
NVIDIA 发布了 Llama Nemotron Nano 4B,这是一个开源推理模型,旨在在科学任务、编程、符号数学、函数调用和指令跟踪方面提供强大的性能和效率,同时足够紧凑,适合边缘部署。根据内部基准测试,它仅包含 40 亿个参数,与拥有多达 80 亿个参数的同类开放模型相比,实现了更高的准确率和高达 50% 的吞吐量。
该模型旨在为在资源受限的环境中部署基于语言的AI代理奠定实用基础。Llama Nemotron Nano 4B 专注于推理效率,满足了市场对紧凑型模型日益增长的需求,这些模型能够支持传统云环境之外的混合推理和指令执行任务。
模型架构和训练堆栈
Nemotron Nano 4B 基于 Llama 3.1 架构构建,与 NVIDIA 早期的“Minitron”系列共享血统。该架构采用高密度、仅解码器的 Transformer 设计。该模型已针对推理密集型工作负载的性能进行了优化,同时保持了轻量级的参数数量。
该模型的训练后堆栈包括对数学、编码、推理任务和函数调用等精选数据集进行多阶段监督微调。除了传统的监督学习之外,Nemotron Nano 4B 还采用了奖励感知偏好优化 (RPO) 进行强化学习优化,这种方法旨在增强模型在基于聊天和指令遵循环境中的实用性。
这种指令调整和奖励建模的结合有助于使模型的输出更贴近用户意图,尤其是在多轮推理场景中。这种训练方法体现了 NVIDIA 的理念:将较小的模型与传统上需要更大参数规模的实际使用任务相结合。
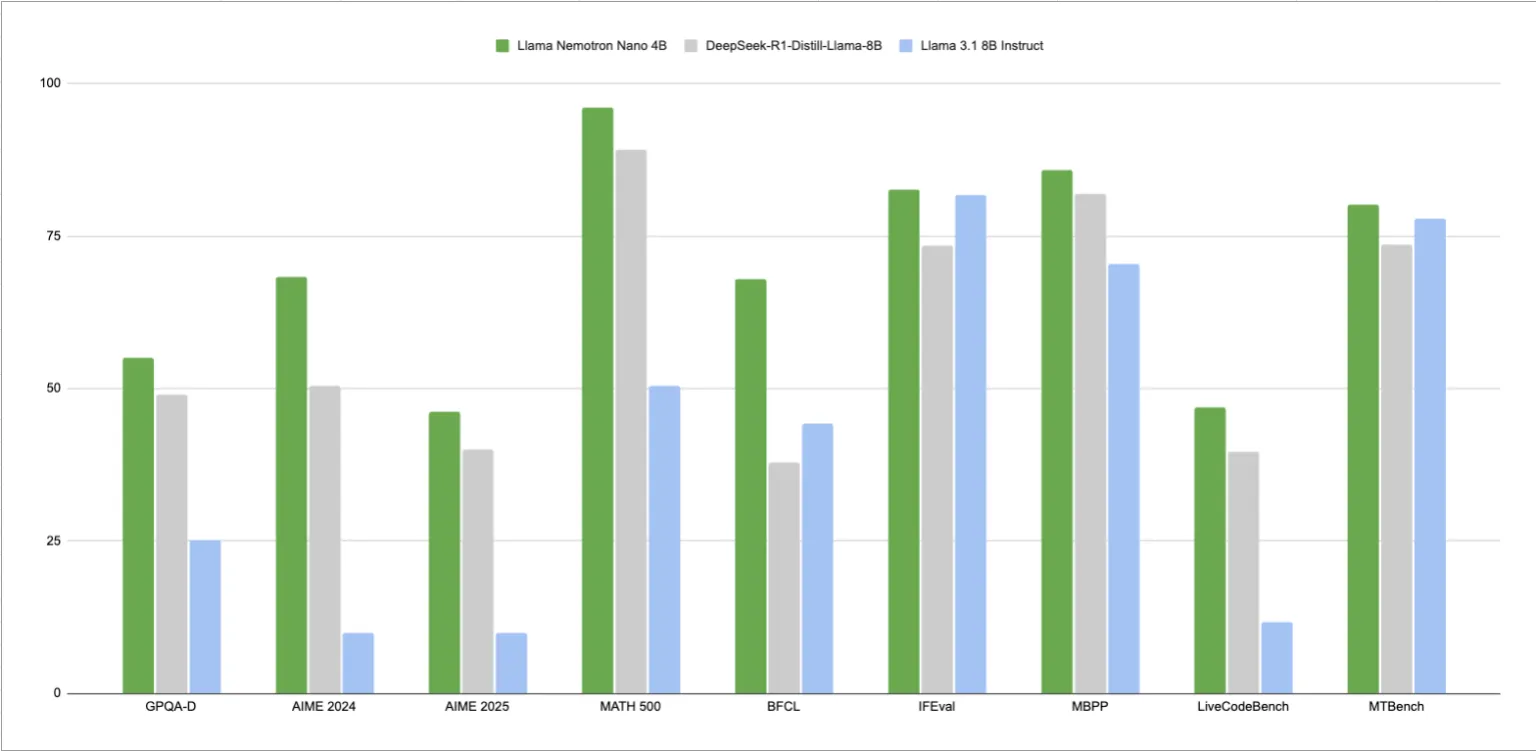

性能基准
尽管体积小巧,Nemotron Nano 4B 在单轮和多轮推理任务中均表现出色。据 NVIDIA 称,与 8B 参数范围内的类似开放权重模型相比,它的推理吞吐量提高了 50%。该模型支持最多 128,000 个 token 的上下文窗口,这对于涉及长文档、嵌套函数调用或多跳推理链的任务尤其有用。
虽然 NVIDIA 尚未在 Hugging Face 文档中披露完整的基准测试表,但据报道,该模型在数学、代码生成和函数调用精度等基准测试中均优于其他开放替代方案。其吞吐量优势表明,对于以中等复杂工作负载的高效推理流程为目标的开发人员来说,它可以作为可行的默认模型。
边缘就绪部署
Nemotron Nano 4B 的核心优势之一在于其专注于边缘部署。该模型经过精心测试和优化,可在 NVIDIA Jetson 平台和 NVIDIA RTX GPU 上高效运行。这使得其能够在低功耗嵌入式设备(包括机器人系统、自主边缘代理或本地开发者工作站)上实现实时推理功能。
对于关注隐私和部署控制的企业和研究团队来说,在本地运行高级推理模型(而不依赖云推理 API)的能力可以节省成本并提供更大的灵活性。
许可和访问
该模型根据 NVIDIA 开放模型许可证发布,允许商业使用。您可以通过 Hugging Face 获取该模型,网址为huggingface.co/nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1,所有相关的模型权重、配置文件和分词器构件均可公开访问。该许可证结构符合 NVIDIA 支持其开放模型开发者生态系统的更广泛战略。
结论
Nemotron Nano 4B 代表了 NVIDIA 持续投入,致力于将可扩展、实用的 AI 模型带给更广泛的开发受众,尤其是那些针对边缘计算或成本敏感型部署场景的开发者。尽管该领域在超大型模型方面持续取得快速进展,但像 Nemotron Nano 4B 这样紧凑高效的模型能够提供平衡,在不过度牺牲性能的情况下实现部署灵活性。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/58316.html