
强化学习已成为一种强大的方法,可以对大型语言模型 (LLM) 进行微调,使其更加智能。这些模型已经能够执行从摘要到代码生成的各种任务。强化学习能够根据结构化反馈调整其输出,从而提供帮助。随着人们对模型不仅要准确,还要与复杂的偏好或规则保持一致的需求日益增长,强化学习提供了一种提升其性能的关键机制。因此,强化学习已成为许多高级 LLM 系统训练后流程的核心组成部分。
扩展 LLM 的 RL 所面临的基础设施挑战
将强化学习应用于大规模 LLM 的一大挑战在于其巨大的资源需求。训练这些模型不仅需要海量计算,还需要不同组件之间的协调。这些组件包括策略模型、奖励评分器和评判器。模型规模可扩展到数千亿个参数,而内存使用、数据通信延迟和 GPU 空闲时间等问题则构成了棘手的工程难题。如果没有高效的设计,这些限制将阻碍强化学习应用于更新、更大规模的模型。实现高 GPU 利用率并最大限度地减少进程间瓶颈对于可扩展且及时的训练至关重要。
先前的 LLM 强化学习框架的局限性
先前的解决方案要么过于僵化,要么在扩展时效率低下。传统的同步框架按顺序执行生成和训练,由于任务时长不匹配,经常导致 GPU 空闲。像 DeepSpeed-Chat 这样的工具采用混合内存策略,但需要模型共享内存空间。这会导致生成过程中的性能瓶颈。一些分布式方法尝试解耦组件,但仍然依赖于繁重的编排工具,从而限制了灵活性。此外,早期的框架通常无法针对训练和推理过程中不同的并行需求优化内存使用。
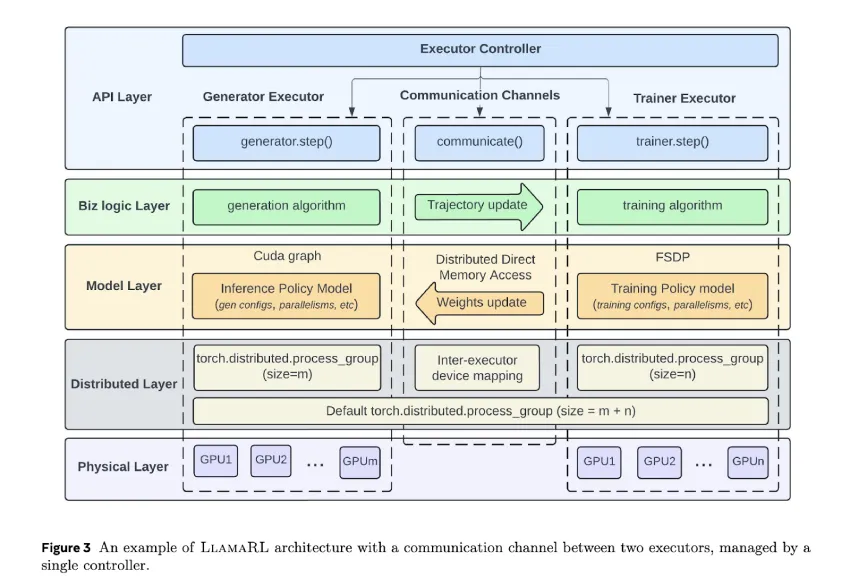

Meta 的 LlamaRL:基于 PyTorch 的分布式异步 RL 框架
Meta 研究人员推出了 LlamaRL,这是一个完全异步的分布式强化学习框架。它专为在从几个到数千个 GPU 的集群上训练大规模 LLM 而量身定制。他们完全使用 PyTorch 构建了 LlamaRL,并实现了单控制器设计以简化协调。这种设计支持模块化定制。独立的执行器分别管理每个 RL 组件(例如生成器、训练器和奖励模型),并并行运行。这种异步设置减少了整个 RL 流程的等待时间。它还可以独立优化模型并行性和内存使用情况。
主要特点:卸载、内存效率和异步执行
LlamaRL 的架构优先考虑灵活的执行和高效的内存使用。它将生成过程卸载到专用的执行器,使训练器能够专注于模型更新。分布式直接内存访问 (DDMA) 支持这种卸载。它使用 NVIDIA NVLink 在两秒内同步权重——即使对于包含 4050 亿个参数的模型也是如此。该框架应用异步重要性加权策略优化 (AIPO) 来纠正异步执行导致的偏离策略问题。每个执行器独立运行,利用细粒度并行性,并将量化技术应用于推理模型,以进一步降低计算和内存需求。
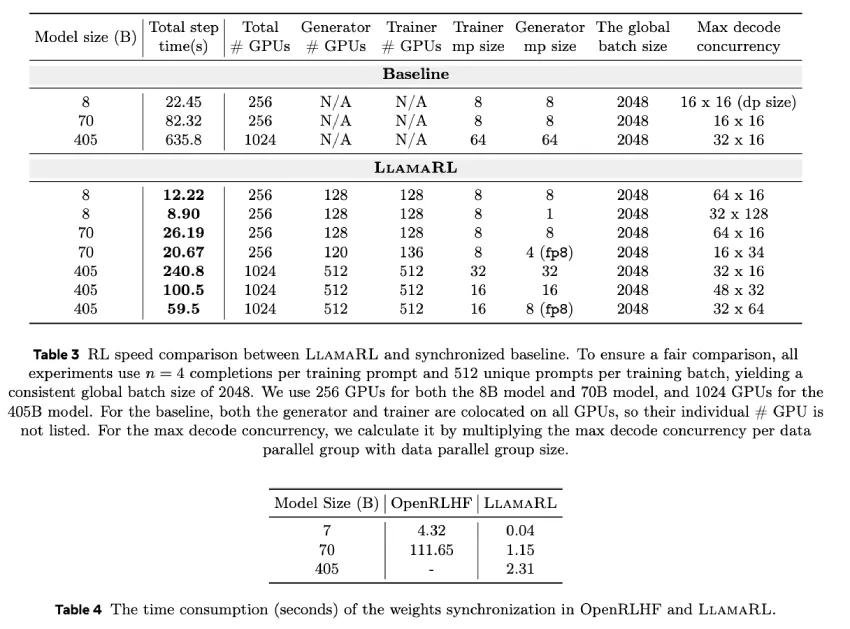
实际性能基准:405B 型号加速 10.7 倍
LlamaRL 在不影响质量的前提下显著提升了训练速度。在一个拥有 256 块 GPU 的 8B 参数模型上,它将训练步长从 22.45 秒缩短至 8.90 秒。对于 70B 模型,训练步长从 82.32 秒缩短至 20.67 秒。最令人印象深刻的是,在一个拥有 1024 块 GPU 的 405B 参数模型上,LlamaRL 将强化学习步长从 635.8 秒缩短至 59.5 秒,并且比同步基准速度提高了 10.7 倍。这些提升不仅源于异步执行,还得益于其解耦的内存和计算策略。在 MATH 和 GSM8K 上的基准测试评估证实,LlamaRL 保持了稳定的性能。一些指标甚至显示出轻微的提升。
最后的想法:LlamaRL 作为 LLM 培训的可扩展路径
这项研究针对其中一项最严重的瓶颈问题,提出了一个实用且可扩展的解决方案。该瓶颈在于使用强化学习训练大型语言模型 (LLM)。LlamaRL 引入异步训练,标志着传统强化学习 (RL) 流程的重大转变。通过解决内存限制、通信延迟和 GPU 效率低下等问题,该框架为语言模型训练的未来发展提供了一个高度集成的解决方案。
论文地址:https://arxiv.org/abs/2505.24034
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/58757.html