
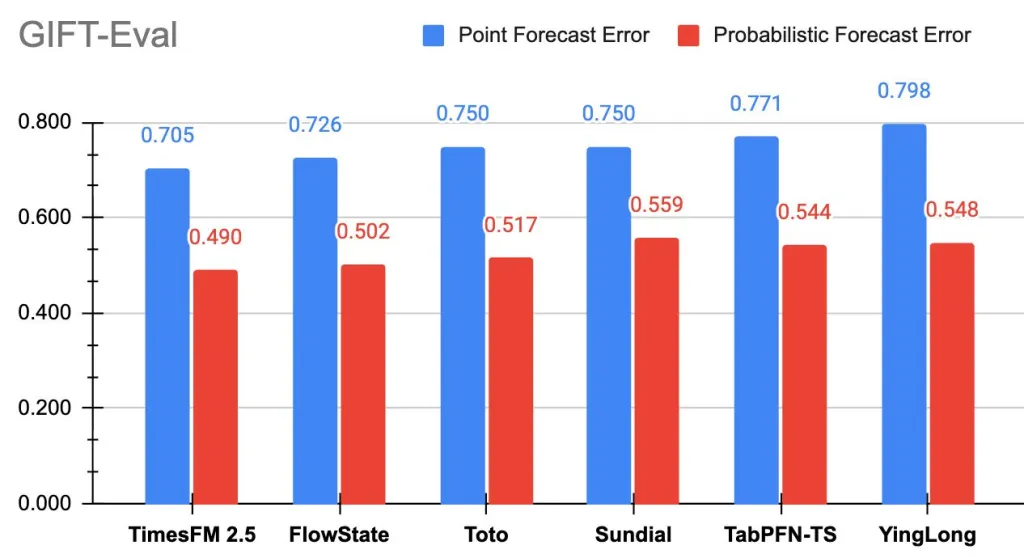
谷歌研究院发布了TimesFM-2.5,这是一个拥有 2 亿个参数、仅解码器的时间序列基础模型,上下文长度为 16K,并原生支持概率预测。新的检查点已在 Hugging Face 上线。在 GIFT-Eval(零样本预测)测试中,TimesFM-2.5 目前在零样本基础模型的准确率指标(MASE、CRPS)排行榜上名列前茅。

什么是时间序列预测?
时间序列预测是指分析随时间推移收集的序列数据点,以识别模式并预测未来值的一种实践。它支撑着各行各业的关键应用,包括预测零售产品需求、监测天气和降水趋势,以及优化供应链和电网等大型系统。通过捕捉时间依赖性和季节性变化,时间序列预测能够在动态环境中实现数据驱动的决策。
TimesFM-2.5与 v2.0 相比有哪些变化?
- 参数: 200M(低于 2.0 中的 500M)。
- 最大上下文: 16,384点(高于 2,048 点)。
- 分位数:可选的30M 参数分位数头,用于长达 1K 范围的连续分位数预测。
- 输入: 不需要“频率”指示器;新的推理标志(翻转不变性、正性推理、分位数交叉修复)。
- 路线图:即将推出的Flax实现,以实现更快的推理;协变量支持即将返回;文档正在扩展。
为什么更长的背景很重要?
16K 个历史点允许单次前向传播捕捉多季节结构、状态突变和低频成分,无需进行平铺或分层拼接。实际上,这减少了预处理启发式操作,并提高了上下文 >> 视界(例如,能源负荷、零售需求)领域的稳定性。更长的上下文是 2.5 版本明确指出的一项核心设计变更。
研究背景是什么?
TimesFM 的核心论点:一个单一的、仅使用解码器的预测基础模型,已在 ICML 2024 论文和谷歌的研究博客中提出。GIFT-Eval(Salesforce)的出现是为了实现跨领域、频率、视界长度和单变量/多变量机制的标准化评估,并在 Hugging Face 上托管了一个公共排行榜。
关键要点
- 更小、更快的模型: TimesFM-2.5 以200M 参数运行(2.0 大小的一半),同时提高准确性。
- 更长的背景:支持16K 输入长度,实现更深层次的历史覆盖预测。
- 基准测试领导者:目前在 GIFT-Eval 的零样本基础模型中,MASE(点准确度)和CRPS(概率准确度)均排名第一。
- 生产就绪:高效的设计和分位数预测支持使其适合跨行业的实际部署。
- 广泛可用性:该模型在 Hugging Face 上直播。
总结
TimesFM-2.5 表明,用于预测的基础模型正在从概念验证阶段迈向实用、可立即投入生产的工具。通过将参数减少一半,同时延长上下文长度,并在点精度和概率精度方面领先于 GIFT-Eval,该模型标志着效率和功能的显著提升。随着 Hugging Face 的上线以及 BigQuery/Model Garden 集成的即将到来,该模型有望加速零样本时间序列预测在实际流程中的应用。
参考资料:
https://huggingface.co/google/timesfm-2.5-200m-pytorch
https://github.com/google-research/timesfm?tab=readme-ov-file
https://arxiv.org/abs/2310.10688
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/61640.html