
近期进展表明,强化学习可以显著提升 LLM 的推理能力。基于此,本研究旨在改进音频 LLM ——一种处理音频和文本以执行问答等任务的模型。MMAU 基准是一个广泛使用的数据集,旨在评估这些模型,其中包含关于声音、语音和音乐的多项选择题,其中一些问题需要外部知识。先前的方法 R1-AQA 使用 GRPO(组相对策略优化)在 AVQA 数据集上对 Qwen2-Audio 模型进行微调,并在 MMAU 上取得了最佳 (SOTA) 成果。受此启发,作者应用 GRPO 对较新的多模态模型 Qwen2.5-Omni-7B 进行微调,进一步提升了性能。此外,他们还引入了一种自动生成音频问答数据的方法,从而获得了更佳的结果。
与 SARI 等方法相比,SARI 采用了更复杂的监督微调和强化学习(RL)结合结构化推理的方法,而作者的方法更简单,仅依赖于强化学习,没有明确的推理步骤。他们还进行了纯文本输入实验,以探究 GRPO 在性能提升中的作用。令人惊讶的是,仅使用文本数据对模型进行微调,其效果几乎与使用音频和文本进行训练的效果相同。这一发现表明,GRPO 主要通过文本来增强模型的推理能力,显著提升了模型在音频问答任务中的表现。
来自麻省理工学院计算机科学与人工智能实验室 (MIT CSAIL)、歌德大学、IBM 研究院等机构的研究人员推出了 Omni-R1,这是基于 GRPO 强化学习方法的多模态 LLM Qwen2.5-Omni 的微调版本。Omni-R1 在 AVQA 数据集上进行训练,在 MMAU 基准测试中,所有音频类别均创下了最佳成绩。令人惊讶的是,大部分性能提升源于增强的基于文本的推理能力,而非音频输入。使用纯文本数据进行微调也带来了显著的性能提升。此外,该团队使用 ChatGPT 生成了大规模音频问答数据集,进一步提升了准确性。他们的工作强调了文本推理对音频 LLM 性能的显著影响,并承诺将公开发布所有资源。
Omni-R1 模型使用 GRPO 强化学习方法对 Qwen2.5-Omni 进行微调,其提示格式简洁,允许直接选择答案,从而节省了 48GB GPU 的内存。GRPO 通过使用仅基于答案正确性的奖励来比较分组输出,从而避免了价值函数。研究人员使用 Qwen-2 Audio 的音频字幕扩展训练数据,并促使 ChatGPT 生成新的问答对。该方法生成了两个数据集——AVQA-GPT 和 VGGS-GPT——分别涵盖 4 万和 18.2 万个音频。使用这些自动生成的数据集进行训练提升了性能,其中 VGGS-GPT 帮助 Omni-R1 在 MMAU 基准测试中达到了最佳准确率。
研究人员使用 GRPO 在 AVQA、AVQA-GPT 和 VGGS-GPT 数据集上对 Qwen2.5-Omni 进行了微调。结果显示性能显著提升,VGGS-GPT 在 MAU Test-mini 测试中的最佳平均得分为 71.3%。Qwen2.5-Omni 的表现优于包括 SARI 在内的基线模型,即使在没有音频的情况下也表现出强大的推理能力,表明其基于文本的理解能力非常强。由于 Qwen2-Audio 的初始文本推理能力较弱,GRPO 微调对其性能提升更为显著。令人惊讶的是,不带音频的微调提升了性能,而像 ARC-Easy 这样的纯文本数据集则获得了相当的结果。改进主要源于增强的文本推理能力,尽管基于音频的微调在实现最佳性能方面仍然略胜一筹。
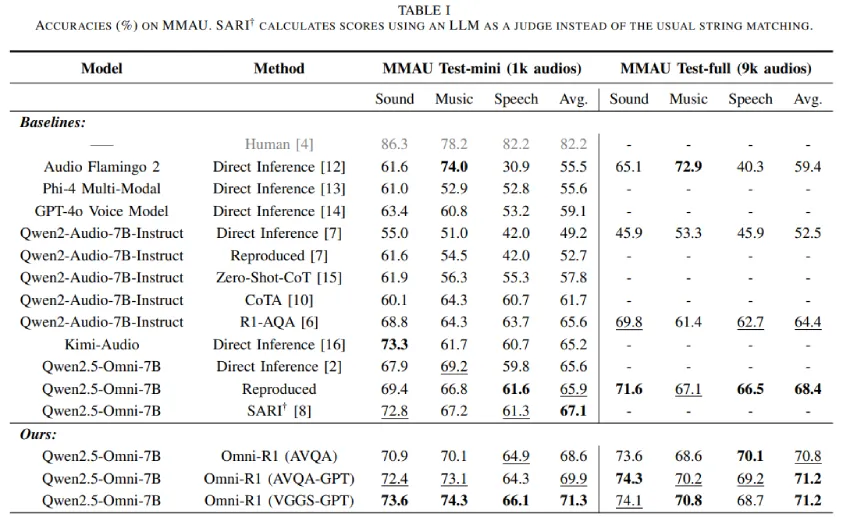

总而言之,Omni-R1 是一款音频法学硕士 (LLM),它基于 GRPO 强化学习方法对 Qwen2.5-Omni 进行微调,从而增强了音频问答能力。Omni-R1 在 MMAU 基准测试中,在声音、语音、音乐和整体表现方面均取得了新的最佳成绩。我们利用自动生成的问题创建了两个新的大规模数据集 AVQA-GPT 和 VGGS-GPT,进一步提升了模型准确率。实验表明,GRPO 主要增强了基于文本的推理能力,显著提升了性能。令人惊讶的是,仅使用文本(不含音频)进行微调也能提升基于音频的性能,这凸显了强大的基础语言理解能力的价值。这些发现为开发支持音频的语言模型提供了经济高效的策略。
论文地址:https://arxiv.org/abs/2505.09439
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/58199.html