
随着以智能助手为代表的人机语音对话系统和会议转录与纪要等应用的爆发,对话语音识别(Conversational ASR) 技术变得愈发重要。对话语音(Conversational Speech)具有高度的上下文(Context)相关性,而擅长长上下文理解和推理能力的大语言模型(LLM)可以促进对话语音识别技术的进一步发展。如何从整个对话历史中检索并选择与当前话语最相关的历史上下文以增强对话语音识别的性能,是我们的研究目标。
最近,西北工业大学音频语音与语言处理研究组(ASLP@NPU)与南洋理工大学合作的论文“Hearing More with Less: Multi-Modal Retrieval-and-Selection Augmented Conversational LLM-Based ASR”被人工智能研究领域顶级会议AAAI 2026接收。该论文提出了一种多模态检索和选择最佳历史上下文以增强对话语音识别的方法。现对该论文进行简要的解读。
论文题目:Hearing More with Less: Multi-Modal Retrieval-and-Selection Augmented Conversational LLM-Based ASR
作者列表:穆秉甡,刘和鑫,薛鸿飞,魏坤,谢磊
合作单位:南洋理工大学
论文预印版:https://arxiv.org/abs/2508.01166
背景动机
语音识别(ASR)旨在将人类的语音内容转换为相应的文本。随着语音对话系统、会议转录等应用的发展,对话ASR正变得日益重要。典型的ASR场景涉及单说话人近讲语音。然而,多人讲话的对话语音体现了人类交流的复杂性,包括多样的说话风格(如特定说话人的发音和词汇偏好)、副语言现象(如填充词、口吃和修正)以及高度的上下文相关性。以往的研究表明,融入前序话语中的语音和文本模态上下文能显著提升对话ASR的性能[1, 2]。
大型语言模型(LLMs)展现出卓越的长上下文理解和推理能力,使其成为对话ASR中颇具前景的解决方案。近期将LLM与对话ASR相结合的研究,涉及对LLM-ASR模型进行扩展,额外输入两种类型的上下文,即固定数量的前序话语和整个对话历史。前者假设与当前话语最相关的历史上下文出现在前几个话语中,却忽略了这些话语包含大量填充词和其他语义无关的上下文,这会严重影响当前话语的ASR性能。然而与当前话语最相关的历史上下文的位置并不固定,它可能位于更早的对话历史中,超出固定数量的前序话语范围。后者将整个对话历史作为上下文,虽然提供了更丰富的上下文,但不可避免地会导致冗余信息干扰ASR,并且会产生巨大的计算成本。这些局限凸显了需要一种更高效且上下文有效的对话历史利用策略。因此,研究问题可总结为:如何检索和选择与当前话语最相关的历史上下文,以增强对话LLM-ASR的性能。
检索增强生成(RAG)为对话LLM-ASR提供了一种潜在的解决方案,因为它能通过将大规模外部知识检索系统与LLMs相结合,增强文本生成的准确性、时效性、可验证性和领域特异性。然而,RAG在对话式ASR中的适应性有限。RAG侧重于基于检索到的文本生成新内容,而ASR旨在将语音映射为文本,因此两者的目标存在根本差异。此外,RAG检索到的大量内容可能会导致ASR中的信息过载,掩盖需要识别的语音。尽管如此,RAG的设计理念可应用于从对话语音中检索和选择最佳历史上下文,以辅助当前话语的识别。
因此,本文提出了一种名为MARS的多模态检索与选择方法,用于增强对话LLM-ASR。MARS检索并选择与当前话语长度相当的历史上下文,在去除冗余的同时,保留整个历史中最相关的信息。在Interspeech 2025多语言对话语音语言模型(MLC-SLM)挑战赛数据集上[3]的实验验证了MARS的有效性。仅使用1500小时的训练数据,MARS就实现了显著更低的混合错误率(MER),优于该挑战赛中排名第一的采用专门设计且通过179K小时数据训练的LLM-ASR,在MLC-SLM数据集上达到了当前最优水平。

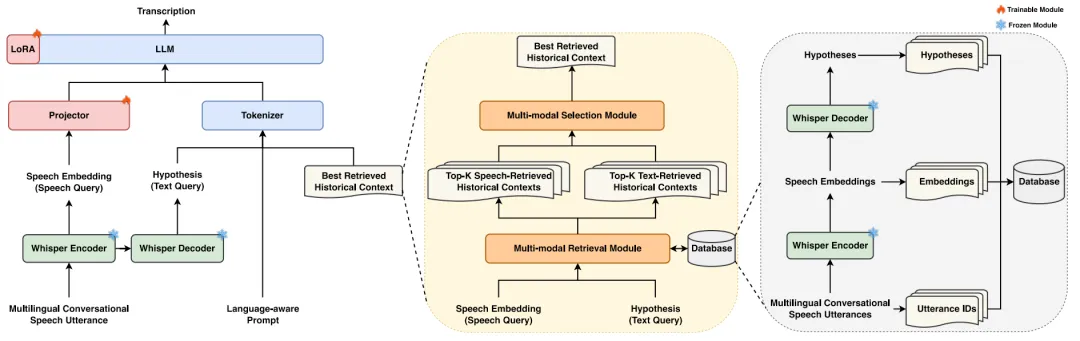
提出的方案
MARS的目标是通过多模态检索和选择方法,确定当前话语的最佳历史上下文,从而ASR的准确率。图2展示了MARS的整体框架。Database是利用完全微调的Whisper构建的,它为对话语音中的每个话语存储了一个三元组,包括话语的ID、语音嵌入和假设。在MARS中,语音嵌入和假设分别作为语音查询和文本查询。多模态检索模块利用这些查询从Database中检索出最相似的前K个历史上下文。但是在检索之后,多个历史上下文由于信息冗余仍然会导致ASR预测混淆,而且过长的历史上下文会消耗大量计算资源。而多模态选择模块从检索到的历史上下文中确定最佳的。最后,将一个具有语言感知的提示词、检索到的最佳历史上下文、当前话语的语音嵌入及其假设输入到LLM中,通过低秩适应(LoRA)以预测转录结果。
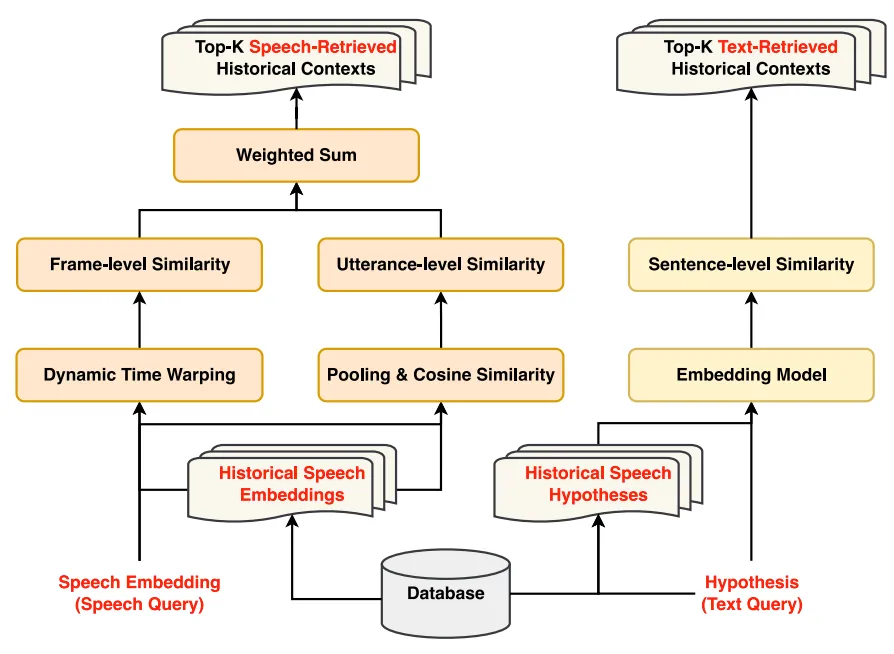
多模态检索
在对话ASR中,语音和文本两种模态都承载着关键的上下文信息。仅依赖单一模态无法全面检索出对话中与当前话语相似的历史上下文。相比之下,多模态检索从语音和文本两个角度衡量历史上下文的相似度,从发音和语义两个方面为当前话语提供历史上下文。通过语音模态检索到的历史上下文能够减少因发音变化导致的ASR错误,而通过文本模态检索到的历史上下文则可以减少因词语歧义引发的ASR错误。图3展示了多模态检索模块的详细流程。在语音模态检索中,我们采用动态时间规划(DTW)来计算当前语音嵌入与历史语音嵌入之间的帧级声学相似度。DTW通过计算两个语音嵌入之间的匹配路径来确定它们的最小累积距离。然而,传统的DTW计算复杂度极高。为当前话语检索大量历史语音嵌入可能会耗费大量时间。因此,我们使用FastDTW[4],它在保持高精度的同时显著降低了计算复杂度。此外,我们通过对当前和历史语音嵌入进行池化处理并计算它们的余弦相似度,来得到话语级的声学相似度。将帧级相似度和话语级相似度进行加权求和后,我们得到历史语音嵌入相对于当前话语的语音检索相似度。我们选取语音检索相似度最高的前K个历史上下文作为当前话语的前K个语音检索历史上下文。在文本模态检索中,我们利用嵌入模型计算当前话语假设与历史话语假设之间的句子级语义相似度,并将其作为文本检索相似度。然后,我们选择文本检索相似度最高的前K个历史话语假设作为当前话语的前K个文本检索历史上下文。
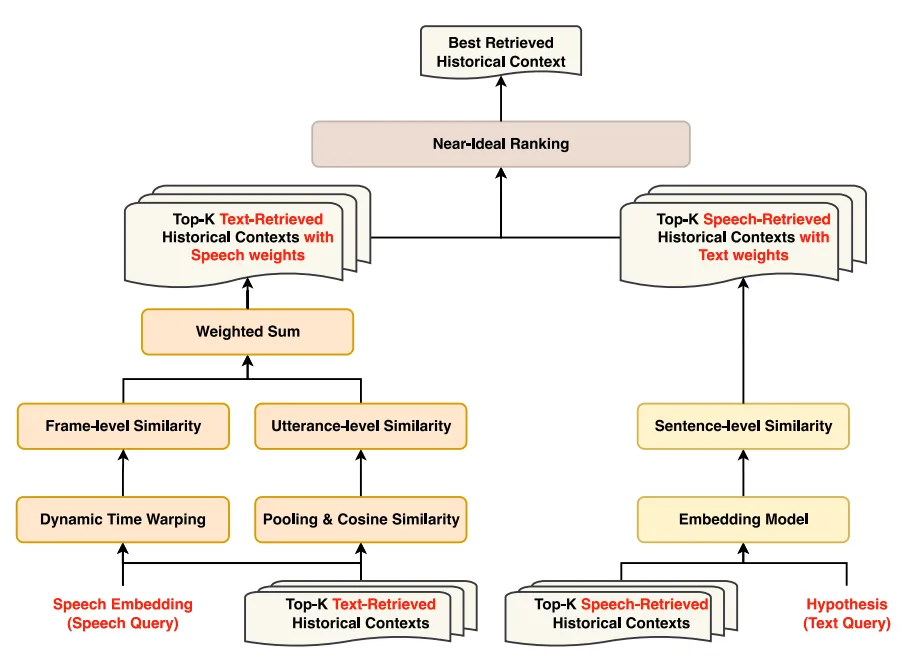
多模态选择
在多模态检索之后,我们观察到,单独或组合使用语音检索或文本检索得到的前K个历史上下文,都会降低ASR性能。然而,当我们从语音检索或文本检索得到的结果中选择最佳历史上下文时,ASR性能会有所提升。因此,我们提出了一个多模态选择模块,用于从语音检索和文本检索得到的前K个历史上下文中确定最佳的历史上下文。这种方法不仅能提升ASR性能,还能缓解因上下文过长而导致的计算成本增加问题。图4展示了多模态选择模块的详细流程。我们首先计算所有检索到的历史上下文的语音检索相似度和文本检索相似度。对于语音检索得到的前K个历史上下文,每个都有语音检索相似度,但没有文本检索相似度。因此,我们需要为每个上下文计算文本检索相似度,最终确保语音检索得到的前K个历史上下文同时具备语音检索相似度和文本检索相似度。同时,我们也会为文本检索得到的前K个历史上下文计算语音检索相似度。在获取所有检索到的历史上下文的语音检索相似度和文本检索相似度之后,面临的挑战是如何结合这两种相似度来确定最佳的检索历史上下文。由于语音检索相似度和文本检索相似度是通过不同方法计算得出的,它们的维度不同,无法通过算法直接转换。此外,选择最佳的检索历史上下文需要同时考虑语音检索相似度和文本检索相似度。因此,直接将这两种相似度相加,然后通过排序选择总和最大的结果,并不是一种合理的方法。为了应对上述挑战,我们提出了一种名为 “近理想排序” 的方法,该方法同时考虑语音和文本检索的相似度,以确定最佳检索到的历史上下文。具体来说,我们对每个检索到的历史上下文都计算其语音和文本相似度,然后虚拟理想最佳上下文,其具有最高的语音和文本相似度,再虚拟一个最差历史上下文,其具有最低的语音和文本相似度。我们选择距离理想的历史上下文最近且距离最差历史上下文最远的作为最终的历史上下文。
自适应上下文解码
在对话LLM-ASR的训练过程中,我们随机决定是否使用最佳检索到的历史上下文。这种随机掩盖最佳检索历史上下文的训练策略能够增强对话LLM-ASR的泛化能力,防止其过度依赖历史上下文而忽视当前话语本身。采用这种策略训练的对话式LLM-ASR能够适应多种解码策略:
Direct decoding:在对话LLM-ASR中,每个话语都独立解码,不依赖任何历史上下文。
MARS decoding:在对话LLM-ASR中,每个话语通过与最佳检索到的历史上下文相结合进行解码,而最佳检索历史上下文是通过多模态检索与选择方法确定的。
Two-pass decoding:在第一遍解码中,通过Direct decoding得到每个话语的初步假设。随后,构建一个新的Database来存储话语及其初步假设。在第二遍解码中,通过MARS decoding从新构建的Database中确定最佳检索历史上下文,从而得到每个话语的最终预测转录结果。
实验
我们在MLC-SLM数据集上进行了实验,该数据集源自最近举办的Interspeech 2025多语言对话语音语言模型挑战赛,包含11种语言:英语、法语、德语、意大利语、葡萄牙语、西班牙语、日语、韩语、俄语、泰语和越南语,总共有约1500小时的对话语音数据,每段录音都是两位说话人围绕随机分配的话题进行的自然流畅的对话。
表1对比了原始Whisper-large-v3、在MLC-SLM数据集上全量微调的Whisper-large-v3、Qwen2-Audio和挑战赛最佳系统TEA-ASLP[5]与本文的MARS方法在每个语言上的字符错误率(CER)或者词错误率(WER)以及平均混合错误率(MER)的结果。我们的方法取得了最佳性能,说明通过检索和选择合适的历史上下文来增强对话ASR的巨大潜力,并且用较少的训练数据就可以实现高识别准确率。
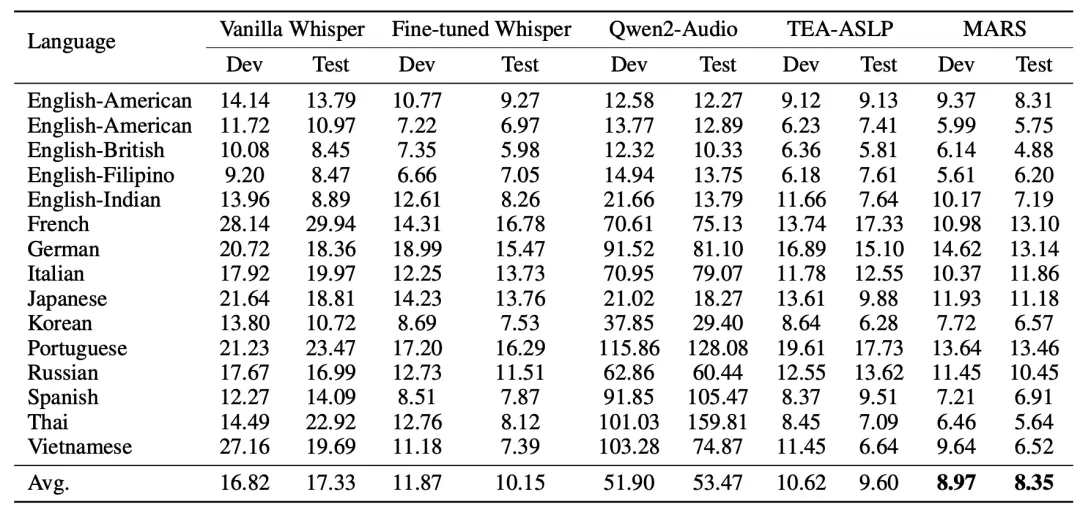
表2展示了MARS与其他利用上下文增强对话式LLM-ASR的方法的对比结果。即便将真实转录文本作为上下文,所带来的益处也十分有限,这表明紧邻的前文话语中仍包含无关和冗余的信息。此外,即便使用真实转录和未来信息,他们通过利用上下文所获得的相对增益也不及MARS。这些结果进一步凸显了MARS在检索和选择最佳历史上下文方面的必要性。
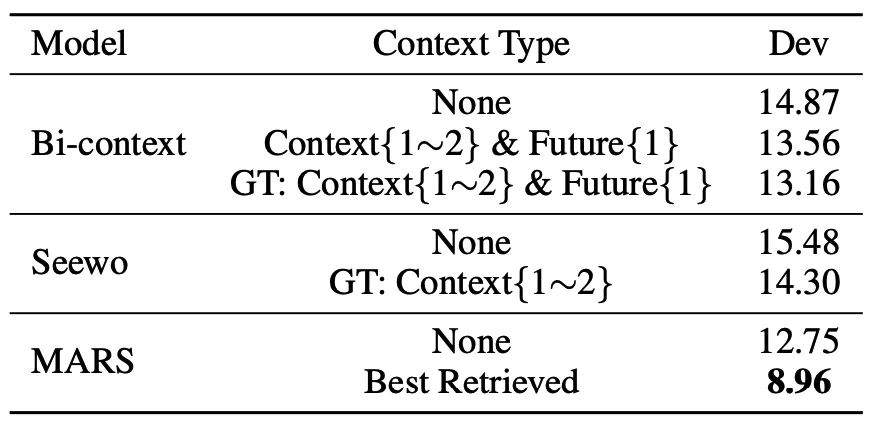
表3中的消融研究展示了MARS各组件的有效性。将当前话语ASR假设融入LLM-ASR中能够提升性能。再融入与当前话语语音或文本检索相似度最高的历史上下文后,ASR性能进一步提升,而且文本检索到的历史上下文优于语音检索到的历史上下文。多模态检索的性能不如语音或文本检索,这是因为我们选择了最相似的语音和文本检索上下文,而这两种历史上下文的冗余信息会干扰ASR。因此,从多模态检索生成的前K个语音检索和文本检索历史上下文中挑选出最佳历史上下文至关重要。在多模态检索后应用多模态选择,特别是采用逼近理想排序方法来选择最佳历史上下文,能够有效提升ASR性能。最后,在训练过程中随机掩盖历史上下文,并利用双遍解码为当前话语的语音识别提供更准确的历史上下文,为MARS带来了最佳结果。
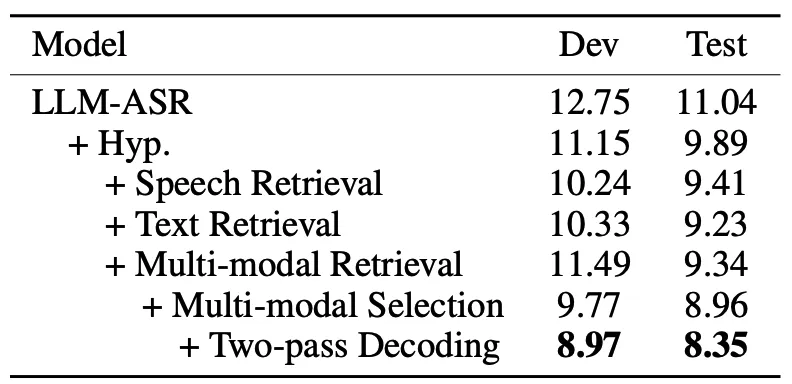
表4中进一步对多模态检索和多模态选择进行了详细的消融实验。在历史上下文数量相同的情况下,使用语音或文本检索历史上下文的效果优于使用固定数量的先前话语历史上下文,这证明了检索的必要性。此外,我们发现随着历史上下文数量的增加,ASR性能显著下降,这表明过多的历史上下文会导致信息冗余,不利于对当前话语的识别。经过多模态检索后,共获得2K条历史上下文。为了充分发挥检索到的历史上下文的潜力,我们需要从中选出最优的一条。与多模态选择相比,简单地将每个检索到的历史上下文的语音和文本检索相似度相加,然后选择总相似度最高的那个,效果更差,这验证了多模态选择的有效性。
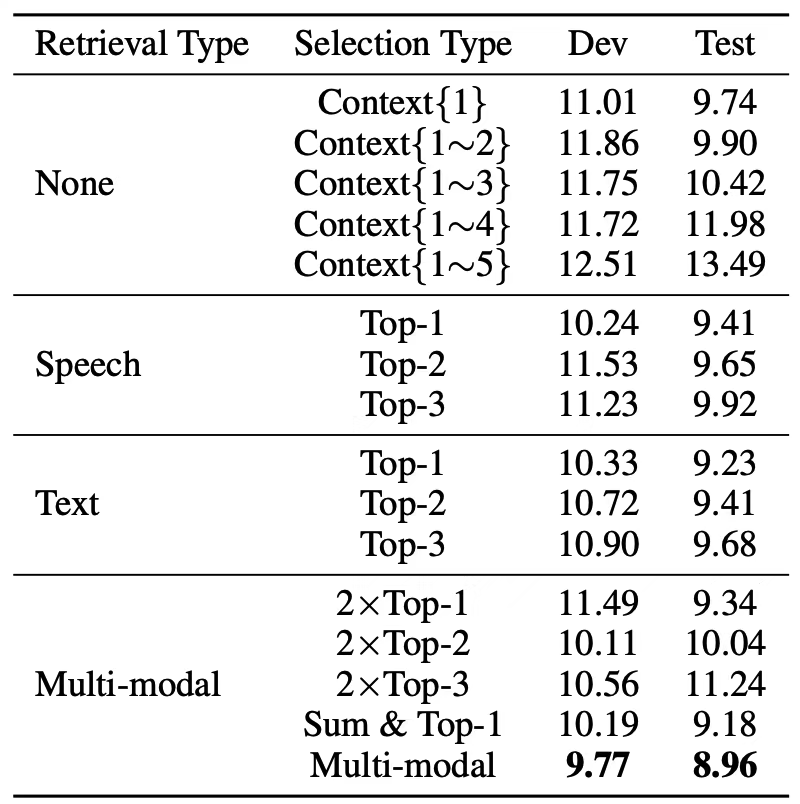
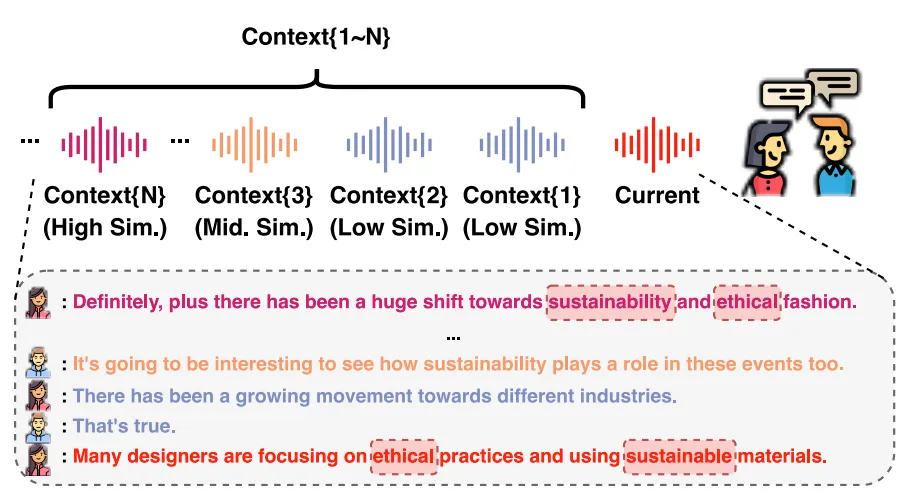
图5展示了MLC-SLM测试数据集中不同类型的历史上下文与当前话语之间的平均语音和文本检索相似度。与检索到的历史上下文相比,前序历史上下文的平均语音和文本检索相似度更低。此外,不同的相似度计算方法导致语音和文本检索相似度在数值上存在显著差异。直接将两者相加来获取最佳历史上下文是不合适的,这凸显了逼近理想排序方法的优势。
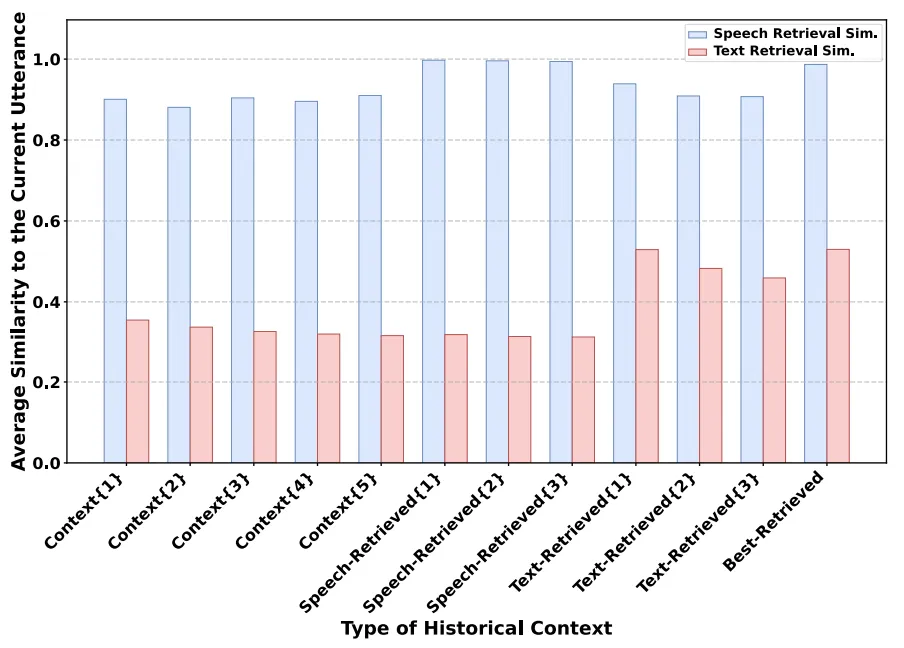
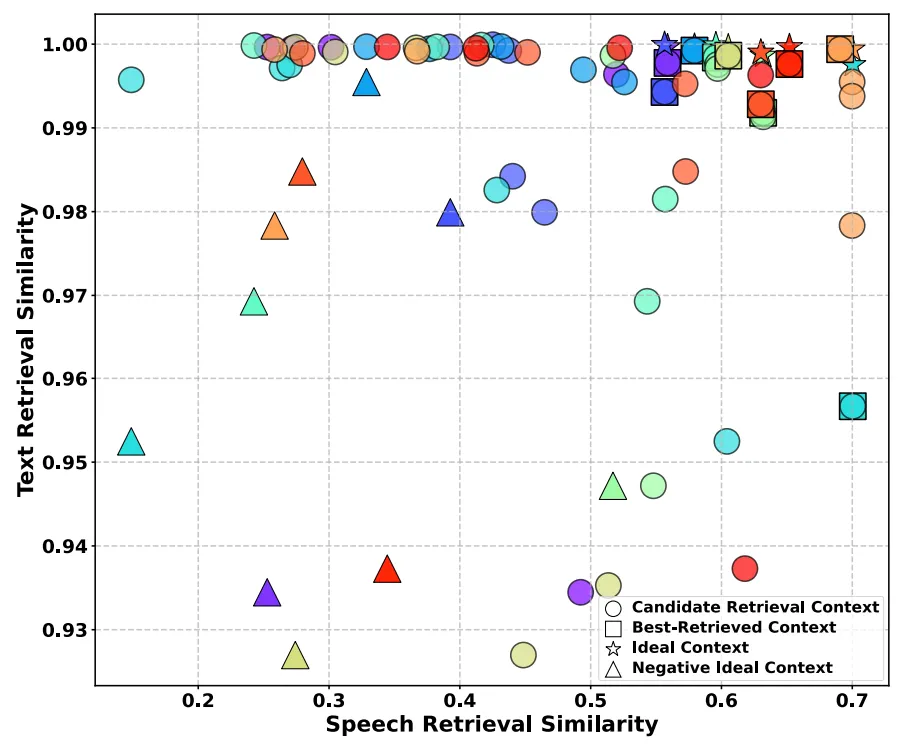
图6可视化了在从MLC-SLM测试数据集中随机选取的10个话语上的逼近理想排序方法。我们观察到,该方法所选的最佳历史上下文,其语音和文本检索相似度与理想假设高度一致,且与负理想假设相去甚远。该方法不仅避免了因使用多个历史上下文导致信息冗余而产生的ASR结果混乱问题,还显著提升了ASR性能并降低了计算成本。
参考文献
[1] Kun Wei, Bei Li, Hang Lv, Quan Lu, Ning Jiang, Lei Xie, “Conversational speech recognition by learning audio-textual cross-modal contextual representation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing.
[2] Mingyu Cui, Jiawen Kang, Jiajun Deng, Xi Yin, Yutao Xie, Xie Chen, Xunying Liu, “Towards Effective and Compact Contextual Representation for Conformer Transducer Speech Recognition Systems,” Interspeech 2023.
[3] Bingshen Mu, Pengcheng Guo, Zhaokai Sun, Shuai Wang, Hexin Liu, Mingchen Shao, Lei Xie, and et al., “Summary on The Multilingual Conversational Speech Language Model Challenge: Datasets, Tasks, Baselines, and Methods,” arXiv:2509.13785.
[4] Salvador Stan, Philip Chan, “Toward accurate dynamic time warping in linear time and space,” Intelligent data analysis.
[5] Hongfei Xue, Kaixun Huang, Zhikai Zhou, Shen Huang, Shidong Shang, “The TEA-ASLP System for Multilingual Conversational Speech Recognition and Speech Diarization in MLC-SLM 2025 Challenge,” Interspeech2025 MLC-SLM Workshop.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。