
AI 驱动的视频生成技术正以令人惊叹的速度不断进步。在很短的时间内,我们已经从模糊、不连贯的剪辑变成了具有惊人逼真度的视频。然而,尽管取得了这些进步,我们却缺少了一项关键能力:控制和编辑。
制作精美的视频固然重要,但如何专业而逼真地编辑视频,例如将光线从白天变为夜晚、将物体的材质从木材换成金属,或是将新元素无缝地融入场景——仍然是一个难以攻克的难题。这一差距一直是阻碍AI成为电影制作人、设计师和创作者真正基础工具的关键障碍。
直到引入DiffusionRenderer !!
在一篇开创性的新论文中,NVIDIA、多伦多大学、矢量研究所和伊利诺伊大学香槟分校的研究人员公布了一个直接应对这一挑战的框架。DiffusionRenderer 代表着一次革命性的飞跃,它超越了单纯的生成功能,为理解和处理单个视频中的 3D 场景提供了统一的解决方案。它有效地弥合了生成和编辑之间的差距,释放了 AI 驱动内容的真正创作潜力。
旧方法与新方法:范式转变
几十年来,照片级写实主义一直以基于物理规则(PBR)为基础,这是一种精确模拟光流的方法。虽然它能产生令人惊叹的效果,但它本身却是一个脆弱的系统。PBR 的关键在于场景的完美数字蓝图——精确的 3D 几何体、细致的材质纹理和精准的光照贴图。从现实世界中获取此蓝图的过程被称为逆向渲染,众所周知,它非常困难且容易出错。即使是数据中的微小瑕疵,也可能导致最终渲染出现灾难性的失败,这是一个限制 PBR 在受控工作室环境之外使用的关键瓶颈。
之前的神经渲染技术,例如 NeRF,虽然在创建静态视图方面具有革命性,但在编辑方面却遇到了瓶颈。它们将光照和材质“烘焙”到场景中,使得后期捕捉修改几乎不可能。
DiffusionRenderer在一个统一的框架中处理“什么”(场景的属性)和“如何”(渲染),该框架建立在与稳定视频扩散等模型相同的强大视频扩散架构之上。
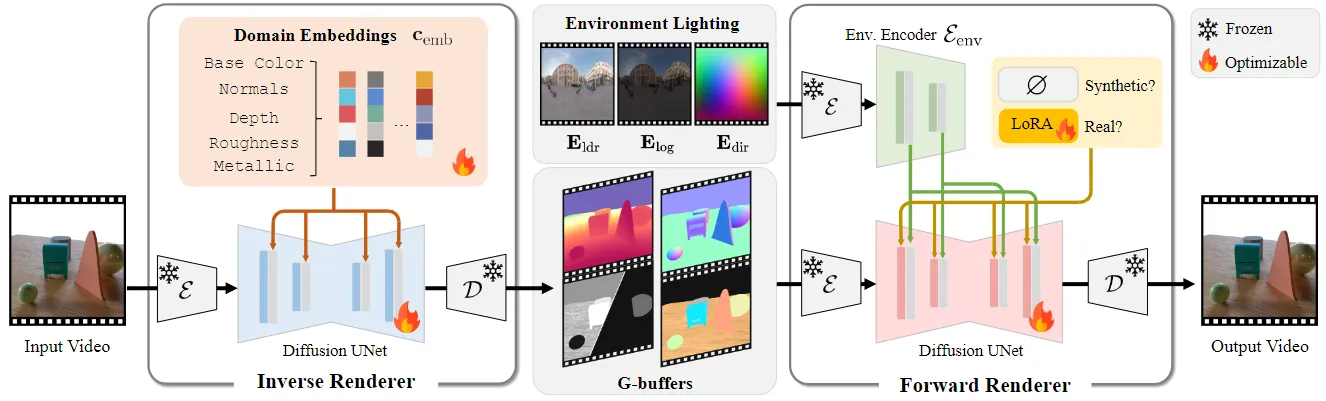

这种方法使用两种神经渲染器来处理视频:
- 神经反渲染器:该模型就像一个场景侦探。它分析输入的 RGB 视频,智能地估计内在属性,生成基本数据缓冲区(G 缓冲区),在像素级描述场景的几何形状(法线、深度)和材质(颜色、粗糙度、金属感)。每个属性都在一个专门的通道中生成,以实现高质量的生成。
- 神经正向渲染器:该模型充当艺术家的角色。它从逆向渲染器获取 G 缓冲区,将其与任何所需的光照(环境贴图)组合,并合成逼真的视频。至关重要的是,它经过训练,非常稳健,即使逆向渲染器的输入 G 缓冲区不完善或“嘈杂”,也能生成令人惊叹的复杂光线传输效果,例如柔和阴影和相互反射。
这种自我修正的协同作用正是这一突破的核心。该系统专为现实世界的混乱而设计,在现实世界中,完美的数据只是一个神话。
秘诀:弥合现实差距的全新数据策略
如果没有智能数据,智能模型就毫无意义。DiffusionRenderer 背后的研究人员设计了一种巧妙的双管齐下的数据策略,让他们的模型能够理解完美物理和不完美现实之间的细微差别。
- 海量合成宇宙:首先,他们构建了一个包含 15 万个视频的庞大高质量合成数据集。他们使用数千个 3D 对象、PBR 材质和 HDR 光照贴图,创建了复杂的场景,并使用完美的路径追踪引擎进行渲染。这为反向渲染模型提供了一本完美的“教科书”,为其提供了完美的真实数据。
- 自动标记真实世界:团队发现,仅使用合成数据训练的逆向渲染器在推广到真实视频方面表现出色。他们将其应用于包含 10,510 个真实视频 (DL3DV10k) 的海量数据集。该模型自动为这些真实视频生成 G-buffer 标签。这创建了一个包含 150,000 个真实场景样本的庞大数据集,其中包含相应的(尽管不完善的)固有属性图。
通过使用完美的合成数据和自动标记的真实世界数据对前向渲染器进行联合训练,该模型学会了弥合关键的“领域差距”。它学习了来自合成世界的规则以及现实世界的外观和感觉。为了处理自动标记数据中不可避免的误差,该团队加入了一个 LoRA(低秩自适应)模块,这是一种巧妙的技术,它使模型能够适应噪声更大的真实数据,而不会损害从原始合成数据集中获得的知识。
一流的性能
结果不言而喻。在与经典方法和最先进的神经网络方法进行严格的头对头比较中,DiffusionRenderer在所有评估任务中始终遥遥领先:
- 前向渲染:在从 G 缓冲区和光照生成图像时,DiffusionRenderer 的表现显著优于其他神经方法,尤其是在复杂的多物体场景中,逼真的相互反射和阴影至关重要。该神经渲染的表现显著优于其他方法。

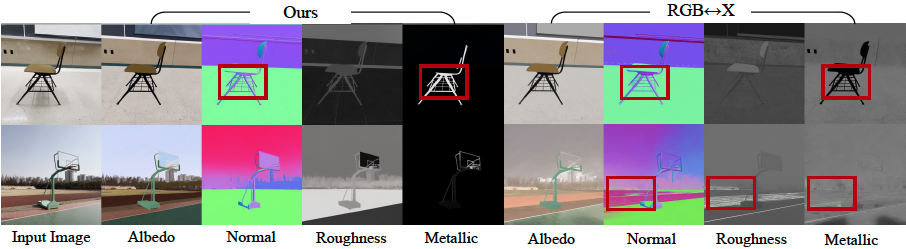
- 反向渲染:事实证明,该模型在通过视频估算场景的内在属性方面表现出色,在反照率、材质和法线估算方面的准确性高于所有基线模型。视频模型(相对于单图像模型)的使用效果尤为显著,金属质感和粗糙度预测误差分别减少了 41% 和 20%,因为它利用运动来更好地理解视图效应。
- 重光照:在对统一管道的最终测试中,DiffusionRenderer 与 DiLightNet 和 Neural Gaffer 等领先方法相比,在重光效果的数量和质量上都更胜一筹,能生成更精确的镜面反射和高保真照明。
您可以使用DiffusionRenderer做什么:强大的编辑功能!
这项研究解锁了一套实用且功能强大的编辑应用程序,这些应用程序只需一个日常视频即可运行。其工作流程非常简单:模型首先执行反向渲染以理解场景,用户编辑属性,然后模型执行正向渲染以创建新的逼真视频。
- 动态重光照:只需提供新的环境地图,即可更改一天中的时间、将工作室灯光换成日落,或彻底改变场景氛围。该框架会逼真地重新渲染视频,并保留所有相应的阴影和反射。
- 直观的材质编辑:想看看那把皮椅镀铬后会是什么样子?或者想让一座金属雕像看起来像是用粗糙的石头做成的?用户可以直接调整材质的 G 缓冲区,调整粗糙度、金属感和颜色属性,然后模型就会将这些变化渲染成照片级的真实感
- 无缝对象插入:将新的虚拟对象放入真实场景中。通过将新对象的属性添加到场景的 G 缓冲区,前向渲染器可以合成最终视频,其中对象自然地融入其中,投射逼真的阴影并从周围环境中拾取准确的反射。
图形的新基础
DiffusionRenderer 代表着一项突破性的进展。它在一个强大的数据驱动框架内全面解决了正向渲染和逆向渲染的问题,打破了传统 PBR 长期以来的壁垒。它使照片级真实感渲染变得大众化,使其从拥有强大硬件的 VFX 专家的专属领域,转变为创作者、设计师和 AR/VR 开发者更易于访问的工具。
在最近的更新中,作者利用 NVIDIA Cosmos 和增强的数据管理进一步改进了视频去光和重光照功能。
这表明了一个有希望的扩展趋势:随着底层视频扩散模型变得更加强大,输出质量得到改善,从而产生更清晰、更准确的结果。
这些改进使该技术更加引人注目。
资料来源:
- 演示视频:https://youtu.be/jvEdWKaPqkc
- 论文:https://arxiv.org/abs/2501.18590
- 代码:https://github.com/nv-tlabs/cosmos1-diffusion-renderer
- 项目页面:https://research.nvidia.com/labs/toronto-ai/DiffusionRenderer/
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/59621.html