
本文内容来自公众号“子鱼说声学”。
链接:https://mp.weixin.qq.com/s/-Nowe9bWJpLaTyDosNuk8A
近期,清华大学、剑桥大学与字节跳动的研究团队提出了一种让大语言模型(LLM)理解空间音频的新方法。与当前多模态大模型只能解析普通音频不同,这项工作让 LLM 有初步“听懂”三维空间中声音方向与定位的能力。
这项研究围绕三个核心任务展开:声音源定位(SSL)、远场语音识别(FSR)以及基于定位的语音提取(LSE)。
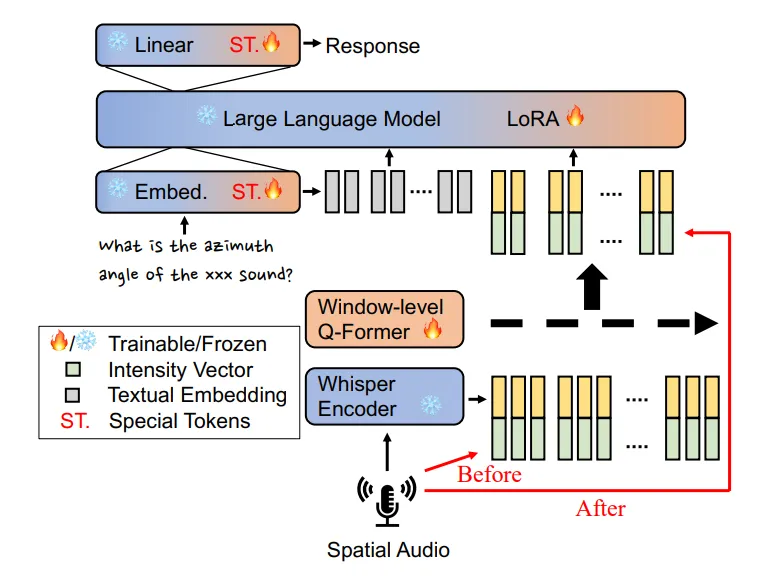

- 在声音源定位方面,研究团队采用了一种创新方案,将四通道空间音频的空间矢量特征引入 LLM 的输入,使模型能够精准判断声音的空间角度。实验结果显示,模型在 Spatial LibriSpeech 数据集上将平均角度误差降至 2.7 度,较此前基线的 6.6 度有显著提升。
- 对于远场语音识别,模型结合空间特征后,词错误率也进一步降低,证明 LLM 能借助空间信息提升理解能力。
- 在基于定位的语音提取任务中,模型可根据指令区分、提取指定方向的声音,即使在多个说话者同时存在、语音重叠的场景下仍能有效完成任务。
方法上,团队选择冻结主流 Whisper 语音编码器和 LLM,仅对连接两者的对齐模块以及部分特定层进行微调。空间信息的注入点选择在模型的中间层,效果优于末端融合。此外,研究未发现将方向角度单独作为特殊标记加入模型词表能带来额外收益。
团队还用真实房间声学仿真,合成了大量复杂空间音频数据,为 LLM 学习空间感知和多声源分离提供支撑。整体实验展现了 LLM 在空间听觉理解和复杂三维场景感知上的独特潜力,展示了 AI 未来以“听觉体”角色融入现实世界的广阔前景。
这项工作为 LLM 从“只会听内容”迈向“理解现实空间”提供了关键一环,并为后续智能体在虚拟或真实三维环境中的感知和交互奠定了基础。
文章来源:https://arxiv.org/pdf/2406.07914
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。