
评估大语言模型(LLM)的成本在科学和经济上都耗资巨大。随着该领域竞相开发更大规模的模型,评估和比较这些模型的方法变得越来越重要,不仅是为了基准分数,更是为了做出明智的开发决策。艾伦人工智能研究所(Ai2)的最新研究提出了一个以两个核心指标为中心的 robust 框架:信号与噪声,以及它们的比值,即信噪比(SNR)。该框架通过提供可操作的洞察,有助于降低语言模型评估中的不确定性并提升可靠性,其有效性已在数百个模型和多样化的基准测试中得到验证。
理解 LLM 评估中的信号和噪声
信号
信号衡量基准区分优劣模型的能力,本质上是量化给定任务中模型得分的分布。信号高意味着模型性能在基准测试中分布广泛,从而更容易对模型进行有意义的排名和比较。信号低的基准测试得分过于接近,使得确定哪个模型真正更优更加困难。
噪声
噪声是指基准测试分数由于训练过程中的随机波动(包括随机初始化、数据顺序以及单次训练运行中检查点间的更改)而产生的差异。高噪声会降低基准测试的可靠性,因为即使使用相同的模型和数据配置,重复实验也会产生不一致的结果。
信噪比(SNR)
Ai2 的核心见解是,基准测试对于模型开发的效用不仅取决于信号或噪声本身,还取决于它们的比率——信噪比。高信噪比的基准测试能够持续提供更可靠的评估结果,并且更适合用于制定可迁移到大规模模型的小规模决策。信噪比为何对发展决策至关重要
在 LLM 开发中,有两种常见场景需要评估基准来指导关键决策:
- 决策准确率:训练多个小模型(例如,基于不同的数据方案),并选择最佳模型进行扩展。核心问题是:小规模模型的排名是否适用于更大规模?
- 缩放定律预测误差:根据小模型拟合缩放定律来预测更大模型的性能。
研究表明,在这些场景下,高信噪比基准测试的可靠性更高。信噪比与决策准确率 (R2=0.626) 密切相关,并且能够预测缩放定律预测误差的可能性 (R2=0.426) 。低信号或高噪声的基准测试会使开发决策更具风险,因为小规模的发现可能无法在生产规模上成立。
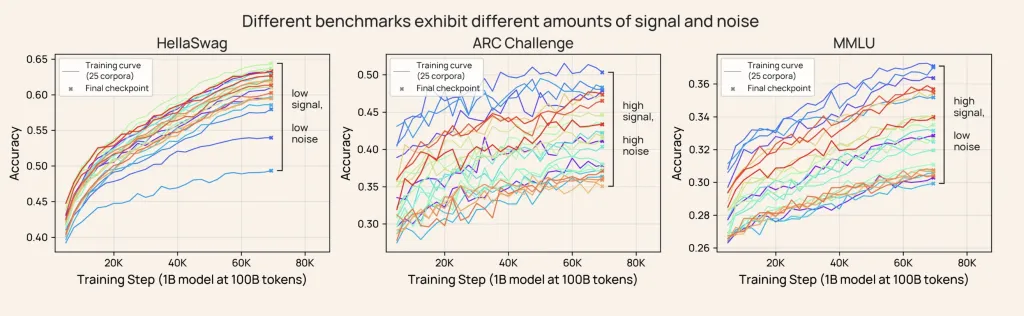

测量信号和噪声
实际定义
- 信号:对于在相似计算预算下训练的模型群体,以任意两个模型之间的分数最大差异(离散度)来衡量,并由平均分数标准化。
- 噪声:估计单个模型训练的最后 nnn 个检查点之间的分数相对标准偏差。
组合,SNR = 相对标准偏差(噪声)/ 相对色散(信号)
提供了一种廉价可靠的方法来表征评估鲁棒性。重要的是,检查点间的噪声与初始化和数据顺序噪声等传统噪声源高度相关,使其成为整体建模噪声的实用替代方法。
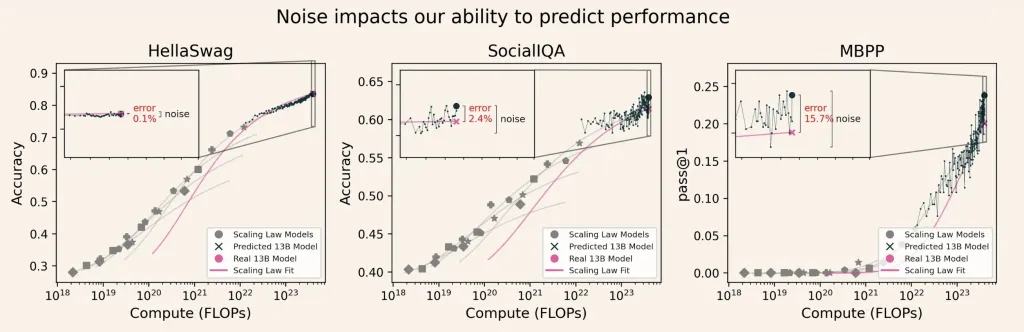
干预措施:如何改进评估基准
Ai2 提出并测试了几种实用干预措施来提高基准 SNR,从而帮助在 LLM 开发过程中做出更好的决策。
1. 根据信噪比筛选子任务
多任务基准测试(例如 MMLU、AutoBencher)通常是多个子任务的平均值。研究表明,选择高信噪比 (SNR) 子任务的子集(而不是使用所有可用任务或更大的样本量)可以显著提高信噪比 (SNR) 和决策准确率。例如,相比使用全部子集,仅使用 57 个 MMLU 子任务中排名前 16 个子任务可以获得更高的信噪比 (SNR) 和更好的预测效果。这种方法还有助于剔除标记误差较高的子任务,因为低信噪比子任务通常意味着数据质量较差。
2. 平均检查点得分
与其仅仅依赖最终的训练检查点,不如对多个最终检查点的得分进行平均(或在训练期间使用指数移动平均线),这样可以减少瞬态噪声的影响。这种方法可以持续提高决策准确率,并降低缩放定律预测误差。例如,在大多数基准测试中,平均决策准确率提高了 2.4%,预测误差也降低了。
3. 使用连续指标,例如每字节位数(BPB)
准确率等分类指标并未充分利用 LLM 输出的连续性。测量每字节比特数(与困惑度相关的连续指标)可显著提高信噪比 (SNR),尤其是在数学和代码等生成任务中。从准确率转向 BPB 后,GSM8K 的 SNR 从 1.2 提升至 7.0,MBPP 的 SNR 从 2.0 提升至 41.8,从而显著提升了决策准确率(例如,MBPP 从 68% 提升至 93%,Minerva MATH 从 51% 提升至 90%)。
关键要点
- 信噪比 (SNR) 作为基准选择工具:选择 LLM 评估的基准时,应以高信噪比为目标。这确保了小规模实验的决策在生产规模上具有预测性。
- 质量重于数量:更大的基准或更多的数据并不总是更好。基于信噪比 (SNR) 的子任务选择和指标选择可以显著提高评估质量。
- 早期停止和平滑:在开发过程中,对最终或中间检查点的结果进行平均,以减轻随机噪声并提高可靠性。
- 连续指标提高可靠性:对于具有挑战性和生成性的任务,连续指标(BPB、困惑度)优于分类指标;这大大提高了 SNR 和结果稳定性。
结论
Ai2 的信号与噪声框架重塑了模型开发者进行 LLM 基准测试和评估的方式。通过从 SNR 的视角关注统计特性,从业者可以降低决策风险,预测缩放规律行为,并为模型开发和部署选择最佳基准。Ai2 的公共数据集包含 465 个开放权重模型的 90 万次评估,进一步增强了这项研究,为社区提供了强大的工具,以推动 LLM 评估科学的进一步发展。
参考资料
https://arxiv.org/abs/2508.13144
https://allenai.org/blog/signal-noise
https://github.com/allenai/signal-and-noise
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/60890.html