
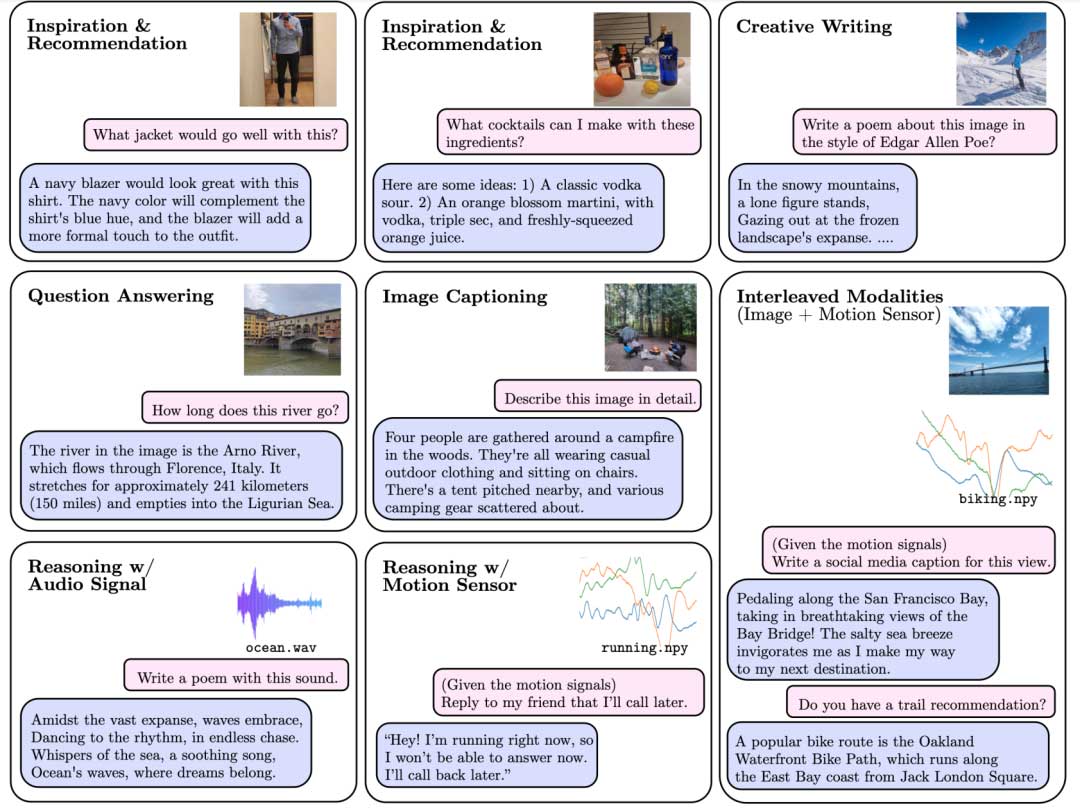
这篇文章介绍了一种名为AnyMAL的高效、可扩展的任意模态增强语言模型。AnyMAL是一个统一的模型,能够处理多种输入模态信号(例如文本、图像、视频、音频、惯性测量单元和运动传感器信号等)并生成文本响应。该模型继承了最先进的大型语言模型的强大文本推理能力,并通过预训练的对齐模块将模态特定的信号转换为联合文本空间。为了进一步增强多模态大型语言模型的能力,作者使用手动收集的多模态指令集对模型进行了微调,以涵盖简单问答任务之外的多样化主题和任务。通过广泛的实证分析(包括人类和自动评估),该研究展示了AnyMAL在各种多模态任务上的先进性能。
题目: AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model
作者: Seungwhan Moon, Andrea Madotto, Zhaojiang Lin, Tushar Nagarajan, Matt Smith, Shashank Jain, Chun-Fu Yeh, Prakash Murugesan, Peyman Heidari, Yue Liu, Kavya Srinet, Babak Damavandi, Anuj Kumar
文章地址: https://arxiv.org/abs/2309.16058
内容整理: 张俸玺
引言
大语言模型(LLMs)因其庞大的规模和复杂性而著名,显著增强了机器理解和表达人类语言的能力。LLMs的进步也推动了视觉-语言领域的显著进展,缩小了图像编码器与LLMs之间的差距,结合了它们的推理能力。之前的多模态LLM研究主要集中在结合文本和另一种模态的模型上,如文本和图像模型,或专注于未开源的专有语言模型。为了解决这些挑战,本文介绍了一种新的多模态增强语言模型(AnyMAL),它是一系列多模态编码器的集合,这些编码器被训练用于将来自不同模态(包括图像、视频、音频和IMU运动传感器数据)的数据转换为LLM的文本嵌入空间。通过扩展先前的工作,AnyMAL采用更强大的指令调优LLMs、更大的预训练模态编码器和先进的投影层来处理变长输入。
文章的主要贡献包括提出了一种构建多模态LLMs的高效可扩展解决方案,使用预训练的投影层和多种模态(如200M图像、2.2M音频、500K IMU时间序列和28M视频),所有这些都与同一个LLM对齐,从而实现了交错的多模态上下文提示。此外,还通过跨三种模态(图像、视频和音频)的多模态指令集对模型进行了进一步的微调,覆盖了超越简单问答领域的多样化、不受限制的任务。该数据集包含高质量的手动收集的指令数据,也被用作复杂多模态推理任务的基准。最佳模型在自动和人类评估中均在多种任务和模态上展现出强大的零样本性能,与文献中可用的模型相比,在VQAv2上实现了+7.0%的相对准确率提升,在零样本COCO图像说明文字上实现了8.4%的CIDEr提升,在AudioCaps上实现了14.5%的CIDEr提升。

方法
预训练
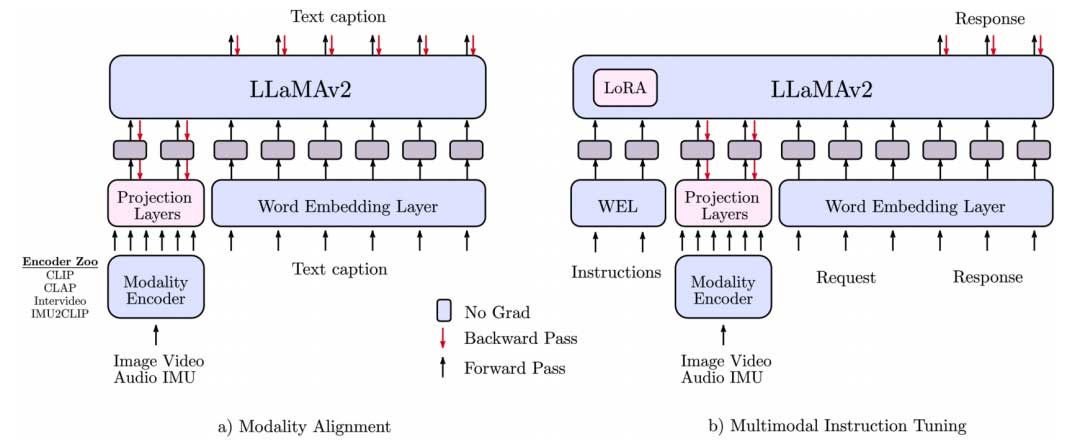
模态对齐
作者通过使用成对的多模态数据(模态特定信号和文本叙述)预训练LLMs来实现多模态理解能力(如图2所示)。具体来说,作者为每种模态训练了一个轻量级适配器,以将输入信号投影到特定LLM的文本令牌嵌入空间中。通过这种方式,LLM的文本令牌嵌入空间变成了一个联合令牌嵌入空间,令牌代表文本或其他模态。在这项工作中,用于表示每种输入模态的令牌嵌入数量是固定的,每个适配器范围从64到256。在对齐训练期间,作者冻结了底层LLM的模型参数,这使得它比从头开始进行端到端训练能更快地达到收敛,并且在推理时继承了LLM的推理能力。此外,为了最大化特征兼容性,对于每种模态,作者使用一个已经与文本嵌入空间对齐的编码器g(·)。例如,对于图像使用CLIP,对于音频信号使用CLAP,或者对于IMU信号使用IMU2CLIP。对于每对文本标题和模态(Xtext,Xmodality),作者利用投影模块通过以下目标来实现它们的对齐。
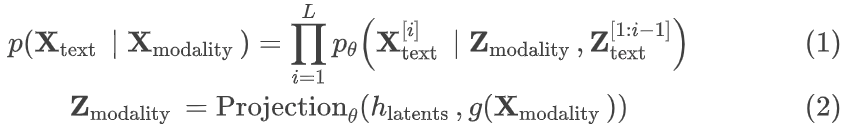
数据集
对于图像对齐,作者使用LAION-2B数据集的一个清理后的子集,通过CAT方法进行过滤,并使用任何可检测的面部模糊。对于音频对齐,作者使用了AudioSet(210万个样本)、AudioCaps(46K样本)和布料(5K样本)数据集。作者使用Ego4D数据集进行IMU和文本对齐(528K)。
量化
将预训练扩展到70亿参数模型以处理大型数据集(2亿+实例)需要大量资源,通常需要使用FSDP(全参数分片)。包装器将模型分片到多个GPU上。为了有效地扩展模型的训练,作者在多模态设置中实施了量化策略(4位和8位),在该策略中,保持LLM组件的模型冻结,只训练模态令牌生成器。这种方法将内存需求减少了一个数量级。因此,作者能够在单个80GB VRAM GPU上以4的批量大小训练70亿参数的AnyMAL。与FSDP相比,作者到所提出的量化方法在只使用一半的GPU资源的情况下达到了相同的吞吐量。作者注意到,与FSDP训练相比,这样做训练/验证损失持续更高,但这并没有影响生成质量(在推理时,作者使用原始LLM以全精度来最大化准确性)。
微调与多模态指令数据集
为了进一步提升模型针对多样化输入模态的指令遵循能力,作者使用多模态指令调整(MM-IT)数据集进行额外的微调。具体来说,作者将输入以[<指令> <模态tokens>]的形式拼接,使得响应目标同时基于文本指令和模态输入。作者进行了消融实验,包括训练投影层而不改变LLM参数,或者使用低秩适应进一步调整语言模型(LM)的行为。
作者同时使用手动收集的指令调优数据集和合成数据。
手动注释
虽然针对各种视觉问答(VQA)任务存在公开可用的第三方数据集,但作者观察到许多这些数据在多样性和质量上都不足——特别是在将大语言模型(LLMs)对齐到超越简单问答查询的多样化多模态指令遵循任务时(例如,“使用这张图片创作一首诗”,“从这张传单上提取电话号码”)。因此,作者专注于收集60,000个高质量多模态指令调整数据的例子,用于多种模态,如表1所示。具体来说,作者使用各种Creative Commons许可的、公开可用的图片,并用手动创建的指令和响应来增强这些图片。要求标注者提供严格的多模态指令和答案对,这样的查询无法在不理解伴随的多模态上下文的情况下回答。

合成增强
除了上述高质量的真实指令调整数据外,作者还使用LLaMA-2(70亿参数)模型扩展了数据集,采用了LLaVA提出的类似方法。具体来说,作者使用图像的文本表示(即,多个标题、边界框信息和对象)来为图像生成问题-答案对。作者在不同的领域和问题类型上生成了15万个图像-指令-响应对。注意,作者建模过程严格只使用开源模型——与使用商业服务(如ChatGPT或GPT-4)的其他工作不同。
实验
任务类型
评估模型性能的任务分为两类:(1) 给定输入模态生成标题的任务,这与预训练目标一致,主要用于理解文本与其他模态之间的对齐程度;(2) 多模态推理和指令遵循任务,旨在评估模型从核心指令调优的LLM以及多模态指令调优过程中继承的推理和指令遵循能力。
定量分析
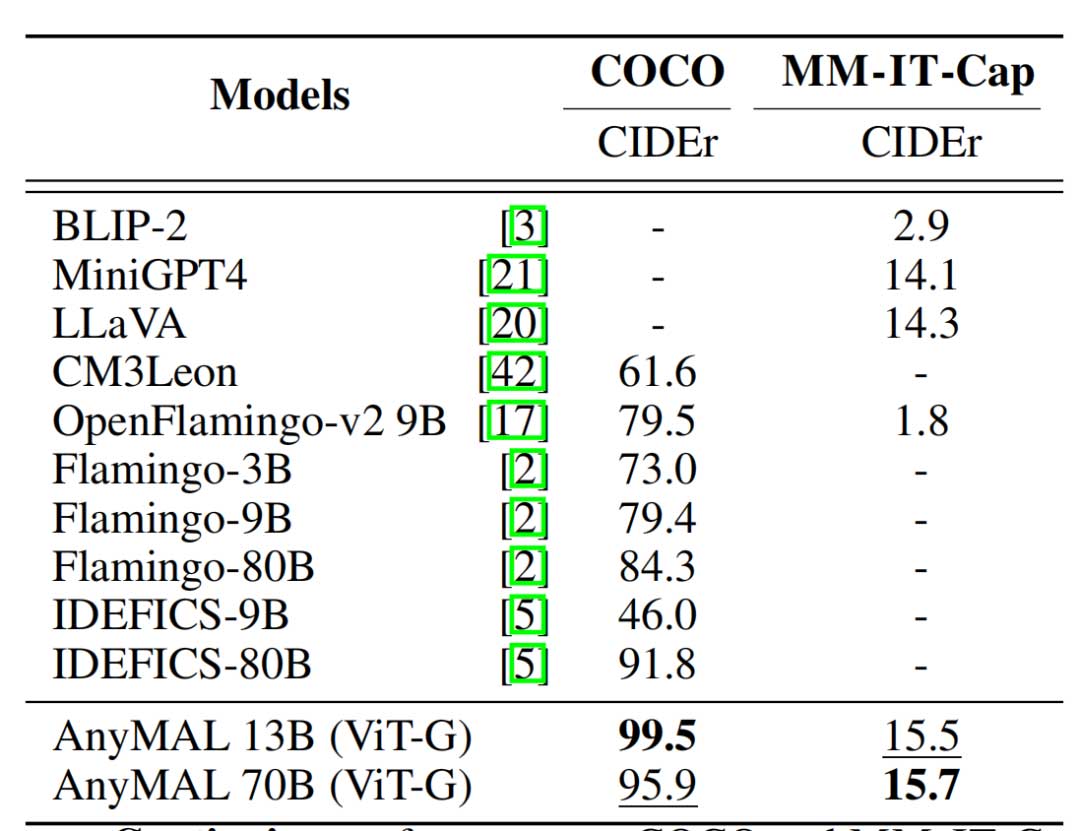
在COCO和MM-IT数据集上评估了零样本图像字幕性能。AnyMAL在两个数据集上的性能都显著优于基线模型,表明其在视觉理解能力上的优势。
人类评估
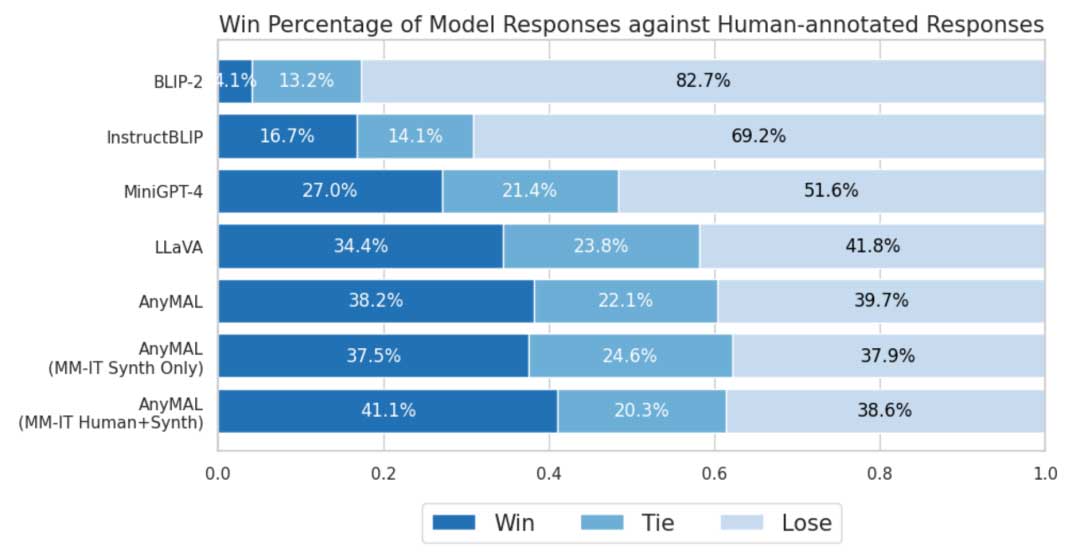
使用MM-IT数据集的多模态指令和真实答案对模型进行评估。AnyMAL在人类评估中展示了较小的与人类生成响应的差距,显示出与基线相比的竞争水平的视觉理解和推理能力。
多模态问答(VQA)基准
在多个VQA数据集上评估零样本性能,如Hateful Meme、VQAv2、TextVQA、Science QA、VizWiz和OKVQA。AnyMAL在这些任务上展现了强大的性能,与其他基线模型相比表现出色。
音频描述结果
在AudioCaps数据集上的零样本音频描述结果显示,AnyMAL在不同度量上均优于现有的最先进的音频描述模型,展现了在不同模态上的强大性能。
视频问答基准
在STAR、How2QA和NextQA视频问答基准上评估AnyMAL,模型展现了与基线模型竞争的零样本多模态推理能力,并在STAR基准上达到了最先进的性能。
定性分析
与其他视觉-语言模型(如BLIP-2、InstructBLIP、Mini-GPT4和LLaVA)相比,AnyMAL在各种示例图像和提示对上展示了强大的视觉理解能力和语言生成能力。
结论
在本文中,作者提出的AnyMAL展示了一种与AI模型交互的新颖而自然的方式,例如,提出假定用户和代理之间对世界有共享理解的问题,通过相同的视角和组合感知(例如视觉、听觉和运动线索)。提出的AnyMAL训练方式可行性地利用了开源大语言模型在多模态中的强大推理能力。
本文工作的贡献如下:(1) 作者介绍了一个大规模的多模态LLM(AnyMAL),并利用开源大预言模型资源和多模态的可扩展解决方案进行了训练。(2) 作者引入了多模态指令调整数据集(MM-IT),这是第一种类似的、包含高质量手工注释的多模态指令数据的集合。(3) 本文的实证分析展示了构建多模态推理模型的高效且可扩展方法,且考虑到了各种LLM和建模选择。
局限性
本文所提出的工作存在以下几点限制:
首先,作者所提出的因果多模态语言模型方法在与输入模态建立稳固的关联上仍面临挑战。在生成过程中,模型偶尔会更多地关注生成的文本而不是输入的图像。这导致生成的输出融入了底层LLM获取的偏见,与图像上下文相比可能会产生不准确性。尽管这可能涉及更高的计算成本, 作者期望通过额外的架构调整或解冻LLM参数来有效地解决这一限制。
其次,尽管作者大大增加了预训练数据集的大小,模型对视觉概念和实体的理解仍受到训练过程中包含的成对图像-文本数据量的限制。在仅文本的语言模型领域,通常观察到结合外部知识检索的方法能显著增强模型克服其知识限制的能力。这些方法提供了一种缓解上述限制的潜在手段。
最后,在本文中,LLM的多模态适应被限制在四种模态:图像、视频、音频和IMU信号。对于除此之外的其他模态的有效性仍需得到证实。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。