的时间信息。现有的视频恢复方法主要分为两大类:基于滑动窗口的方法和循环方法。如图 1(a) 所示,基于滑动窗口的方法通常输入多个帧来生成单个 HQ 帧,并以滑动窗口的方式处理长视频序列。在推理中,每个输入帧都要进行多次处理,导致特征利用效率低下,计算成本增加。其他一些方法是基于循环架构的。如图 1(b) 所示,循环模型主要使用之前重构的 HQ 帧进行后续的帧重构。由于循环的性质,它们有三个缺点。首先,循环方法在并行化方面受到限制,无法实现高效的分布式训练和推理。其次,虽然信息是逐帧积累的,但循环模型并不擅长长期的时间依赖性建模。一帧可能会强烈影响相邻的下一帧,但其影响会在几个时间步长后迅速消失。第三,它们在少帧视频上的性能明显下降。
本文提出了一种具有并行帧预测和长时间依赖建模能力的视频恢复变压器(VRT)。与现有的视频恢复框架相比,VRT 具有以下优点:
- 如图 1(c) 所示,在长视频序列上并行训练和测试 VRT。
- VRT 能够模拟长时间的依赖关系,在每一帧的重建过程中利用来自多个相邻帧的信息。
- VRT 提出利用互注意力机制进行特征对齐和融合。它自适应地利用支撑帧中的特征并将其融合到参考帧中,这可以看作是隐式运动估计和特征翘曲。
VRT 模型
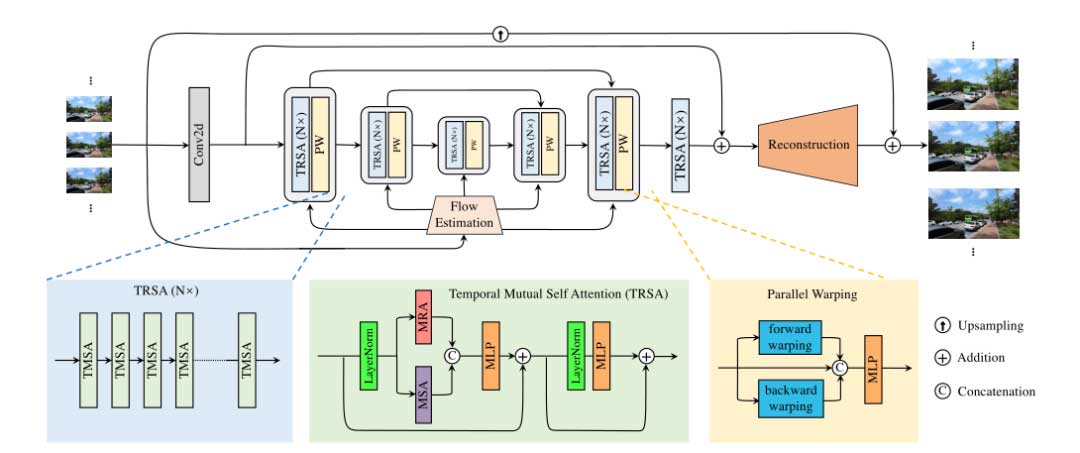
VRT 由多个尺度组成。首先通过单次空间二维卷积提取浅层特征。之后,通过两种模块进行多尺度特征提取、对齐和融合:时间互自注意(TMSA)和并行扭曲。最后,加入多个 TMSA 模块进行特征进一步细化,得到深度特征。
VRT 通过添加浅特征和深度特征来重建 HQ 帧。此外,为了减轻特征学习的负担,采用了全局残差学习,只预测双线性上采样 LQ 序列与 ground-truth HQ 序列之间的残差。在实践中,不同的恢复任务使用不同的重建模块。对于视频超分辨率,使用亚像素卷积层以 s 的比例因子对特征进行上采样。对于视频去模糊,单个卷积层就足以进行重建。除此之外,所有任务的架构设计都是相同的。
本文采用 Charbonnier 损失,其中 ϵ 是经验设定为 10-3 的常数:
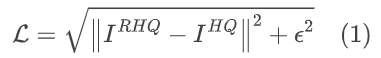
TMSA 模块
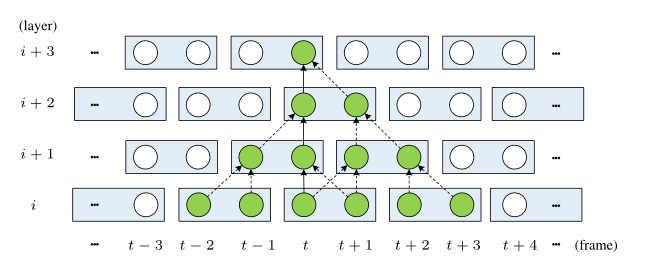
TMSA 将视频分割成小片段,利用互注意进行联合的运动估计、特征对齐和特征融合,利用自注意进行特征提取。设 X 表示两个帧,这两个帧可以分为 X1 和 X2。在 X1 和 X2 上使用多头互注意 (MMA) 两次:将 X1 向 X2 扭曲,将 X2 向 X1 扭曲。将扭曲的特征组合起来,然后与多头自注意 (MSA) 的结果进行连接,然后使用多层感知器 (MLP) 进行降维。之后,添加另一个 MLP 进行进一步的特征转换。此外,还使用了两个 LayerNorm (LN) 层和两个残差连接。整个过程制定如下:


并行扭曲


实验
实验设置
对于视频 SR,本文使用 4 个尺度的 VRT。在每个尺度上,堆叠 8 个 TMSA 模块,其中最后两个模块使用的时间窗口大小为 8。空间窗口大小 M × M,头部大小 h,通道大小 C 分别设置为 8 × 8 , 6 和 120。经过 7 个多尺度特征提取阶段,在重建前添加 24 个 TMSA 模块(仅自注意)进行进一步的特征提取。
实验结果
在视频超分辨率、视频去模糊、视频去噪、视频帧插值和时空视频超分辨率 5 个任务上的实验结果表明,VRT 在 14 个基准数据集上的性能明显优于现有方法(最高达 2.16dB)。
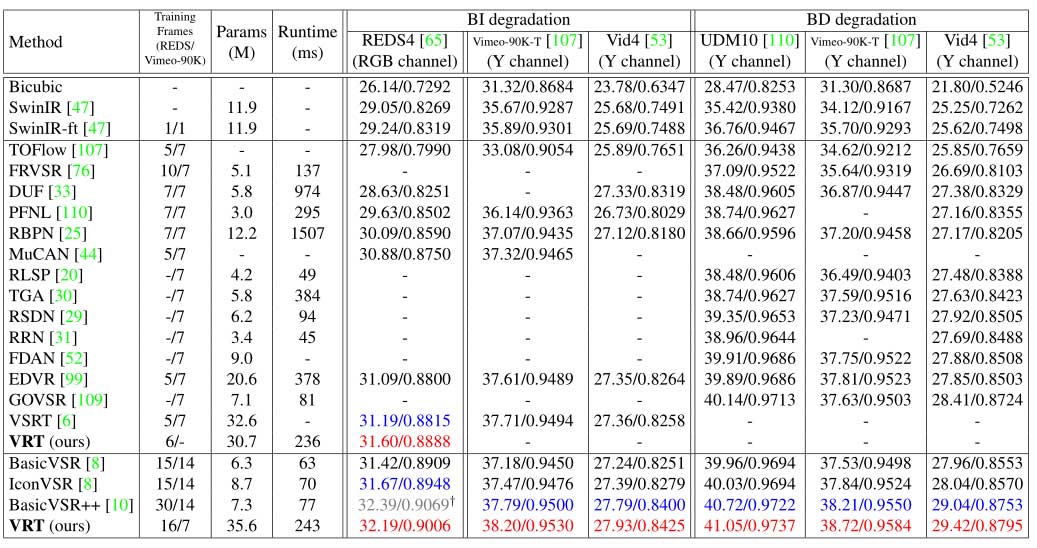
视频超分辨率:与最先进的图像和视频 SR 方法相比,VRT 在双三次 (BI) 和模糊下采样 (BD) 方面都达到了最佳性能。其中,当 VRT 在较长的序列上训练时,表现出良好的时间建模潜力,PSNR 进一步提高了 0.52dB。循环模型在短序列上往往会出现显著的性能下降。相比之下,VRT 在短序列和长序列上都表现良好。
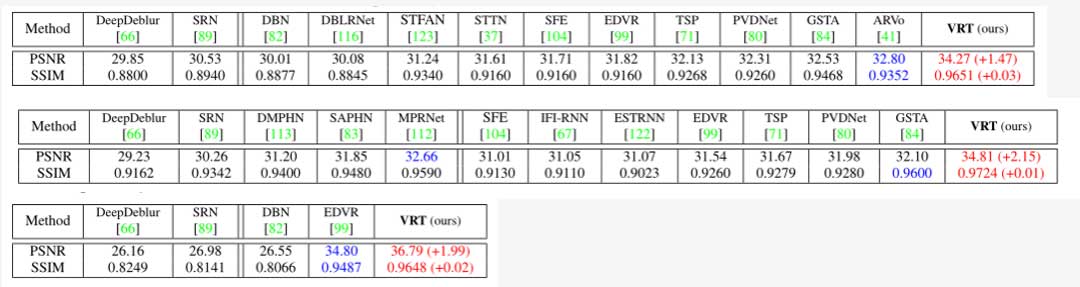
视频去模糊:在 DVD,GoPro 和 REDS 数据集上进行了实验,VRT 达到了最好的性能。值得注意的是,在评估过程中,没有使用任何预处理技术,如序列截断和图像对齐。
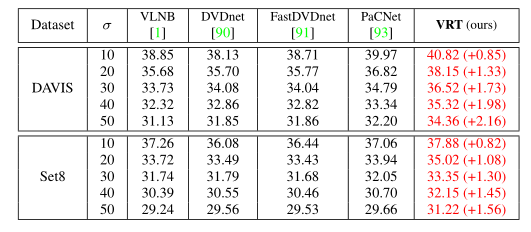
视频去噪:在 DAVIS 数据集上训练了一个噪声水平 σ∈[0,50] 的非盲模型,并在不同的噪声水平上对其进行了测试。上表显示了 VRT 在两个基准数据集上相对于现有方法的优越性。尽管 PaCNet 针对不同的噪声水平分别训练不同的模型,VRT 仍能将 PSNR 提高 0.82 ~ 2.16 dB。
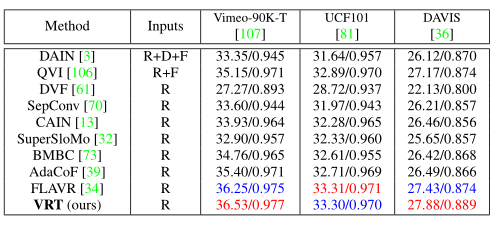
视频帧插值:在 Vimeo-90K 上训练模型进行单帧插值,并在 Vimeo-90K-T、UCF101 和 DAVIS 生成的五元组上进行测试。VRT 在所有数据集上都取得了最佳或具有竞争力的性能,包括使用深度图或光流的数据集。在模型尺寸上,VRT 只有 9900 万个参数,远远小于最近最好的模型 FLAVR(42.4 万个)。
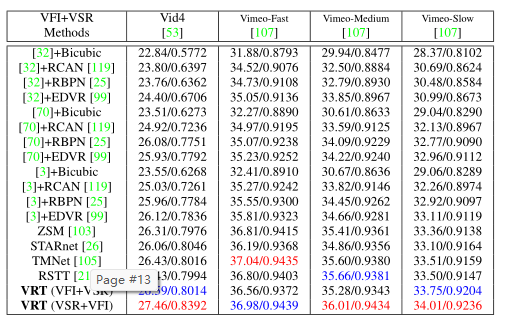
时空视频超分辨率:在视频SR (VSR)和视频帧插值(VFI)预训练模型的基础上,采用 VFI + VSR 和 VSR + VFI 两种方式级联 VRT 模型,直接测试 VRT 在时空视频超分辨率上的性能。尽管 VRT 是一个两阶段模型,并且没有专门针对该任务进行训练,但它为时空视频超分辨率提供了一个强大的基线。特别是,在 Vid4 数据集上,它将 PSNR 提高了 1.03dB。
来源:arXiv
论文题目:VRT: A Video Restoration Transformer
项目链接:https://github.com/JingyunLiang/VRT
作者:Jingyun Liang,Jiezhang Cao,Yuchen Fan,Kai Zhang,Rakesh Ranjan, Yawei Li,Radu Timofte,Luc Van Gool
内容整理:王妍
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。