


研究意义
大语言模型如ChatGPT具有强大的跨任务泛化能力,可以不在目标任务数据上进行训练仅仅依靠输入的文本指令就可以完成各种各样的任务。实现该能力的关键技术就是指令微调。以往指令微调方法所使用的指令文本多为任务定义缺少实现任务的中间过程,可能导致在较小的语言模型上效果不佳。因此,我们提出使用逐步指导(Step-by-Step Instruction)来提升指令文本,进而增强模型的跨任务泛化能力。
本文工作
在我们工作中,我们提出了使用逐步指导(Step-by-Step Instruction)来增强模型的跨任务泛化能力。逐步指导是对于某个任务的通用的解决步骤,每一步是分解好的子任务,按步完成就可以实现最终的任务目标。但是,获取逐步指导的标注成本很高,因此我们提出使用强大的语言模型来自动化生成逐步指导。具体我们采用了ChatGPT作为使用的语言模型,一方面是因为其惊人的解决问题的能力,因为我们利用其来分解原始指令中目标任务目标,提供解决问题的步骤,需要模型具有较强的解决问题的能力。另一方面是其令人印象深刻的指令理解能力,因为需要其充分理解原始指令背后的需求。为了获取高质量的逐步指导数据,我们根据ChatGPT多轮交互的特性进一步通过多次交互迭代地对初始获取到的逐步指导数据进行修正。最后,我们利用生成好的高质量逐步指导来增强原始指令进而对语言模型进行指令微调以提升语言模型的跨任务泛化性。整体方法流程如图1所示。
本文的创新点如下:
(1) 提出使用逐步指导来增强语言模型的跨任务泛化能力;
(2) 提出基于ChatGPT的自动化的获取和修正逐步指导的方法来生成高质量的逐步指导数据;
(3) 构建了带有逐步指导的指令数据集并且对于每个逐步指导数据提供了对应的人工质量标注。
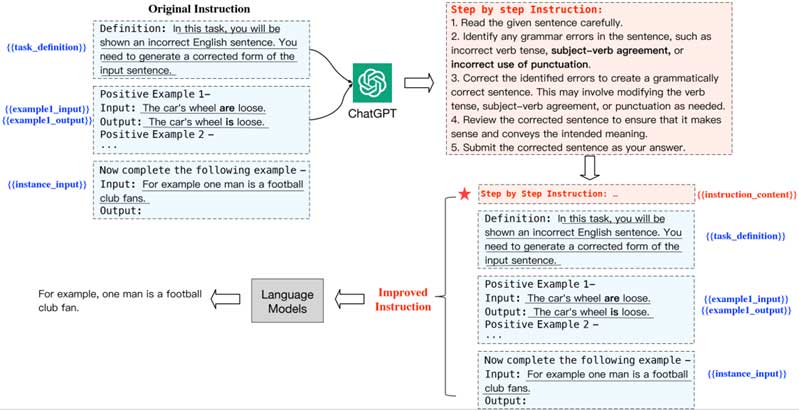
实验结果
为了评估方法的有效性,我们公开的SUPER-NATURALINSTRUCTIONS数据集做了实验。SUPER-NATURALINSTRUCTIONS数据集训练集包含757个训练任务,测试集合包含119个测试任务。该任务要求语言模型通过在757个训练任务上的指令微调训练学习到指令跟随能力并泛化到119个未曾见过的任务上。我们方法(Step-by-Step Instruction Tuning)与对比方法(Tk-Instruct等)的结果如表1所示。
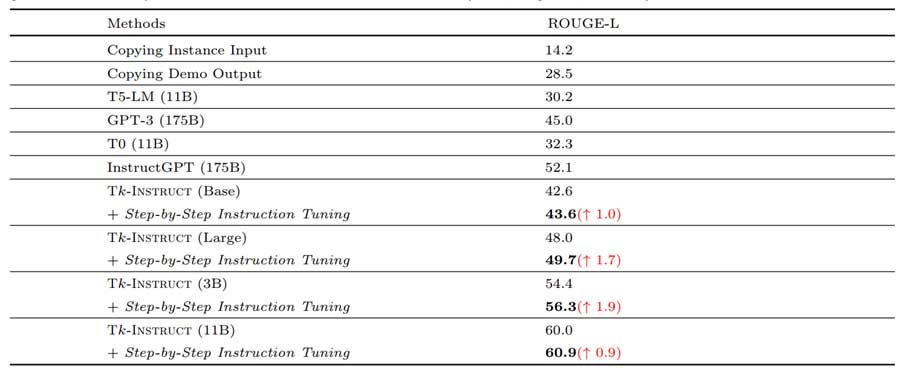
由表1可以看出我们的方法通过利用逐步指导增强指令数据在Base,Large,3B和11B等多个模型规模下获得了更好跨任务泛化性能。对于未来工作,我们认为进一步提升指令数据的质量,完善指令的形式,以及更好任务微调形式如显式的要求模型一步步顺序完成步骤都有可能进一步提升语言模型的跨任务泛化性能。
出版信息
Yang WU, Yanyan ZHAO, Zhongyang LI, Bing QIN & Kai XIONG. Improving Cross-Task Generalization with Step-by-Step Instructions. Sci China Inf Sci.
全文链接:https://www.sciengine.com/SCIS/doi/10.1007/s11432-023-3911-2;JSESSIONID=2e376b8c-a6b9-4a0c-b499-5e599dc14096
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。