
实时视频通信系统广泛发展,深入大众的日常生活。然而,现实世界的网络状况不总能令人满意,特别是在地铁或拥挤的公共场所等带宽受限的环境中,现有的实时通信(RTC)系统均难以维持最优性能。在本文中,我们提出了GenRTC,这是一种生成式视频会议系统,旨在通过集成联合、可伸缩的生成式人脸编码与网络感知自适应机制来缓解带宽限制。该方法显著提升了系统对网络波动的鲁棒性,确保了在广泛的带宽场景下均能实现低延迟、高保真的视频会议。GenRTC在延迟-质量联合自适应编码控制器中集成了传统视频编解码器和生成式人脸视频编码,该控制器能够根据不同网络状况,动态选择最合适的编码方案,从而在实时应用的延迟约束下最大化感知质量。此外,GenRTC结合了带宽预测模块,能够提供准确且具有时序稳定性的低带宽估计。实验结果表明,GenRTC实现了良好的延迟-质量折中。在200 Kbps 低带宽环境下,GenRTC将平均帧超时率从60.4%降低至5.4%。在相似的丢帧率下,它将PSNR提升了7.2dB。特别是在20Kbps的极端低带宽环境下,GenRTC实现了8%的低帧超时率和32dB的高PSNR,而传统的RTC系统在如此超低带宽下无法正常运行。
文章来源:IEEE Transactions on Broadcasting 2026
论文题目:GenRTC: Generative Real-Time Video Conferencing via Joint Adaptive Coding and Bandwidth Estimation
论文链接:https://ieeexplore.ieee.org/document/11424031
论文作者:Bingcong Lu, Jun Xu, Zhengxue Cheng, Rong Xie, Li Song and Wenjun Zhang (SJTU Medialab)
内容整理:卢冰聪
简介
视频会议和直播的需求日益增长,但在地铁或拥挤的公共场所等低带宽环境中,网络波动极大 。传统的实时通信(RTC)系统在这种条件下往往会崩溃 。比如,Zoom的技术报告声明点对点通话至少需要600Kbps,Facebook的论文中也建议需要稳定的200Kbps才能保证通话质量 。因此,如何在低带宽下维持高质量通信,成了亟待解决的难题。目前的技术优化方向主要有两个:更高效的视频编解码器和更智能的带宽估计器 (BWE) 。
编解码器方面:传统的WebRTC编码器(如VP8/VP9等)虽然稳定,但在像素级压缩上已遇到瓶颈。近年来,生成式人脸视频编码(GFVC)发展迅速,它通过提取关键点等“稀疏表示”方法,能将会议画面极限压缩到10KB级别,非常适配低带宽通信。但目前的GFVC系统通常使用配置固定,缺乏应对网络波动的自适应能力,也无法很好地平衡延迟和画质。
带宽估计器方面:传统的基于规则的估计器(如GCC)机制僵化。虽然现在引入了强化学习(RL)来预测带宽,但低带宽场景有其特殊的陷阱:一旦高估了可用带宽,系统恢复起来极慢,会导致严重的视频卡顿 ;此外,在总带宽极低时,音频流和数据包头占据的比例会变得非常大,如果估算时忽略这些开销,视频传输就会严重受阻。


为了解决上述痛点,本文提出了一种名为GenRTC的新型实时视频会议系统,专门针对200Kbps以下的低带宽场景,将生成式编码的超高压缩率与动态网络自适应机制有效结合在了一起。如图1所示,相比于传统系统(网速差就卡死)和纯生成式系统(网速好时浪费资源),GenRTC能够在传统编码和生成式编码之间智能切换。GenRTC的核心贡献包含以下三点:
- 提出联合自适应控制器AdpCodex:该模块可以让生成式人脸编码与传统编码器在 WebRTC 框架下协同工作。它能根据实时可用带宽,在“低延迟”和“高画质”之间找到最佳平衡,动态调整编码方案。
- 提出低带宽估计器LowBandEst:采用离线强化学习训练,专门针对低带宽场景优化。加入了平滑滤波、带宽分解和快速拥塞恢复三项后处理机制,有效防止了对带宽的高估
- 实验结果显示:在低带宽测试中,GenRTC 将严重延迟(超时 200ms)的数据帧比例从平均60.4%大幅降至5.4% 。在同等丢帧率下,画质(PSNR)提升了高达7.2dB,实现了即使在极低带宽(如20Kbps)下也能流畅通信。
方法描述
GenRTC整体架构

如图2所示,GenRTC沿用经典的发送端-接收端架构:
- 发送端:负责传输媒体数据,根据当前的配置决定使用哪种编码器(VPX或者GFVC)。如果启用了 GFVC,发送端会在传输前将不同类型的流打包组装,并以预估的带宽作为编码器的目标码率进行编码。
- 接收端:负责接收数据并统计丢包和延迟信息,用于估算可用带宽。随后,系统会根据带宽、延迟和画面质量的综合情况,选出最优配置,并通过反馈控制信息传回发送端 。
媒体数据的具体处理流程如下(如图2中的实线所示):
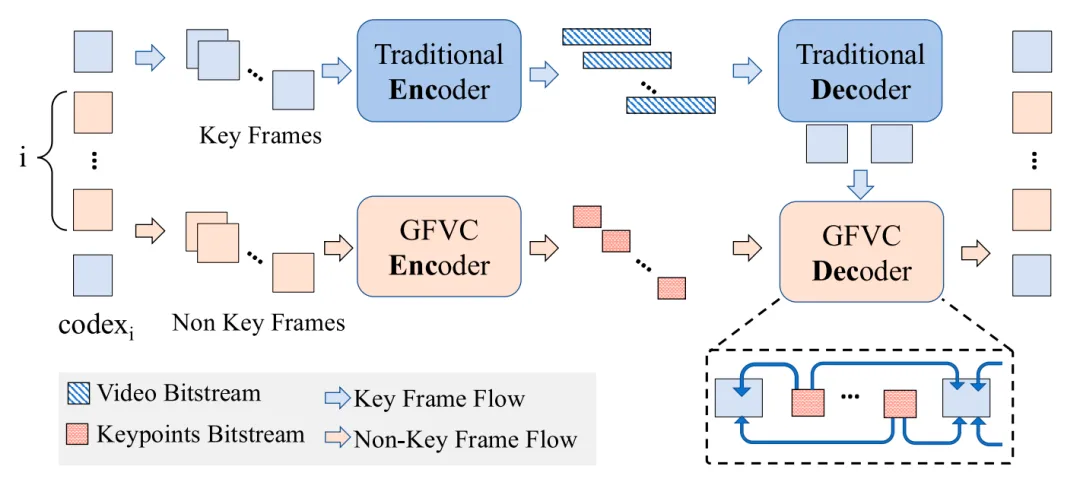
- [1]帧调度 (Frame Scheduling):该模块根据编码方案设定值cdxi,将传入的帧分类为关键帧 (KF) 和非关键帧 (NKF) 。cdxi 对应于 i+1 的 KF 采样频率。具体来说,对于每组长度为 i+1 的帧,第一帧是KF,使用传统编码器进行编码,其余的帧 i 使用 GFVC 。如果是cdx0,则不启用 GFVC,所有帧都由传统编码器进行编码 。在实践中,帧调度器会维护一个帧类型占用表,以确保完全传输给定 cdxi 设置的完整帧集 。
- [2]编码 (Encoding):KF编码利用传统编码器VPX,输出视频比特流。NKF由生成式编码器处理,并紧凑地表示为一组关键点(KP)。然后,生成的KP比特流与常规视频比特流一起传输。在这种架构下,生成式编码器被实现为RTC系统内的可插拔模块,从理论上讲,这使得集成各种GFVC技术成为可能,从而提供强大的可扩展性和多功能性。
- [3]组装 (Assembly):在将编码数据发送进行RTP打包之前,这两种比特流将被组合在一起,如图3所示 。关键点比特流及其相应的长度字段被附加到常规编码视频比特流的末尾 。系统会进一步插入一个额外的字节来指示当前有效负载中包含的关键点数量,从而有助于接收端的有效解析和分离。组装后,组合的比特流将使用标准的 RTP 打包和交付流程进行传输。关键点被附加到视频比特流中进行传输,而不是通过单个流单独传输,这具有以下优点:它消除了对额外通道的需求,从而降低了资源开销。很容易保证同步,因为关键点及其相应的参考帧不需要额外的时间戳信息来进行同步,从而减少了对额外传输内容的需求。它有效地减少了数据包的数量,降低了在有限网络带宽内数据包头的比例。
- [4]拆分 (Disassembly):接收后,组合的比特流被解析为视频比特流和KP 比特流。视频流被转发到VP9解码器,而KP流则根据 cdxi 和段长度信息被提取,并传递给GFVC解码器。
- [5]解码 (Decoding):传统视频解码器解码视频比特流以重建关键帧。点解码 (Point Decode) 模块解码KP比特流,产生重建的关键点 。
- [6]生成 (Generation): 生成模块通过利用KF和重建的KP来合成完整的重建视频。详细的合成过程会在后续章节中描述。

控制流处理的流程(如图2中的虚线所示)主要涉及收集网络信息并做出控制决策:
- [1]带宽估计器 LowBandEst:该模块汇总延迟和丢包统计数据以构建150维网络状态向量,该向量被输入到估计器中以产生初始带宽估计,然后应用后处理和带宽分解以得出最终的可用视频带宽 bwall。
- [2]延迟-质量联合自适应编解码控制器 AdpCodex:给定 bwall 和当前的延迟预算,该模块选择最大化视频质量的最佳配置 cdxi 。它进一步估计KP传输所需的带宽,并计算视频比特流的剩余带宽,表示为 bw 。
- [3]反馈信号(Feedback):估计的带宽 bw 和所选配置 cdxi 封装在RTCP包中并反馈给发送端。具体来说,cdxi 指导帧调度和编码器选择,而 bw 用于码率控制。
基于离线强化学习的低带宽估计器 (LowBandEst)
在实时通信系统中,在线强化学习(Online RL)需要与真实网络环境进行持续交互,这不仅耗时,而且在低带宽场景下,不准确的带宽估计极易导致通信中断,从而难以收集到稳定的训练轨迹。为了克服这一局限性,GenRTC系统使用了一种基于离线强化学习(Offline RL)的带宽估计器 LowBandEst,利用预先收集的数据实现更稳定、高效的模型训练。该模块主要由核心的离线强化学习模型与针对低带宽优化的后处理机制两部分组成:

离线强化学习模型
该模型通过在大规模网络传输轨迹数据集上模仿专家算法的行为进行训练 。为了平衡行为模仿与泛化能力,系统结合了 BCQ 和 TD3+BC 两种经典的离线强化学习框架。状态空间(State):模型的输入是一个 150 维的网络观测向量,包含接收速率、延迟、丢包等15种底层网络特征在短期(60ms)和长期(600ms)内的统计信息。奖励函数(Reward Function):训练目标以用户体验质量为导向。模型将音频和视频的客观质量评分(MOS)作为正向奖励,同时将数据包丢失率和排队延迟作为惩罚项引入损失函数。Actor-Critic 网络架构如下:
- Actor 网络: 内置了一个变分自编码器(VAE),用于学习数据集中的动作分布并缓解外推误差。在推理阶段,VAE 的解码器会根据当前网络状态生成多个候选的带宽预测动作。
- Critic 网络: 采用 Clipped Double Q-learning 算法,通过两个价值网络评估候选动作,并取其最小值以避免对带宽价值的高估,最终输出具有最高 Q 值的预测结果 。
针对低带宽优化的后处理机制 (Post-Processing)
由于极低带宽环境对预测误差的容忍度极低,系统在强化学习模型输出初始估计后,引入了三个关键的后处理模块,以提供更合理的编码码率指导 。
- 拥塞快速恢复 (Fast Recovery): 即使模型具备预测能力,系统仍增加了一层“失效保护”机制。通过提取过去一段时间内数据包往返时间(RTT)的梯度变化来进行粗略的拥塞评估。一旦检测到拥塞,系统会采用乘性减小策略(Multiplicative Decrease)迅速降低码率,以实现快速恢复。
- 卡尔曼滤波 (Kalman Filtering): 为了防止偶尔的异常高估导致整个预测周期内的网络拥塞,系统采用了一阶卡尔曼滤波器对输出的预测带宽进行平滑处理,有效抑制了瞬态波动。
- 可用带宽精准分解 (Bandwidth Decomposition): 这是低带宽优化中最核心的步骤之一。在常规带宽下,媒体数据占主导地位;但在低带宽下,音频流以及 SRTP、UDP、IP 等底层协议数据包头的开销占比增大。如图5和图6所示,给定不同的视频编码目标码率,视频码率越小,视频有效载荷占比越少。因此需要该模块从总估计带宽中扣除音频和控制信令、包头等其他数据的固定开销,计算出真正可用于视频编码的“净可用带宽”。


延迟-质量联合自适应编解码控制 (AdpCodex)
GenRTC 的核心思想是将生成式人脸视频编码与传统编码器结合,从而能够自适应地选择具有最佳率失真(RD)性能的编码机制 。该混合生成式编解码器提供 5 种不同的编码方案(记为 cdxi)。具体而言,cdxi 表示在每 i+1 帧中,第一帧作为关键帧(KF)使用传统编解码器压缩,其余的 i 帧作为非关键帧(NKF)使用 GFVC 压缩。特别地,cdx0 方案代表不启用生成式编码,所有帧均由传统编解码器处理。在 GenRTC 的生成式编码模块中,每个非关键帧被表示为一组紧凑的关键点 。这些关键点经过量化、预测和零阶指数哥伦布编码后,形成极低码率的关键点比特流。解码端则利用双向预测方法,结合这些关键点及其前后相邻的两个关键帧,来精确重建目标非关键帧。
基于这种混合编码架构,我们提出了一种延迟-质量联合自适应编解码控制器——AdpCodex,用于在给定的带宽码率指导下,动态选择最优的编码方案 cdxi 。视频会议的用户QoE主要受视频质量和播放流畅度影响。在延迟保持在用户可接受范围内的前提下,致力于提升视频质量往往能带来更大的收益。因此,AdpCodex 的核心动机就是在延迟和视频质量之间寻找最佳的权衡点。该控制器的决策过程主要包含以下三个核心维度:
- 延迟预算 :在RTC中,200ms通常被视为用户可接受的延迟上限,因此我们将200ms设定为目标延迟阈值,并将 GenRTC 中每一帧的端到端延迟严格拆解为四个部分 :编解码时间 (tcodec),即传统编码和解码所需的时间总和(例如 VP9 编码器约需 40 毫秒);传输时间(ttrans),低码率下视频帧通常可被打包在一个独立的数据包中,该时间可通过近期网络的平均往返时延(RTT)来估算;等待时间 (tintv),由于在 cdxi 方案中,前 i 个非关键帧必须等待与第 i+1 个关键帧一起打包传输,这种机制带来的固有缓冲等待时间;以及生成时间 (tgen),在接收端合成和生成画面所需的计算时间。系统会实时计算剩余的延迟预算,任何会导致总延迟超标的编码方案都将被直接否决。
- 质量估计:考虑到视频会议场景中内容的相似性(大多为说话人的头部画面),系统合理地假设在相同的编码方案下,编解码器的率失真性能在不同视频中基本保持一致。基于这一预设,系统无需在运行时进行高昂的实时质量评估,而是预先统计了不同目标码率和各编码方案下的画质表现,构建了一个“码率-画质”的映射查询表 。这为后续的快速决策提供了极其可靠且低算力成本的参考依据。
- 延迟-质量联合自适应:联合自适应的最终数学优化目标是:在满足当前目标延迟约束的前提下,最大化视频的输出质量。具体在算法执行时,AdpCodex 会遍历所有的编码方案,确保候选方案的延迟预算大于零。随后,在可行的方案池中查表,选出能够提供最高预估画质的最佳方案 cdxi。一旦最佳编码方案被确定,系统还会进行极其精细的带宽二次分配:从预估的总可用带宽中,精确扣除关键点比特流所需的数据量以及 RTP 协议包头开销,最终计算出真正可供视频流使用的实际带宽 。
系统实现
RTC 基础系统的深度改造
GenRTC 构建于 AlphaRTC 仿真平台之上,该平台在底层的 C++ 核心上封装了 Python 接口,便于灵活调用带宽估计模块。编码器方面,系统默认选用压缩性能更佳的 VP9,但我们将 VP9 的最大量化参数上限从 52 拉高至 63,从而使得编码器能够吐出低至 10Kbps 的极低码率视频流。采用 Opus 音频编码器,并将其默认码率设置为6Kbps,为视频流让出宝贵通道。同时,我们修改了底层的 RTP 数据包头,将帧序号嵌入其中,确保接收端能够轻松完成乱序包的重排和帧对齐。
生成式人脸视频编码的训练与加速
我们使用了DFDC数据集,从中抽取了 15,000个高质量的说话人头部视频(分辨率 256×256,帧率 30 FPS)。为了适配系统需要使用的 cdx1 到 cdx4 这四种不同的非关键帧采样频率,我们分别独立训练了四个专属模型。在实际部署时,原始的 PyTorch 模型被转换为轻量级的 ONNX 中间格式,并进一步采用 NVIDIA 的 TensorRT 引擎进行了优化。
带宽分解细节介绍
系统对底层协议开销进行了详细的拆解:每一个搭载媒体数据的SRTP网络包(58字节),在传输时会携带UDP(8字节)、IP(20字节)和以太网(14字节)三层协议头。如果再算上长度可变的 SRTP 加密和扩展头,单个数据包的纯头部开销就高达约 100 字节。6Kbps的音频码率将在一个 200ms 的预测周期内产生大约 10 个音频数据包。系统会将这 10 个音频包的载荷连同它们的协议头开销,以及周期末尾发送的 RTCP 信令开销(最大 112 字节)一并从总带宽中扣除,从而得出视频可用的“净可用带宽”。
离线强化学习模型的训练与清洗
带宽预测模型的训练使用来自微软开源的包含上万次通话测试的数据集,其中记录了各类专家算法(如 GCC、UKF)的决策轨迹。但专家的表现也有优劣之分,因此团队对数据进行了简单过滤:只有当专家算法的预测值与真实网络容量的误差小于 50 Kbps 时,这段数据才被认为是“好轨迹”并予以保留。过滤后保留了3348 条优质轨迹作为训练集。该模型在 RTX 4090 显卡上经过 800 轮,其最终体积仅为2MB,单次推理耗时约2ms,适用于广泛的RTC 场景。
系统评估与实验分析
实验设置
实验随机选取了 20 个分辨率为 256×256、帧率为 30 FPS 的说话人头部视频作为输入源。网络模拟采用 Mahimahi 工具,我们构建了包含 100 个平均带宽低于 200Kbps 轨迹的公共测试集 (PublicNetSet) 。同时,还构建了波动范围在 60-200Kbps、波动间隔极短的自定义高频波动测试集 (CustomNetSet_HighFluc),以模拟极端的弱网环境。实验以传统的 WebRTC 系统(采用 VP9 编码器与 GCC 带宽估计器)作为直接对比基线。画质评估采用了 VMAF、PSNR 以及更能反映生成式画面人类感知质量的 LPIPS 指标。在延迟方面,我们定义了“超时率 (Missrate)”,即端到端传输延迟超过 200 毫秒的数据帧所占的比例。
整体性能
实验结果显示,GenRTC展现出了低延迟和视觉感知的最佳平衡。在各类波动网络中,GenRTC 的超时率基本控制在 0.1(10%)以下,即使在极高波动的网络中,超时率也没有超过 0.4。相比之下,传统基线系统由于给出的目标码率过高,导致传统编码器需要传输大量包含沉重包头的数据,在低带宽下引发了极高的超时率。 尽管传统基线系统在客观画质得分(如 VMAF/PSNR)上看似较高,但这完全是建立在错误且激进的码率指导之上的,导致了大量的丢帧和播放停滞,严重破坏了用户体验。GenRTC 做出了一种可控的权衡:在极低的超时率下,其 LPIPS 视觉感知质量与基线系统极为接近(仅轻微下降 0.008),证明了 GenRTC有效突破了传统系统在低带宽下无法进行高质量和低延迟实时通信的瓶颈。

如下图所示,子图 (1) 展示了在相对稳定的公共网络数据集 (PublicNetSet) 中的测试结果 。子图 (2) 展示了在简单波动网络中的测试结果,子图 (3) 则展示了在具有挑战性的高频波动网络中的测试结果 。将其他三个系统与基线系统进行对比表明,本文提出的自适应生成式人脸视频编码(GFVC)和新型带宽估计器,可以显著提升低带宽网络下 RTC 系统的性能。

带宽估计器消融分析
- 模型带宽预测更精准:相比于对比算法 Schaferct,本文的 RL 模型展现出了更低的均方误差 (MSE)。Schaferct 在低带宽场景下存在高达数百 Kbps 的致命高估波动,而我们提出的 LowBandEst 则能提供稳定且精确的估算。如下图表明,LowBandEst 的估计准确度能够超越数据集中的专家算法和当前SOTA算法,同时其预测结果也表现得更加稳定。

- 后处理模块不可或缺:如下图所示,LowBandEst 中的每一个后处理模块都对最终的优异性能做出了贡献。在移除“带宽分解 (w/o decom)”模块后,系统会给出过高的视频编码码率,导致延迟显著飙升。如果移除“拥塞快速恢复 (w/o FR)”,系统将无法应对偶发的超调,引发排队延迟不断累积。若缺失“卡尔曼滤波 (w/o KF)”,则会导致预测结果出现剧烈的过冲和过低震荡。

联合自适应模块消融分析
如图11所示,当不考虑网络情况时,AdpCodex 能够精准找出特定码率下提供最高画质的编码配置。当在网络链路中人为加入固定延迟时,如图12,传统纯生成式方案(如 cdx4)会因其固有的多帧等待机制导致超时率严重恶化。此时,AdpCodex 能够考虑延迟限制,灵活切换方案,将超时率维持在合理水平。


如图13,在动态的波动网络中,AdpCodex 综合当前延迟约束和预估画质,动态选择最优的 cdxi。最终在确保较低超时率的同时,实现较高的整体视频质量。

算力消耗与系统实时性
生成式神经网络的引入不可避免地会增加系统的计算负担,但GenRTC展现出了极高的轻量化和实时处理性能。具体而言,GenRTC 主要引入了三个关键的神经网络组件:生成式人脸视频编码(GFVC)编码器、GFVC 解码器以及基于强化学习的带宽估计器。为了全面评估其计算需求,我们详细统计了系统的平均运行时间和浮点运算次数(FLOPs)。实验结果显示,GenRTC 核心模块的单次推理计算量仅为 308.79 GFLOPs,这一计算负载完全在现代智能手机和 PC 处理器可应对的范围内,具备广泛的设备适用性。端到端响应速度方面,在 100 Kbps 目标码率下,GenRTC 的端到端总延迟(涵盖编码提取、理想信道传输、解码与画面生成)仅约为 40ms,展现出良好的实时能力。
总结
在本文中,我们提出了一种名为 GenRTC 的新型生成式实时通信系统,专为应对低带宽场景而设计。通过将生成式人脸视频编码与延迟-质量联合自适应控制算法、低带宽估计器深度集成,GenRTC 即使在极端的网络条件下,依然能够在视频画质和传输稳定性上实现显著的提升。所提出的自适应的编码内容组织与传输架构,确保了其与标准视频编码器的良好兼容。自适应编解码控制算法赋予了系统根据实时网络状况,在不同编码方案之间进行无缝智能切换的能力。此外,所设计的带宽估计器基于细致的流量拆解分析,不仅提供了更精确的码率指导值,还有效解决了低带宽环境下极易出现的预测高估与不稳定性难题。总之,本项工作为生成式实时通信提供了一种优秀的系统级集成与优化方案,彰显了该技术在真实世界低带宽通信场景中广泛落地与应用的潜力。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。