
谷歌人工智能研究团队通过引入语音转检索(S2R)技术,实现了语音搜索的重大突破。该技术将语音查询直接映射为嵌入向量,无需先将语音转为文本即可检索信息。谷歌团队将S2R定位为架构与理念的变革,旨在解决传统级联建模方法中的误差传播问题,使系统聚焦检索意图而非转录准确性。谷歌研究团队声明,语音搜索现已全面采用S2R技术驱动。

从级联建模到意图对齐检索
在传统的级联建模方法中,自动语音识别(ASR)首先生成单一文本字符串,随后将其传递至检索环节。微小的转录错误便可能改变查询含义,导致检索结果失准。S2R通过重新定义问题框架,聚焦于“用户寻求何种信息?”,从而绕开了脆弱的中间转录环节。
评估 S2R 的潜力
谷歌研究团队分析了词错率 (WER)(自动语音识别质量)与平均倒数排名 (MRR) (检索质量)之间的差距。团队使用人工验证的转录本模拟级联真实“完美自动语音识别”条件,并比较了 (i)级联自动语音识别(真实基准)与 (ii)级联真实(上限),结果发现较低的WER并不能可靠地预测不同语言中较高的MRR。基准与真实之间持续存在的MRR差距表明,直接从音频优化检索意图的模型仍有发展空间。
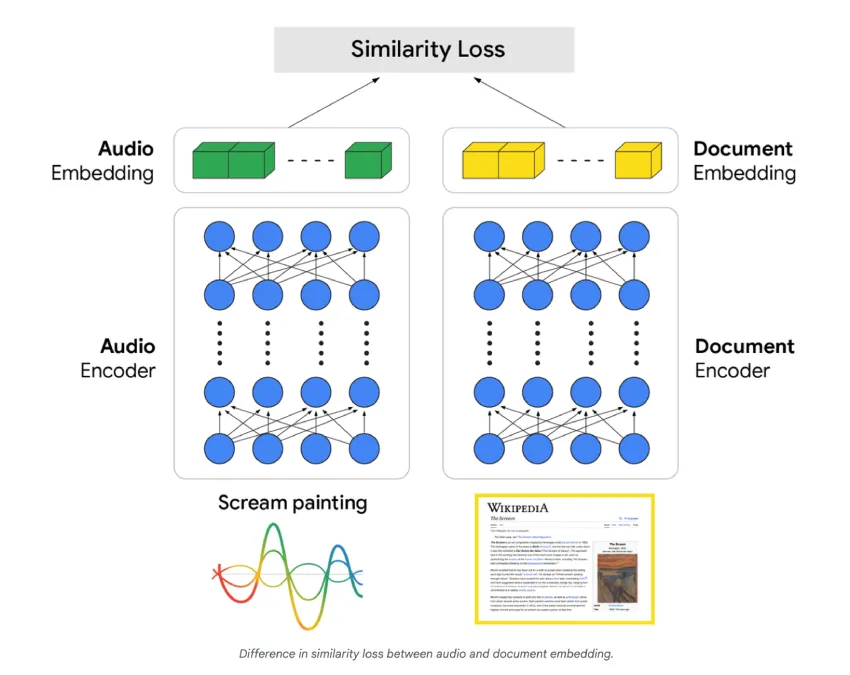
架构:双编码器联合训练
S2R的核心是双编码器架构。音频编码器将语音查询转换为丰富的音频嵌入,以捕捉语义含义;文档编码器则为文档生成相应的向量表征。系统使用配对数据(音频查询,相关文档)进行训练,使得音频查询的向量在表征空间中与其对应文档的向量在几何上接近。该训练目标将语音与检索目标直接对齐,并消除了对精确词序列的依赖。
服务路径:音频流传输、相似度搜索与排序
在推理阶段,音频数据流式传输至预训练音频编码器以生成查询向量。该向量用于高效识别谷歌索引中高度相关的候选结果集;随后,整合数百项信号的搜索排序系统计算最终排序结果。该实现方案在保留成熟排序架构的同时,将查询表示替换为语音语义嵌入。
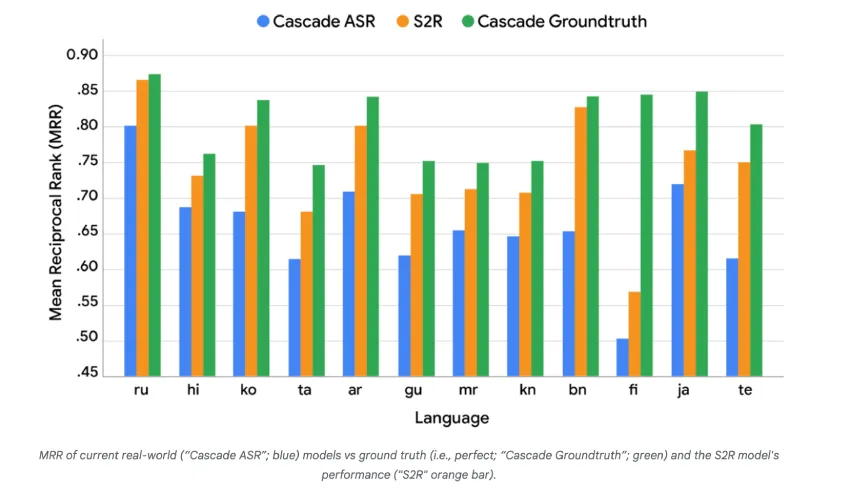
在 SVQ 上评估 S2R
在简单语音问题 (SVQ)评估中,本文对三个系统进行了比较:Cascade ASR(蓝色)、Cascade groundtruth(绿色)和S2R(橙色)。S2R的条形图显著优于基线Cascade ASR,并且接近Cascade groundtruth在MRR上设定的上限,但作者指出,仍有一些差距,可以作为未来的研究空间。
开放资源:SVQ 和 Massive Sound Embedding Benchmark (MSEB)
为了支持社区发展,Google 开源了Hugging Face 上的简单语音问题 (SVQ) :该数据集包含 26 个语言环境、17 种语言以及多种音频条件(清晰、背景语音噪音、交通噪音、媒体噪音)录制的简短音频问题。该数据集以未分割的评估集形式发布,并遵循CC-BY-4.0许可协议。SVQ是Massive Sound Embedding Benchmark (MSEB)的一部分,MSEB 是一个用于评估跨任务声音嵌入方法的开放框架。
关键要点
- 谷歌已将语音搜索转移到语音检索(S2R),将语音查询映射到嵌入并跳过转录。
- 双编码器设计(音频编码器+文档编码器)将音频/查询向量与文档嵌入对齐,以进行直接语义检索。
- 在评估中,S2R 的表现优于生产 ASR→检索级联,并接近MRR 上的真实转录上限。
- S2R 已投入生产并提供多种语言服务,并与 Google 现有的排名堆栈集成。
- 谷歌在MSEB下发布了简单语音问题 (SVQ)(17 种语言、26 种语言环境),以标准化语音检索基准测试。
总结
语音到检索 (S2R)是一项意义深远的架构修正,而非表面功夫的升级:通过用语音原生嵌入接口取代 ASR→文本铰链,谷歌将优化目标与检索质量保持一致,并消除了主要的级联误差源。产品化部署和多语言覆盖至关重要,但现在真正有意义的工作是投入运营——校准音频衍生的相关性得分,对代码转换和噪声条件进行压力测试,并在语音嵌入成为查询关键字时量化隐私权衡。
参考资料:
https://research.google/blog/speech-to-retrieval-s2r-a-new-approach-to-voice-search/
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/62094.html