
本文提出了一种参数化模型,使用神经辐射场将自由视图图像映射到编码面部形状、表情和外观的向量空间,即 Morphable Facial NeRF。MoFaNeRF 将编码后的面部形状、表情和外观以及空间坐标和视角方向作为 MLP 的输入,并输出空间点的辐射度,用于照片级逼真的图像合成。通过引入身份特定调制和纹理编码器,我们的模型合成了准确的光度细节并显示出强大的表示能力,在基于图像的拟合、随机生成、面部装配、面部编辑和新视图合成等方面都有应用。
来源:ECCV 2022
代码链接:http://github.com/zhuhao-nju/mofanerf
论文链接:https://arxiv.org/abs/2112.02308v1
作者:Yiyu Zhuang , Hao Zhu , Xusen Sun , Xun Cao
内容整理:王睿妍
文章中指出,3D人脸建模是解决3D人脸重建、重现、解析、数字人等人脸相关视觉任务的关键问题。3D可变形模型 ( 3DMM ) 一种将人脸的形状和纹理转换为向量空间表示的参数化模型,是长期以来一直是该问题的关键解决方案。虽然 3DMM 在表示各种形状和外观方面功能强大,但需要复杂的渲染流程才能生成逼真的图像。此外,3DMM 难以对非朗伯对象(如瞳孔和胡须)进行建模。神经辐射场 ( NeRF )被提出使用隐式函数来表示静态场景的形状和外观,这在照片真实感自由视图合成任务中显示出优越性。最新进展表明,修改后的 NeRF 可以对动态人脸进行建模,或生成多样化的 3D 感知图像。但是,目前还没有办法让 NeRF 同时具有单视拟合、可控生成、面部绑定和编辑的能力。综上所述,传统的 3DMM 在表示大规模可编辑 3D 人脸方面功能强大,但缺乏逼真的渲染能力,而 NeRF 恰恰相反。
挑战
为了结合 3DMM 和 NeRF 的优点,本文旨在创建一个基于神经辐射场的面部参数化模型,以具有强大的表示能力和出色的自由视图渲染性能。面临的挑战如下:
- 如何使用神经辐射场记忆和解析超大规模人脸数据库
- 如何有效地分离参数(例如形状、外观、表情)
贡献
- 提出了第一个使用神经辐射场将自由视图图像映射到向量空间的参数模型,该模型支持可控生成和基于图像的拟合。
- 该模型精心设计网络和训练策略,最大限度地提高模型的表示能力。可以插入形状、外观和表情的分离参数,以实现平滑的可变形合成。
- 提出了将我们的模型用于多种应用的方法,包括基于图像的拟合、视图外推、面部编辑和面部绑定,并实现与最先进方法相比具有竞争力的性能。
具体实现
与以前的 NeRF 不同,我们的方法是第一个在大规模多视图人脸数据集上训练的面部神经辐射场参数化模型。
总体框架图
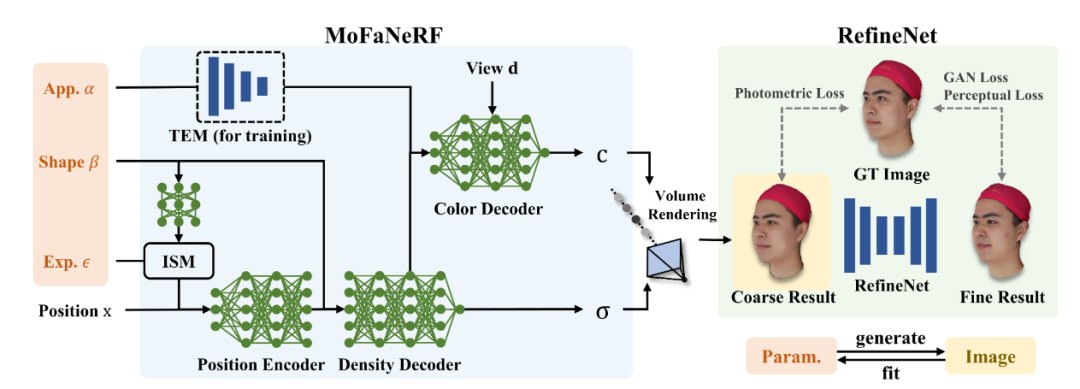

如上图所示,MoFaNeRF 的主体框架主要由位置编码器 (position encoder)、颜色解码器 (color decoder)、体密度解码器 ( density decoder )和特定身份调制模块 ISM(identity-specific modulation)组成。这些网络将参数 α、β、ε、位置代码 x 和观察方向 d 转换为颜色 c 和体密度 σ。然后通过体积渲染从 x 和 σ 合成预测的颜色。由于颜色 c 只与外观代码 α 有关,所以它只被送入颜色解码器。表情代码 ε 在身份特定调制后连接到位置代码,因为它主要反映形状 β 直观调制的运动。图中额外的纹理编码器模块 (TEM) 仅在训练阶段使用。RefineNet 将 MoFaNeRF 预测的粗糙图像作为输入并合成精细化的人脸。身份特定调制模块 ISM 和 RefineNet 的提出能进一步提高性能。
基于 NeRF 的网络结构
MoFaNeRF整体框架结构可以表示为:
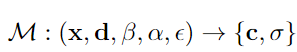
其中 x 是样本点的 3D 位置信息;d 是由θ, φ组成的观察方向信息;β、α、ε分别是表示人脸形状、外貌和表情的参数;c 和 σ 是用于表示神经辐射场的 RGB 颜色和密度。与经典 NeRF 结构一致,MoFaNeRF 的输入为3D 点 x = (x, y, z) 和观察方向 d = (θ, φ),引入位置编码以将连续输入 x 和 d 转换为高维空间,通过 MLP 网络预测该点的体积密度 σ 和颜色 c = (R, G, B)作为输出,可以使用可微分体积渲染模块将 σ 和 c 的场渲染为图像。光线 r 从光线原点 o 沿着光线方向投射通过神经体积场,公式为 r(z) = o + zd。通过沿这条射线的采样点和采样密度σ(·),利用体渲染技术可以计算出该像素的最终输出颜色C(r):
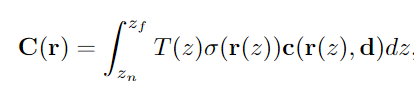
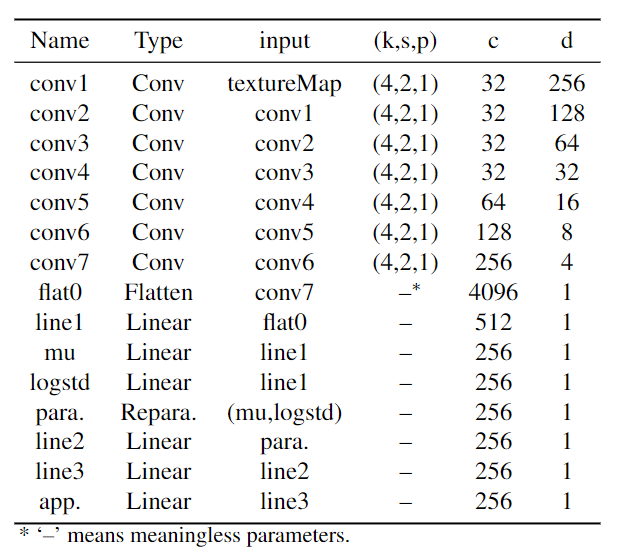
具体网络参数如下图所示。
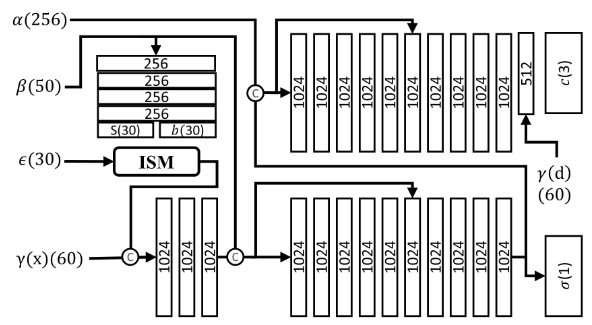
方框代表全连接层,其中数字代表神经元的数量。里面有 C 的圆圈代表张量之间的连接操作。参数后面的数字表示该参数的尺寸。α, β, ε是外观、形状和表情的参数。γ(x)和γ(d)表示位置编码x和观察方向的位置编码。σ 和 c 是形成辐射场的密度和颜色。TEM模块的参数参见 TEM 模块所示。
参数β、α、ε
- Shape parameter β:采用 FaceScape 的双线性模型的身份参数作为形状参数
- Appearance parameter α:纹理编码模块 (TEM)将FaceScape 数据集提供的 UV 纹理图编码为 α 进行训练
- Expression parameter ε:直接将表达式参数与位置代码连接会导致更少的伪影,具体公式参见 ISM 模块
纹理编码模块 (TEM)
编码的外观信息 α 由纹理编码模块 (TEM)传输到 MLP,这是一个基于 CNN 的编码器网络。TEM 仅用于训练阶段,它显着提高了合成图像的质量,减轻了 MLP 记忆外观的负担。MoFaNeRF 中 TEM 的详细参数如下:
特定身份调制模块 (ISM)
直观上,不同个体的面部表情彼此不同,因为个体具有其独特的表情特质,但实验发现 MLP 在解缠结后抹去了大部分这些独特的特征。本文将个体的独特表达视为 β 和 ε 之间的调制关系,可以表示为:![]()
![]() 其中 ε’ 是表达式代码的更新值,Ms 和 Ms 是将 β 转换为身份特定代码的浅层 MLP。
其中 ε’ 是表达式代码的更新值,Ms 和 Ms 是将 β 转换为身份特定代码的浅层 MLP。
RefineNet 网络
为了对细节进行进一步优化,作者利用 Pixel2PixelHD 进行后处理,如总体框架图所示,RefineNet 的输入是 MoFaNeRF 渲染的粗糙图像,输出是具有高频细节的精细图像。这部分的Loss是 GAN 损失和感知损失的组合
训练细节
使用 FaceScape 发布的 7180 多视图模型来训练模型。这些模型是从 359 个不同的对象中捕获的,每个对象有 20 个表情。我们随机选择 300 名受试者(6000 次扫描)作为训练数据,留下 59 名受试者(1180 次扫描)进行测试。所有这些模型都在规范空间中对齐,肩部下方的区域被移除。在 120 个视点中渲染了大约 860, 000 张图像,其中 720, 000 作为训练集,其余作为测试集。
损失函数
MoFaNeRF 的损失函数可以表示为:
应用
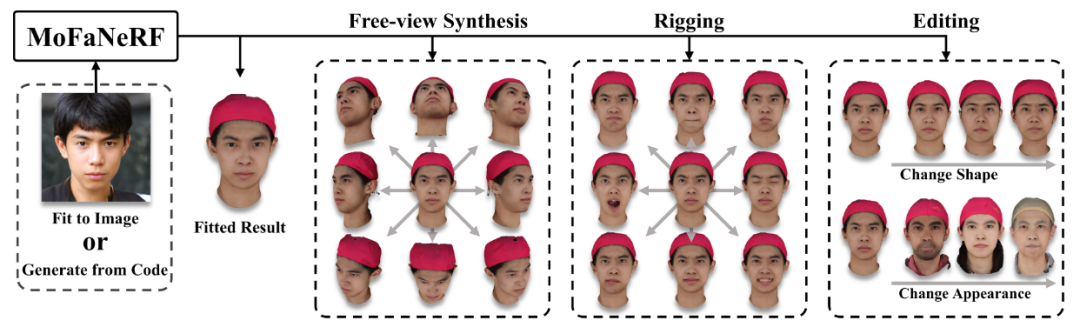
自由视图生成

随机生成的结果如上图所示。

生成的人脸可以通过插入形状、外观和表情的代码来平滑变形,上图为插值结果。
图像拟合
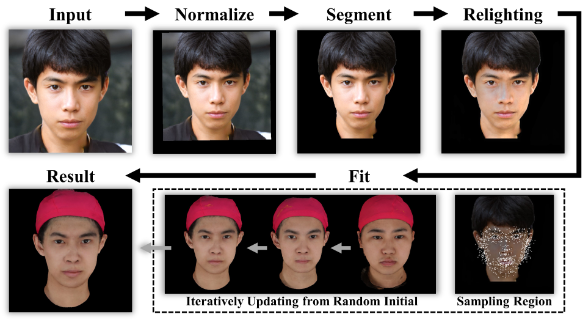
图像拟合指的是预处理后用训练好的网络,使其输出的图像拟合给定的图像,其流程如上图所示。
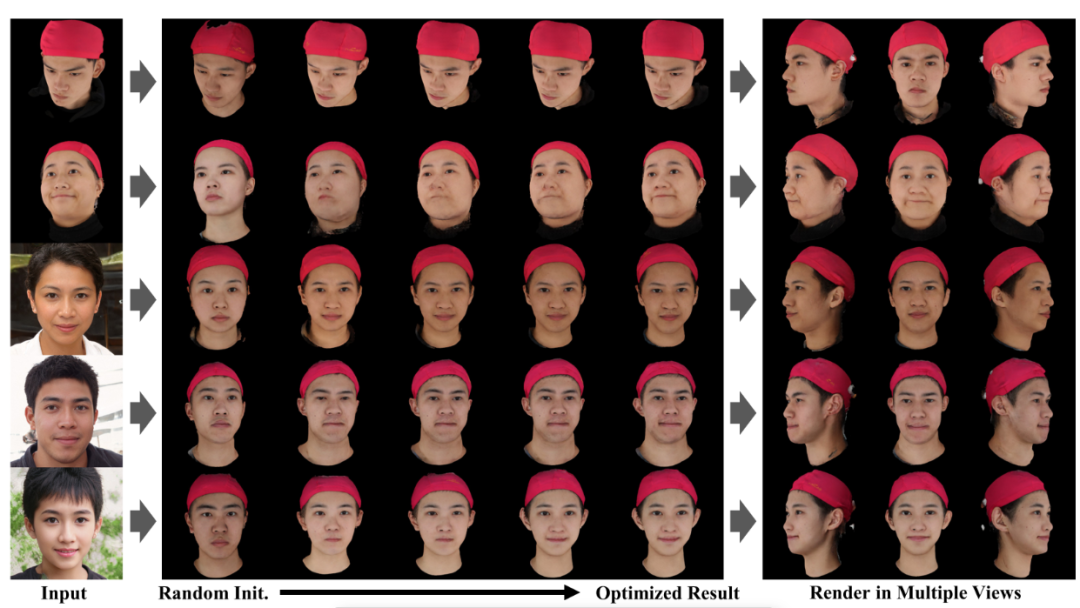
上图是更多拟合结果的展示。
人脸绑定与编辑
在文中指出编辑是通过操纵形状和外观代码来编辑生成或拟合的面孔。形状编码器指的是面部形状、鼻子、眼睛和嘴巴的几何形状和位置;而外表是指皮肤、嘴唇、瞳孔以及胡须和睫毛等精细特征的颜色。通过简单地替换形状或外观代码,可以将这些特征从face A 替换到face B。而rigging指的是对人脸表情进行操纵,其实现是通过修改exp参数实现的,该参数既可以手动设定,也可以在视频中通过fitting得到。
限制
该模型不会明确生成 3D 形状,只关注渲染性能。虽然可以通过某种方式从神经辐射场中提取 3D 形状,但 3D 精度没有保证的。此外,MoFaNeRF 的单视图拟合仅适用于相对漫射的光照,而在极端光照条件下性能会下降。
来源:媒矿工厂第一时间发布最新最有料的媒体技术资讯。倡导极客、创客精神,促进学术界、工业界以及开源社区共享信息、交流干货、发掘价值。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。