
动画上色是动画制作中的关键环节,然而现有动画线稿着色模型在保持颜色一致性和稳定性方面仍存在一定挑战。基于此我们提出了一种新颖的线稿视频动画上色模型-ColorAnime。ColorAnime以视频扩散模型为基础,可以根据参考图像自动将草图序列转换为彩色动画。首先我们将草图序列引入基于DiT的视频扩散模型,实现草图控制的动画视频生成。然后我们设计了一个 High-Level Color Extractor 来从参考图像中提取 high-level 语义颜色信息来指导草图上色。同时为了保证更加准确的细粒度颜色控制,我们引入了一个 Low-level Color Guider 来从参考图像中提取更加细粒度的颜色控制。最后,我们采用了多阶段训练策略来充分利用参考图像中的颜色信息指导草图序列上色。定性和定量结果证明了我们的方法在颜色准确度、视频质量以及草图对齐程度等方面的先进性。
文章来源:ACM MM 2025
论文题目:AnimeColor: Reference-based Animation Colorization with Diffusion Transformers
论文作者:Yuhong Zhang, Liyao Wang, Han Wang, Danni Wu, Zuzeng Lin, Feng Wang, Li Song (SJTU Medialab)
论文链接:https://arxiv.org/abs/2507.20158
内容整理:张雨虹
介绍
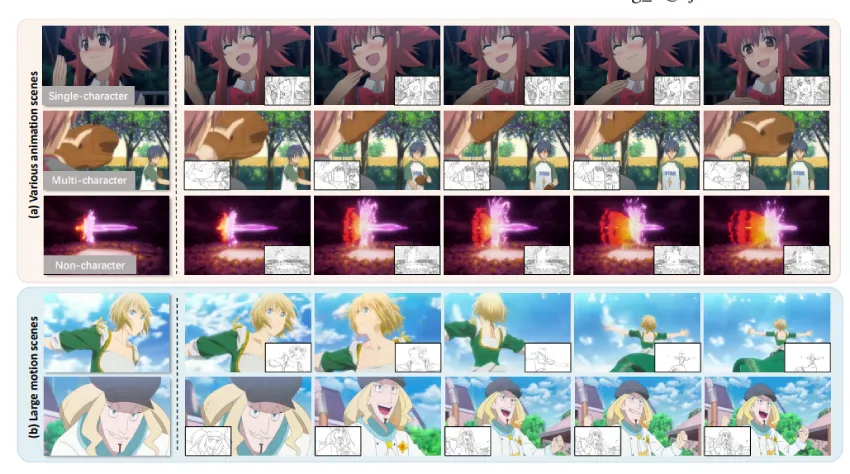

图1 给定一张参考图像和一系列草图,我们的方法能够生成高质量的上色动画视频。AnimeColor 在多种动画场景中表现出强大的鲁棒性,包括单角色、多角色以及非角色的场景。值得注意的是,它在具有大幅运动的挑战性场景中表现尤为出色,例如背面或侧面视角,以及角色的大动作变化,而这些往往是现有方法难以处理的情况。
卡通动画是一种流行的媒体和艺术形式。然而动画制作是一项劳动密集型工作。动画制作者一般先绘制动画草图然后对关键帧进行着色,再推广到全部帧。在着色过程中,保持动画风格和颜色的一致性至关重要,然而这一任务对于动画师是耗时耗力的。因此自动化处理这一这一过程对于降低劳动成本、加速动画内容创作具有重要意义。虽然之前的作品尝试动画化处理这一着色流程,但它们通常采用单独处理每一帧的方式,这会导致闪烁和不一致,影响动画的视觉感受。即使引入先前帧作为参考处理后续帧,也会造成误差累积,降低观看者体验。
近来,视频生成在扩散模型的推动下取得了巨大成功。因此研究者考虑将视频生成扩散模型引入到动画着色这一任务中,利用视觉生成模型中的先验知识来捕获连贯性视觉特征,保证时域一致性。LVCD 提出了一种处理长视频动画着色的方法,AniDoc 提出了一种人物动画着色的方法,当前方法在处理大幅运动场景、非人物场景、以及背景上色方面仍有所欠缺。Tooncrafter 也可以通过草图和关键帧控制视频生成,但是该方法在实际上色过程中会有明显的闪烁,且颜色一致性较差。此外,上述工作主要基于U-Net,无法适应新兴的基于DiT的视频模型。这一挑战可能源于 DiT 与 U-Net 相比的固有局限性,包括训练收敛的难度更大以及控制困难。
基于上述挑战,我们提出了一个基于DiT架构的有参考动画着色框架。该框架可以生成草图控制的颜色准确、时域稳定的高质量动画视频。我们首先将草图latents 与noise 合并在一起finetune 视频模型使其可以实现草图控制的动画生成。其次为了保证从参考图像中获取颜色信息来指导视频生成,我们设计了一个High-level Color Extractor 和 Low-level Color Guider 来分别捕获高级语义颜色和细粒度的颜色控制。细粒度颜色控制有助于保持跟参考图像颜色一致,但可能会出现颜色与语义不匹配,比如手臂与手颜色不一致。高级语义颜色可以保证语义颜色的一致性但是在细节方面颜色不准确。二者相互补充,使得我们的方法在颜色一致性方面取得了优异效果。此外,我们设计了一个多阶段训练策略来保证模块各司其职,同时保证时域一致性。我们的方法在解决单人、多人、大幅运动、以及非人物场景的动画着色问题都取得了优异的效果。定性和定量实验证明了我们的方法证明了在给定参考图像和草图序列的条件下生成高质量、颜色准确、时间一致性的动画的有效性。
方法概述
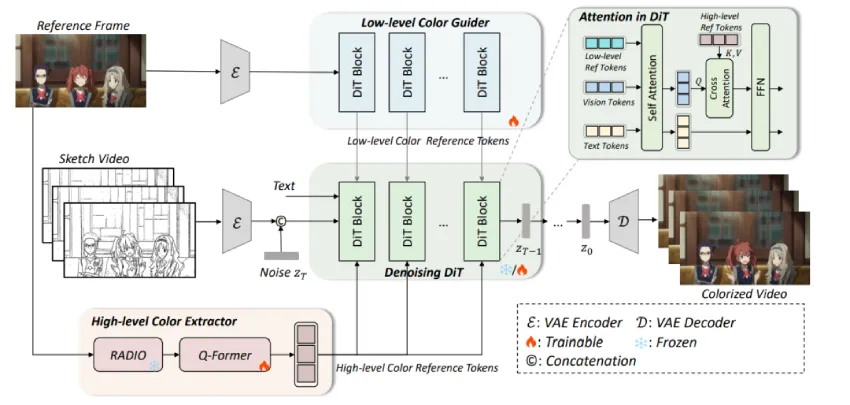
图2 我们提出的 AnimeColor 框架:首先,将草图的潜在表示与噪声拼接,作为去噪 DiT 的输入。随后,我们引入高层次颜色提取器和低层次颜色引导器,从参考图像中提取颜色信息,用于控制视频生成。颜色控制通过注意力模块融入去噪 DiT 中。此外,我们设计了一个四阶段训练策略,以确保各个模块的有效性。
给定一张参考图像和一段草图序列,我们的目标是生成一段动画视频序列,其结构与草图序列一致,颜色和风格与参考图像一致。首先,我们利用草图序列作为结构控制条件控制视频模型生成,我们使用 VAE Encoder 对草图序列进行编码。将编码得到的 latent 与初始噪声 concat在一起,送入扩散模型,实现草图控制的视频生成。
其次为了保证生成视频的颜色与参考图像一致,我们设计了 High-Level Color Extractor 和 Low-level Color Guider 来分别提取高级语义颜色token 和低级细粒度的颜色 token 来控制视频生成。我们通过 attention 结构来整合这些颜色控制,最终生成结构与草图对齐、颜色与参考图像一致且时域稳定的视频序列。
最后我们采用了多阶段训练策略,使各模块各司其职, 以生成结构与草图对齐、颜色与参考图像一致、时域稳定的动漫视频。
实验结果
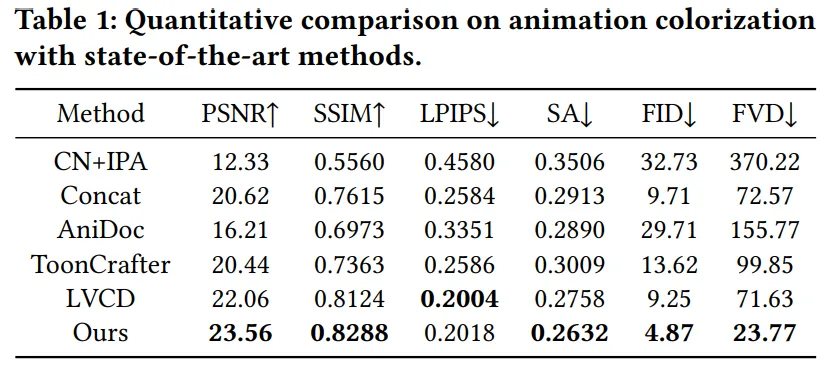
将所提方法与AniDoc、Tooncrafter 以及LVCD 进行了比较,定性和定量比较结果如下:


时域一致性比较:

所提方法在颜色准确性、草图对齐度以及时域一致性均取得了较好的效果。
结论
在这项工作中,我们提出了 AnimeColor,一种基于DiT的有参考动画上色框架,解决了现有动画上色方法所面临的挑战,特别是在包含运镜的大幅运动场景的动画上色方面。我们的方法包括整合sketch control 进行去噪DiT实现草图控制,并设计了High-level Color Extractor 和 Low-level Color Guider 来互为补充的从参考图像中提取颜色信息指导动画的颜色生成。为保证各模块的作用,我们提出了一种多阶段训练策略。我们所提出的动画着色方法在颜色准确度、草图对齐度、时域一致性以及视觉质量方面都取得了较好效果。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。