
内容摘要:C3 方法基于 COOL-CHIC,并对图像进行了几项简单而有效的改进。作者进一步开发了将 C3 应用于视频的新方法。在 CLIC2020 图像基准上,我们的 RD 性能与 H.266 编解码器的参考实现 VTM 相当,解码 MACs/pixel 小于 3k。在 UVG 视频数据集上,我们的 RD 性能与 VCT 不相上下,后者是一种成熟的神经视频编解码器,解码 MACs/pixel 小于 5k。
论文名称:High-performance and low-complexity neural compression from a single image or video
作者及机构:Hyunjik Kim*, Matthias Bauer*, Lucas Theis, Jonathan Richard Schwarz, Emilien Dupont* Google DeepMind
论文链接:https://arxiv.org/abs/2312.02753
整理人:何冰
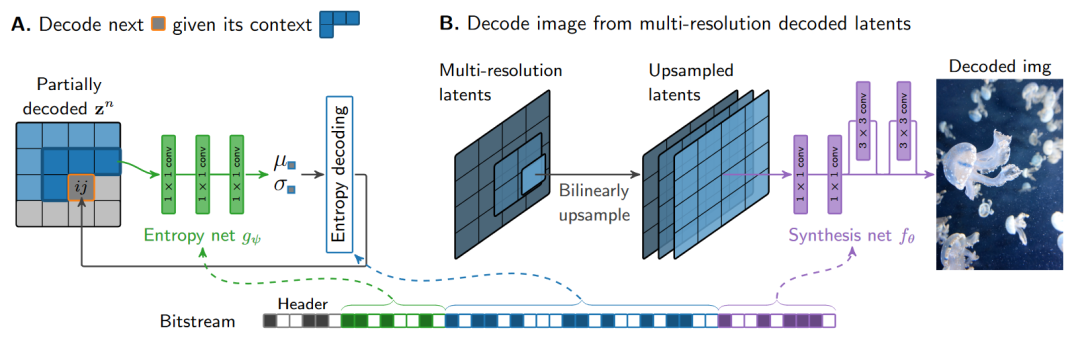
整体架构
C3 整体架构与 C1, C2 相似,模型工作流程不再赘述。生成网络 继承了 C2 的改进,使用线性层和卷积层的混合。升采样模块则使用 C1 中的双线性插值,升采样模块不含可学习参数。

主要改进
全文带来最大性能提升的改进是其模型优化过程的改进,当然文章也真对模型本身做了一些改进,并且提供了较为详细的消融实验。具体来讲,soft-rounding, Kumaraswamy noise, GELU activation 提供了最主要的增益。
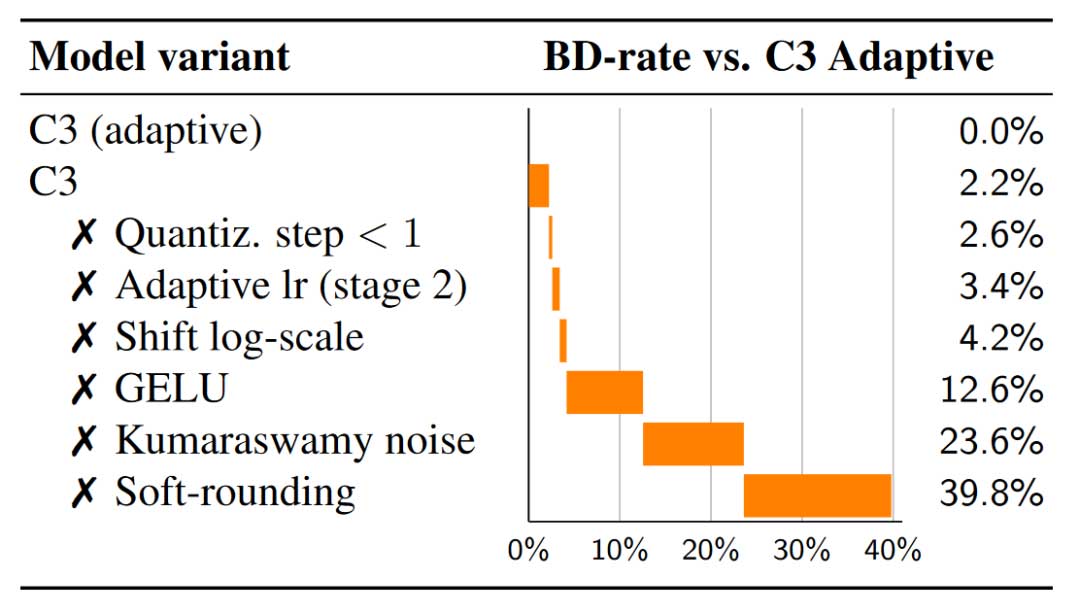
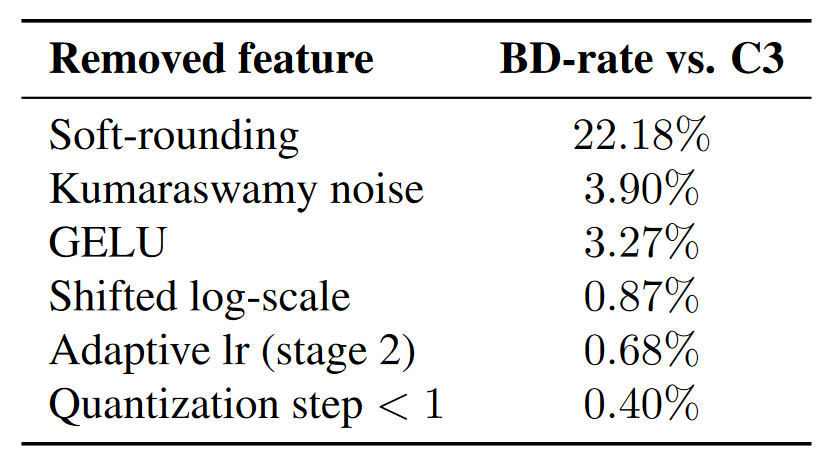
优化训练流程
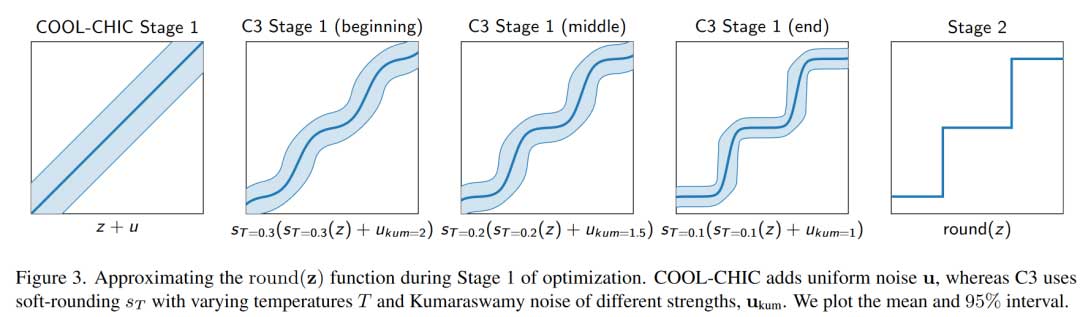
COOL-CHIC 和 C2 使用两阶段训练流程,在第一段中,前向传播时向参数添加均匀噪声以弱化后续量化带来的性能的影响;在第二段中,则使用 STE 方法,即前向传播时使用量化后的数值,而反向传播则使用量化前的梯度和数值,C2 在这一步做出了 -STE 的改进。
C3 则使用软取整的技术模糊了分段训练的流程。通过在阶段一训练中调整软取整操作温度,来实现逐渐向真正量化逼近。第二段使用温度很低的软取整操作进行。
Soft-rounding(stage 1)
其数学表达为
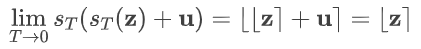
st 具体形式在文中附录有详细的讨论,简单直观理解,温度越高,在经过 soft-rounding 变化后越接近没有变化,而温度越低,soft-rounding 变化越接近 hard-rounding。
Kumaraswamy noise(stage 2)
由于 soft-rounding 改变了数据分布,因此先前的值域在 0-1 间的均匀噪声分布未必会获得最好的结果,作者在如何选取噪声分布的部分也做了比较详细的讨论和实验,最终选取了Kumaraswamy noise,并且带来了性能增益。其可视化如下图所示。
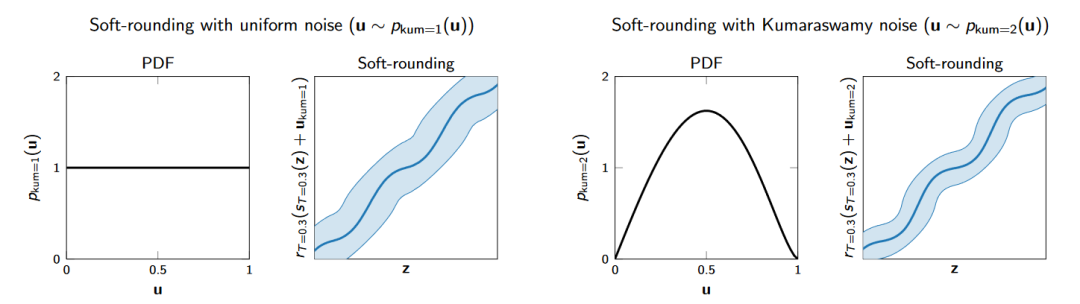
其它改进
采用了 Cosine decay schedule 学习率调整策略。(stage 1)
C1 中的 stage 2 中添加噪声与 stage 1 中量化步长相匹配,然而实验发现在 stage 2 中使用更小的量化步长会改善模型性能。(stage 1&2)
类似于 C2 的操作进行 stage 2 的训练。C2 是手动设置梯度为 ϵ , C3 使用温度很低的软量化函数实现了相似的功能。(stage 2)
当 R-D 性能没有更新时,会进一步减小 lr。(stage 2)
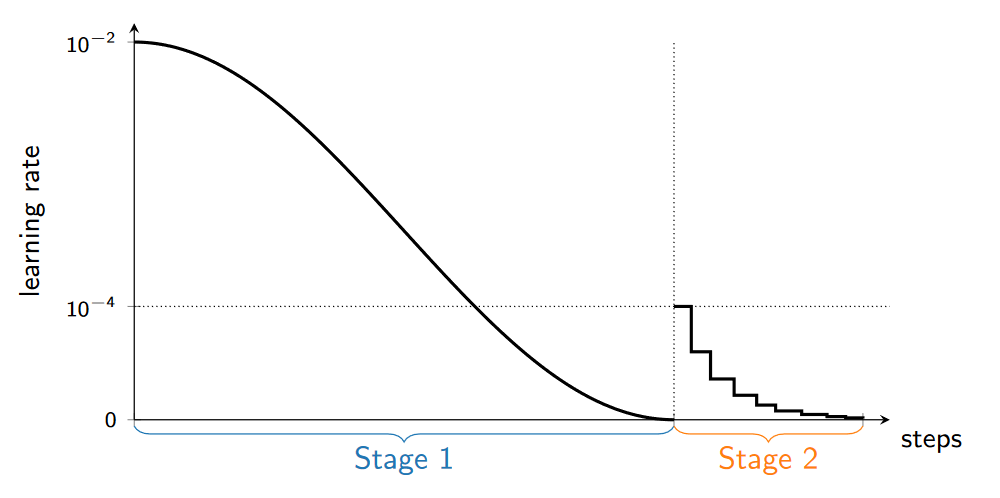
模型改进
条件熵模型
此前的自回归模块 ARM 在解码 latents 时,需要向 ARM 输入同层级的已解码的 latents 。C3 假设层级间的 latents 仍存在关联,因此其在层级维度上拓展了输入,将前一级的 latents 输入 ARM 中。并且 C3 提供了一个选择,可以通过使用 FiLM 层,来使得网络大小与图像分辨率相关。
激活函数调整
实验经验表明,小且简单的网络使用 GELU 激活函数效果会优于 ReLU 激活函数。
改变熵模型输出的倍率
也是实验经验,熵模型输出的 μ,σ, 在指数化之前移动预测的对数尺度可以持续提高性能。通过改进优化,我们还可以使用比 COOL-CHIC 更大的初始化尺度来提高性能。
图像适应性
使用不同的模型结构来实现不同码率的压缩。举例来讲,当想获取低码率压缩结果时,避免使用最高分辨率的 latent 可以获得更好的结果。
视频方法
模型调整
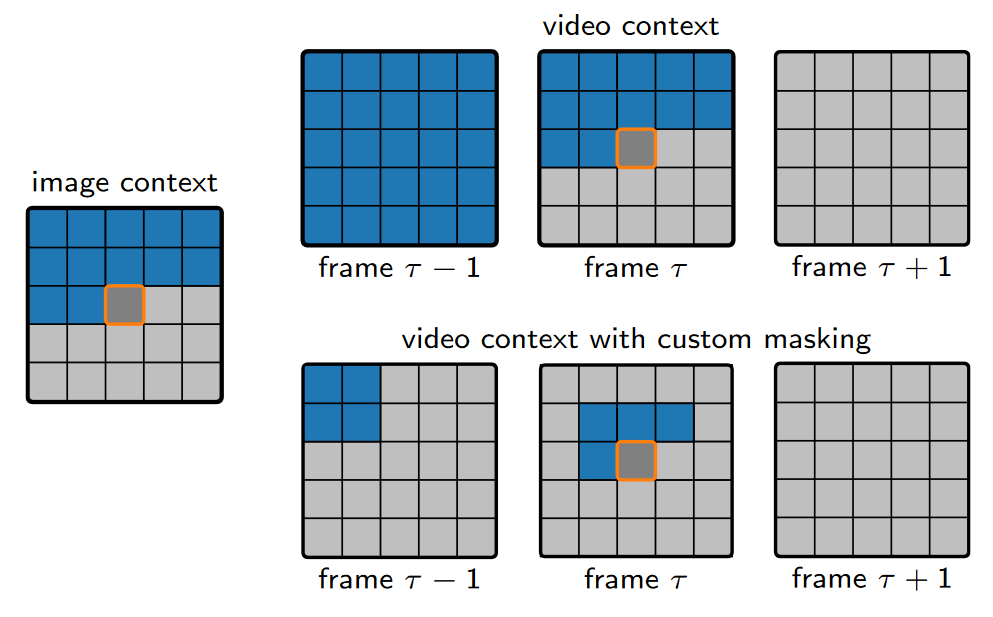

输出调整
输出为视频 patches, 大尺寸的 patch 在低码率下性能更好,小尺寸的 patch 在高码率下性能更好。
ARM 更大的可学习的感受野
运动剧烈的视频若想借鉴帧间信息,需要使用更大的感受野在前一帧进行搜索,然而简单地增加感受野效率很低,因此如 custom masking 所示,其帧间的感受野是通过学习得到的。
实验结果
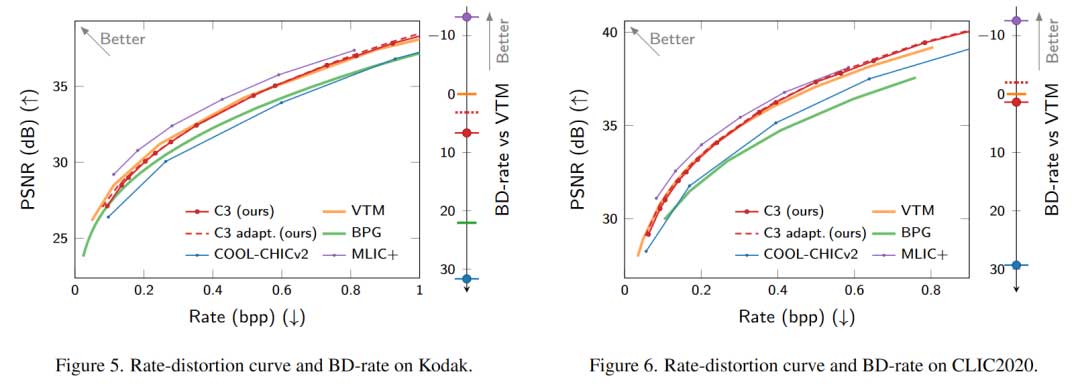
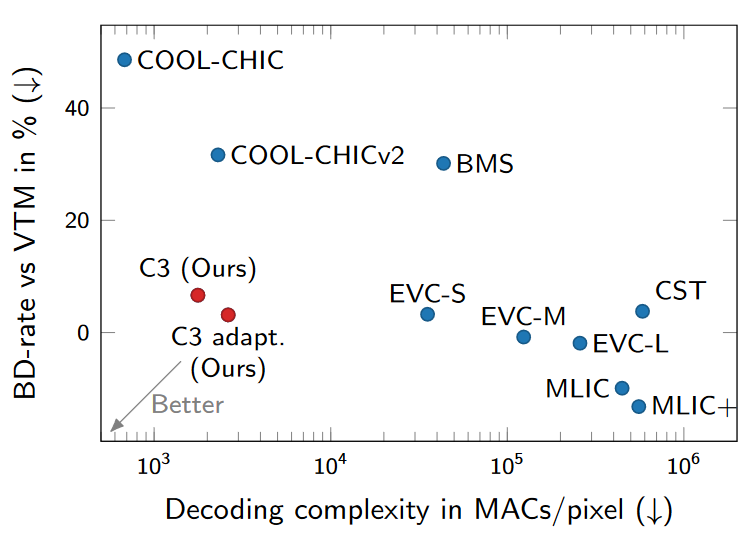
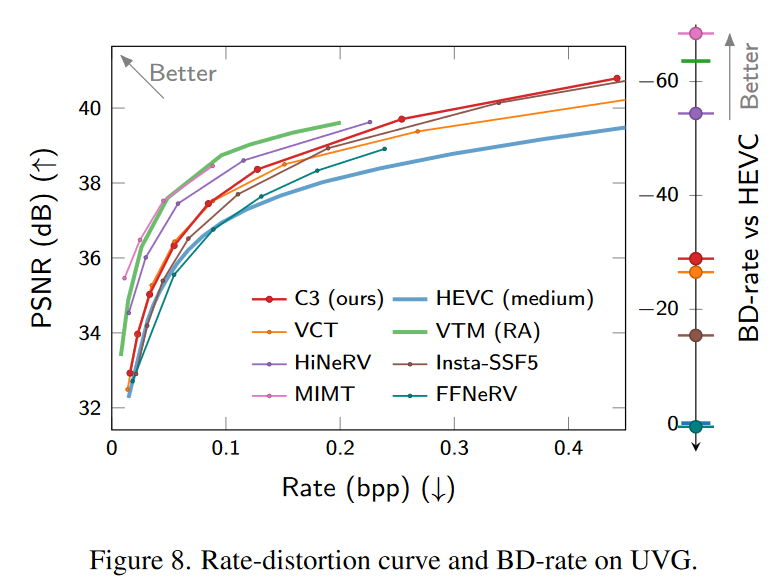
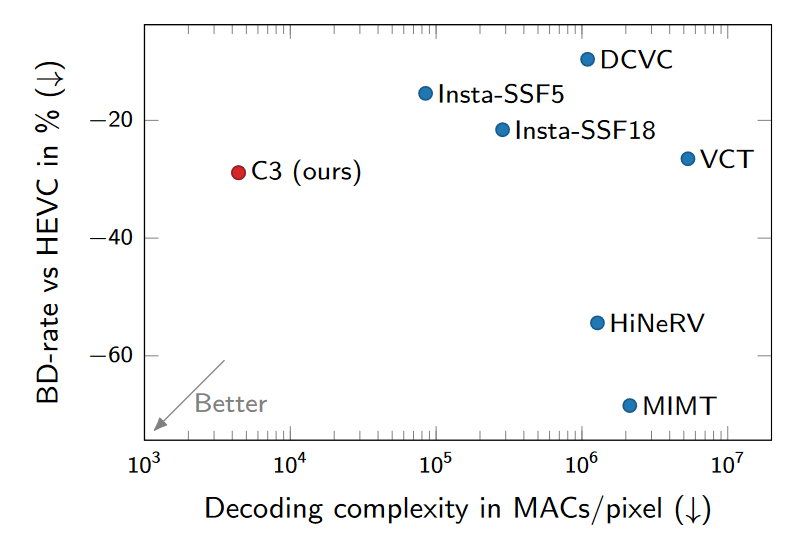
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。