
北京智源人工智能研究院 (BAAI) 推出了新一代开源多模态生成模型 OmniGen2。该新架构在其前身 OmniGen 的基础上进行了扩展,将文本转图像生成、图像编辑和主题驱动生成功能统一在一个 Transformer 框架中。它的创新之处在于:解耦文本和图像生成的建模,融入反射式训练机制,并实现了专门构建的基准 OmniContext 来评估上下文一致性。
解耦的多模态架构
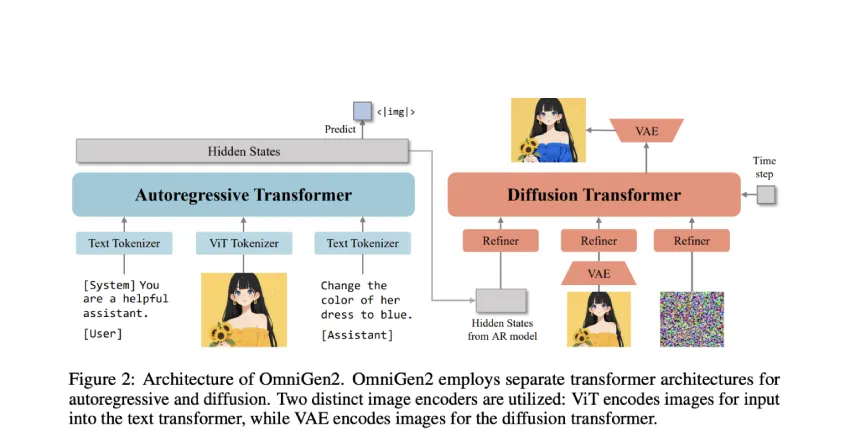
与先前在文本和图像模态之间使用共享参数的模型不同,OmniGen2 引入了两种不同的路径:用于文本生成的自回归变换器和用于图像合成的基于扩散的变换器。它还采用了一种名为 Omni-RoPE 的新型定位策略,可以灵活处理序列、空间坐标和模态差异,从而实现高保真图像的生成和编辑。
为了保留底层 MLLM(基于 Qwen2.5-VL-3B)的预训练文本生成能力,OmniGen2 仅将 VAE 衍生的特征馈送到扩散路径。这既避免了损害模型的文本理解和生成能力,又为图像合成模块保留了丰富的视觉呈现。

迭代生成的反射机制
OmniGen2 的一大亮点是其反射机制。通过在训练过程中集成反馈循环,该模型能够分析其生成的输出,识别不一致之处并提出改进建议。此过程模拟了测试时的自我校正,显著提高了指令执行的准确性和视觉连贯性,尤其适用于修改颜色、对象数量或定位等细微任务。
反射数据集采用多轮反馈构建,使模型能够学习如何根据内容评估来修改和终止生成。这种机制对于弥合开源模型与商业模型之间的质量差距尤为有效。
OmniContext 基准:评估上下文一致性
为了严格评估上下文生成能力,团队引入了 OmniContext 基准测试,该基准测试包含三种主要任务类型:单任务 (SINGLE)、多任务 (MULTIPLE) 和场景 (SCENE),涵盖角色、对象和场景类别。OmniGen2 在该领域的开源模型中展现出最佳性能,总分为 7.18 分,超越了 BAGEL 和 UniWorld-V1 等其他领先模型。
评估采用三个核心指标:提示遵循度 (PF)、主题一致性 (SC) 和总分(几何平均值),每个指标均通过基于 GPT-4.1 的推理进行验证。该基准框架不仅强调视觉真实性,还强调提示的语义一致性和跨图像一致性。
数据管道和训练语料库
OmniGen2 基于 1.4 亿个 T2I 样本和 1000 万张专有图像进行训练,并辅以精心挑选的数据集,用于上下文生成和编辑。这些数据集采用基于视频的流水线构建,该流水线提取语义一致的帧对,并使用 Qwen2.5-VL 模型自动生成指令。生成的注释涵盖了细粒度的图像处理、运动变化和构图变化。
在训练过程中,MLLM 参数基本保持不变,以保持总体理解;而扩散模块则从头开始训练,并针对视觉-文本联合注意机制进行优化。特殊标记“<|img|>”可触发输出序列中的图像生成,从而简化多模态合成过程。
跨任务表现
OmniGen2 在多个领域取得了优异的成果:
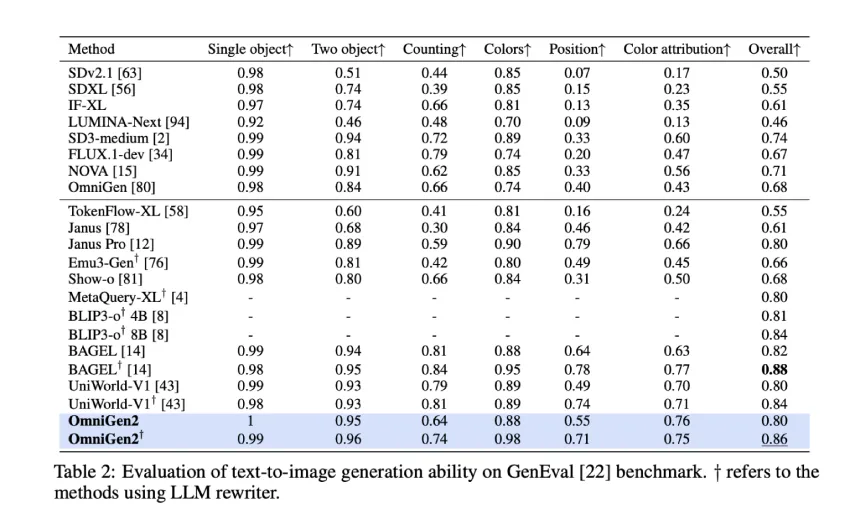
- 文本到图像 (T2I):在 GenEval 上获得 0.86 分,在 DPG-Bench 上获得 83.57 分。
- 图像编辑:优于具有高语义一致性的开源基线(SC=7.16)。
- 上下文生成:在 OmniContext 中设定了新的基准,任务得分分别为 7.81(单个)、7.23(多个)和 6.71(场景)。
- 反思:展示了对失败代的有效修正,并具有良好的修正精度和终止行为。
结论
OmniGen2 是一个强大而高效的多模态生成系统,通过架构分离、高质量数据流水线和集成反射机制推进统一建模。通过开源模型、数据集和代码,该项目为未来可控、一致的图文生成研究奠定了坚实的基础。未来的改进可能侧重于强化学习,以实现反射细化,并扩展多语言和低质量模型的鲁棒性。
资料
- 论文地址:https://arxiv.org/abs/2506.18871
- GitHub:https://github.com/VectorSpaceLab/OmniGen2
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/59107.html