
本文主要讨论了基于深度学习的图像压缩编码方法(Learned Image Compression, LIC),通过在损失函数中引入相关性损失(correlation loss),强制使潜在变量在空间上去相关,从而能更好地拟合独立概率模型。实验表明,本文提出的方法可以轻松地集成到现有的LIC方法中,在性能和计算复杂性之间实现了更好的平衡,避免了传统自回归模型的一些复杂性问题。
题目:Towards Efficient Image Compression Without Autoregressive Models
作者:Muhammad Salman Ali, Yeongwoong Kim, Maryam Qamar et al.
来源:NeurIPS 2023
文章地址:https://openreview.net/forum?id=1ihGy9vAIg
内容整理:令潇越
引言
目前的SOTA LIC方法采用变换编码策略进行有损图像压缩,具体地说,首先将图像像素映射到一个量化的潜在空间中,然后使用熵编码方法进行无损压缩。这种方法的一个关键部分是基于超先验的熵模型,用于估计潜在变量的联合概率分布,其中存在一个基本假设:潜在变量元素在空间位置上的概率是相互独立的。然而,这一假设与潜在空间高度相关的实际特性相矛盾,导致实际分布与假设分布之间存在差异。
为了减小这种差异,提出了基于自回归上下文模型的方法,尽管这提高了模型的整体性能,但引入了顺序依赖性,使其大大增加了计算复杂性和解码时间,阻碍了在实际场景中的应用。为了解决这一问题,一系列研究尝试放弃自回归方法,通过改进上下文模型来提高效率,例如Channel-wise autoregressive entropy models for learned image compression中提出的通道级自回归熵模型(ChARM)通过使用通道级自回归减少了原始上下文模型中的元素级串行处理;Checkerboard context model for efficient learned image compression提出了一种可并行化解码的棋盘格上下文模型(Checkerboard)。然而,这些方法的计算效率提升是以相对于自回归模型而言的率失真性能降低为代价的。
考虑到超先验架构存在一个隐含的假设:元素的空间位置独立性,因此本文从改进超先验架构的有效性角度出发,提出了相关性损失,用以约束模型降低空间相关性,从而能更好地拟合独立概率模型,使超先验的假设分布能够更好地拟合真实分布。本文的主要贡献如下:
- 本文的工作首次采取了从未在LIC领域尝试过的去除潜在变量空间相关性的方法,缩小了假设分布和实际分布之间的差异。
- 本文的方法只修改了损失函数,因此不会增加额外的内存或计算复杂性。
- 本文提出的相关性损失可以作为插件应用于现有的LIC方法,实验表明,本文方法与现有模型相结合实现了率失真性能的改善,达到了性能和复杂性之间最佳的trade-off。
模型
整体架构
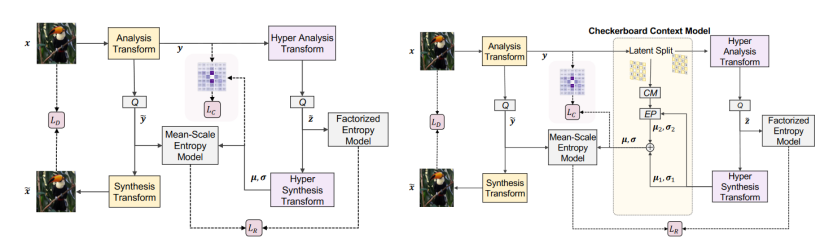

图1是在现有的工作中使用本文的相关性损失的示意图,左图是与基本的超先验结构相结合,右图是与Checkerboard模型相结合。如图1所示,本文提出的方法不用改动原有的模型结构,只需要在潜在空间计算潜在变量 y 的空间相关性,将这一项加入损失函数即可。
相关性损失的计算
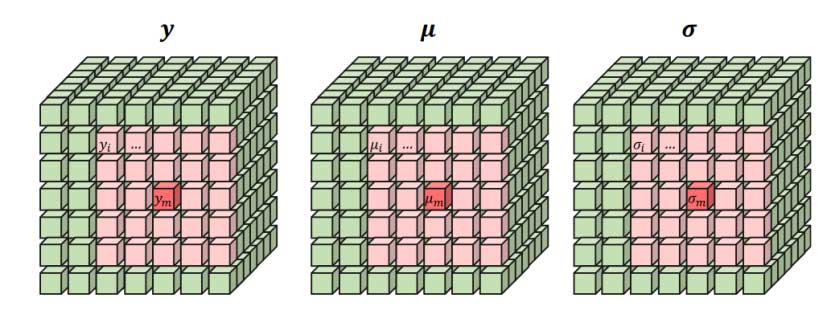
本文提出的相关性损失通过在潜在空间中使用滑动窗口计算得到。图2是本文所提出的相关性损失的计算示意图,y 表示潜在变量空间,μ 和 σ 表示超先验预测得到的 y 的均值和标准差,粉色部分是计算相关性损失的滑动窗口,m 表示窗口中心点。
具体计算步骤可总结如下:
1. 计算单个相关性图(correlation map):对于每个中心点 m,都有一个 k x k 大小的窗口,该窗口包含了中心点 及其周围的点。在这个窗口内,首先使用预测得到的 μ 和 σ 对 y 进行标准化,然后计算中心点 m 与窗口中其他点的相关性。在整个潜在空间上以步长1滑动窗口,即可得到每个中心点的相关性。
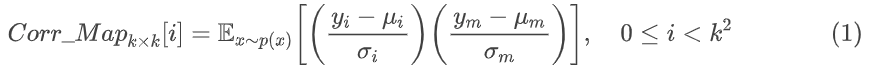
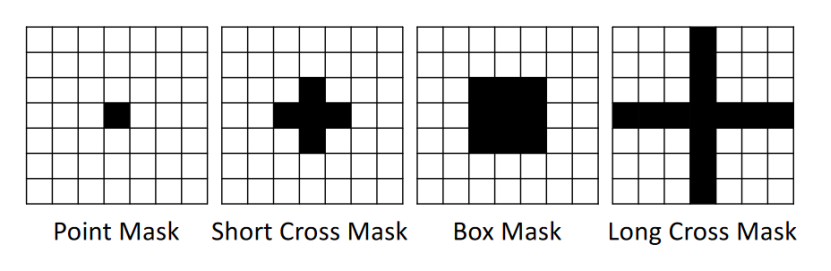
2. 应用掩膜(mask):mask用于限制计算中的自相关,首先通过将其与相关性图作Hadamard积来实现,然后对单个相关性图计算均值,得到潜在变量 y 的最终相关性图。作者设计了如图3所示的4种mask方案,用于调整相关性的计算,本文使用的是图3中的point mask方式,即仅mask中心点,这是因为中心点对应自相关是1。
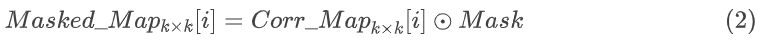
3. 相关性损失 Lcorr 的计算:最后,通过在相关性图上应用 L2 范数来计算相关性损失,这一损失衡量了模型中潜在变量之间在空间上的解相关程度。

将前面计算得到的相关性损失加入原损失函数 (4) 中,得到最终的损失函数如公式 (5) 所示,其中 α 表示相关性损失在损失函数中所占的比例。
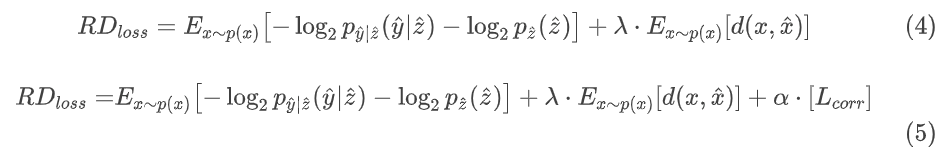
实验
实验设置
训练集:Vimeo-90k数据集 测试集:Kodak数据集
基线模型使用公式 (4) 中给出的损失函数进行训练,具有相关性损失的模型使用公式 (5) 中修改后的损失函数进行训练。
率失真性能
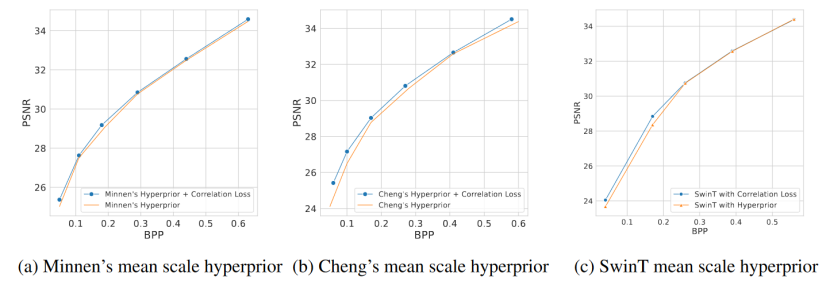
图4是将本文的相关性损失应用到现有方法中的率失真性能对比,其中选用了三种基线方法:(a) Minnen’s Hyperior, (b) Cheng’s Hyperprior, (c) Swin-Transformer Hyperprior,应用相关性损失相对于基线模型分别提升了3.2%,9.5%,4.8%的BD rate。

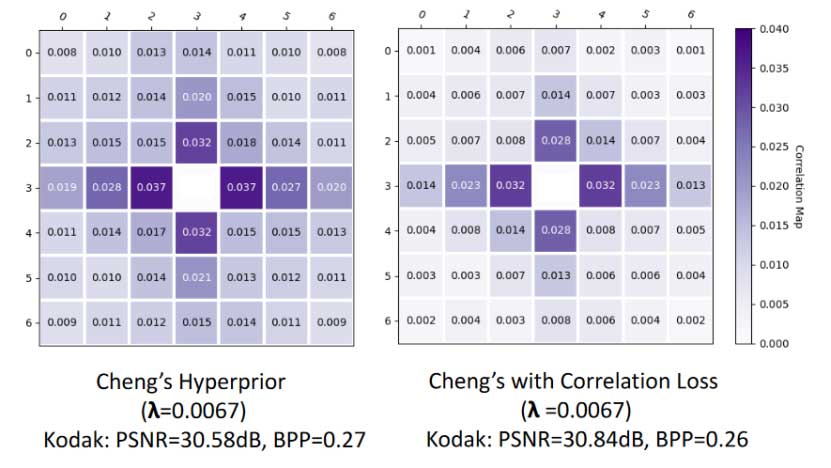
图5和图6分别是图像重建质量和空间相关性的可视化结果。如图6所示,应用了本文的方法之后,潜在变量空间位置上的相关性明显降低了,空间冗余更少。如图5所示,降低潜在变量的空间位置冗余有助于提高图像重建质量。
复杂性
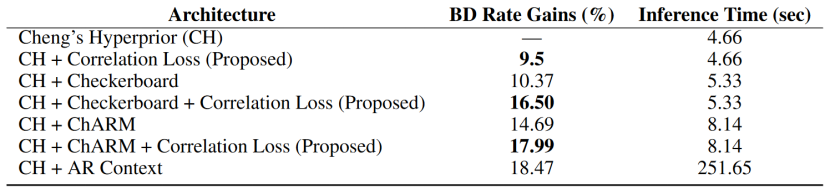
本文引入相关性损失最主要的优势就是不用增加任何的复杂性,复杂性比较的实验结果如表1所示,将相关损失应用于 Cheng 2020 的超先验模型可产生与结合上下文模型方法相当的性能改进。
- 对比CH+AR和CH+correlation loss:本文的方法实现的码率增益是自回归模型的一半,但是模型推理时间仅仅是自回归方法的1/55。
- 对比CH+Checkerboard和CH+Checkerboard+correlation loss:将本文的方法应用于Checkerboard模型中,可以达到自回归模型 BD-Rate 增益的 90%,同时模型推理时间是自回归方法的1/50。
- 对比CH+ChARM和CH+ChARM+correlation loss:将本文的方法应用于ChARM模型中,可以达到自回归模型 BD-Rate 增益的 98%,但计算速度比自回归方法快了大约30倍。
消融实验
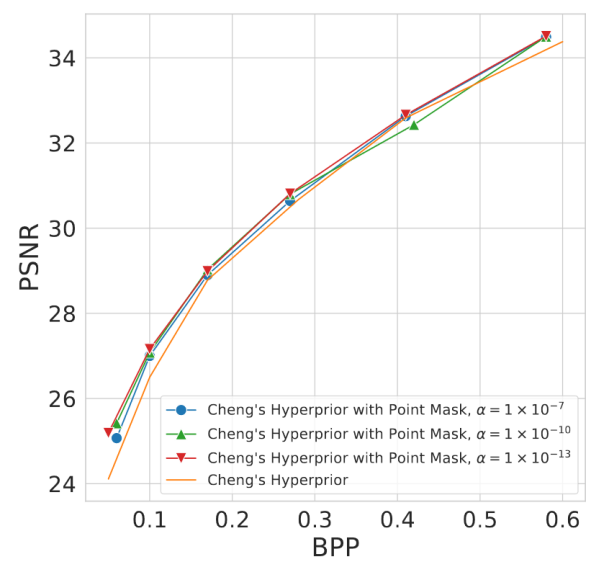
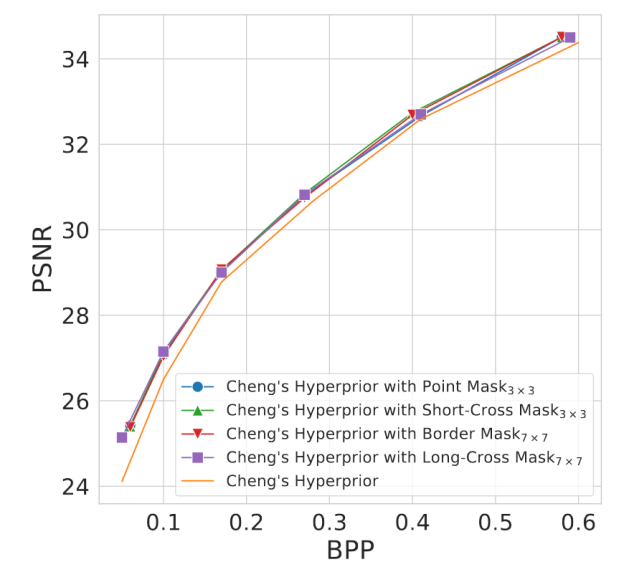
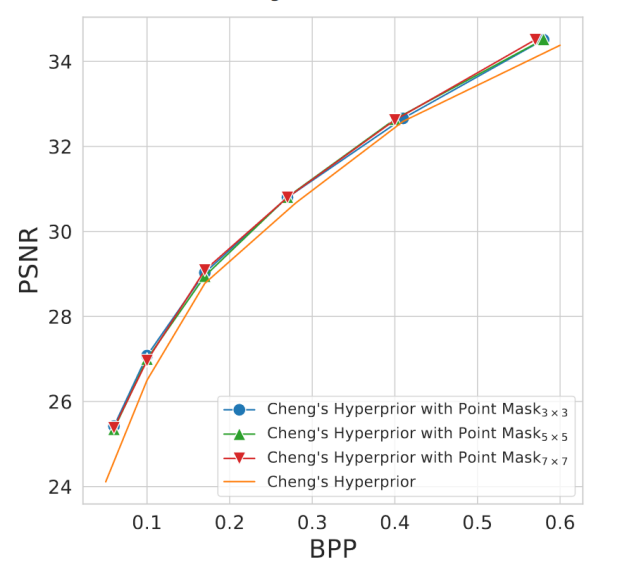
作者进行了三组消融实验,包括 α 值的大小,mask 类型和相关性图的窗口大小,实验结果分别如图7-图9所示。实验证明,损失函数中相关性损失的权重 α 的大小选为 1 x 10-13,mask 类型选为 point mask 时效果最佳。而窗口的大小对实验结果的影响较小,为了计算简便,本文选择 3 x 3 的窗口大小。
结论
由于基于超先验的熵模型假设潜在空间的概率独立,导致实际分布与假设分布之间存在差异。为了减小这一差异,本文提出了相关性损失,通过降低潜在空间中相邻元素之间的相关性,更从而能够更好地拟合空间独立概率模型。
本文的损失函数无需进行任何模型结构或容量的更改,可以作为现有LIC方法的插件。实验表明,本文所提出的方法在不修改熵模型和增加推理时间的情况下,显著提高了率失真性能,在性能和计算复杂性之间取得了更好的 trade-off 。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。