
近几个月来,人们对将扩散模型(最初设计用于图像等连续数据)应用于自然语言处理任务的兴趣日益浓厚。这促成了离散扩散语言模型 (DLM) 的发展,该模型将文本生成视为一个去噪过程。与传统的自回归模型不同,DLM 支持并行解码,并能更好地控制结构,从而提供诸如灵活初始化整个序列、明确控制输出格式以及通过双向注意力机制改进填充等优势。
此外,它们的非序列特性也为更快的生成速度打开了大门。尽管存在这些优势,但大多数当前的多模态大型语言模型 (MLLM)(例如 LLaMA、Qwen-VL 和 InternVL)仍然仅仅依赖于自回归方法。
基于扩散的语言模型研究探索了连续和离散的扩散空间。诸如 DiffuSeq 和 SED 之类的连续方法使用嵌入或宽松的分类空间来实现更平滑的生成。相比之下,诸如 SDDM 和 RDM 之类的离散模型则根据语言结构定制扩散过程。训练技术各不相同,但通常使用掩蔽语言建模损失或基于熵的分数匹配。一些混合模型,例如 AR-Diffusion 和 SSD-LM,结合了自回归和扩散策略,以充分利用两种方法的优势。同时,诸如 LLaVA 和 InternVL 之类的开源 MLLM 通过视觉指令调整和联合预训练取得了进展,但仍然遵循自回归生成方案。
新加坡国立大学的研究人员展示了首个离散动态语言语言模型 (DMLLM)——Dimple,它将视觉编码器与基于离散扩散的语言模型相集成。为了克服纯扩散训练的不稳定性和性能问题,他们引入了一种两阶段训练方法:先自回归后扩散,将初始自回归对齐与后续基于扩散的掩码语言模型相结合。Dimple-7B 在基准测试中比 LLaVA-NEXT 高出 3.9%。该团队还引入了用于动态标记生成的置信解码 (Confident Decoding),并探索了用于精确控制输出的结构先验 (Structure Priors)。这些创新显著提高了推理效率、生成灵活性和结构可控性,且不影响性能。
Dimple 是一个离散扩散多模态 LLM ,它将视觉编码器与基于扩散的语言模型相集成。为了解决扩散训练中的低效问题,例如稀疏监督和有限的生成覆盖范围,该模型分两个阶段进行训练:首先使用因果注意力掩码进行自回归训练,以实现视觉-语言对齐;然后进行扩散训练以恢复生成能力。在推理过程中,动态“置信解码”策略会根据预测置信度调整标记更新。尽管使用的训练样本显著减少,Dimple 在多个基准测试中仍表现出颇具竞争力的性能,优于类似规模的自回归模型,尽管它落后于更大规模的先进系统。
实验评估了 Dimple 与自回归模型在指令遵循任务上的表现。Dimple 采用结合自回归和扩散调优的混合策略进行训练,表现出强劲的性能,在大多数基准测试中超越了使用类似训练数据的模型。尽管 Dimple 的性能落后于在更大规模数据集上训练的模型,但它受益于更强大的基础语言模型。消融研究表明,结合自回归和扩散调优可以缓解长度偏差等问题,并提高一致性。预填充进一步显著提升了推理速度,且性能仅略有下降,使该模型在多模态理解任务中既高效又具有竞争力。
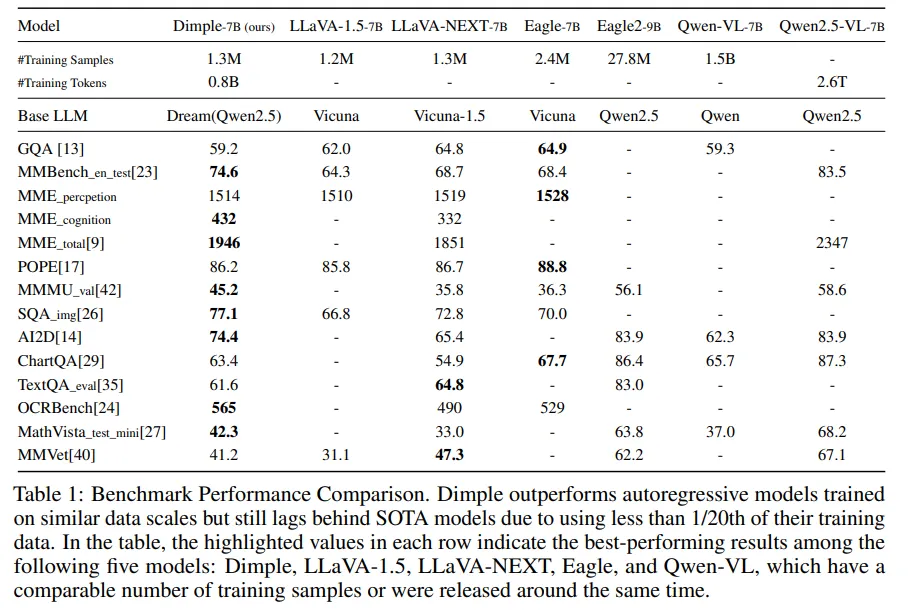

总而言之,首个离散模型层级结构 (DMLLM) Dimple 的设计旨在克服纯离散扩散训练的局限性,例如不稳定性以及长度偏差。Dimple 采用混合训练方法,首先进行自回归学习,然后进行扩散调优,最终生成 Dimple-7B 模型,其性能比 LLaVA-NEXT 高出 3.9%。其解码策略——置信解码,显著减少了推理步骤,而预填充则在性能损失最小的情况下提升了速度。Dimple 还通过结构先验实现了结构化且可控的输出,从而提供了自回归模型难以提供的对格式和长度的细粒度控制能力。
资料
- 论文地址:https://arxiv.org/abs/2505.16990
- GitHub:https://github.com/yu-rp/Dimple
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/58463.html