
NVIDIA 研究人员发布了 PersonaPlex-7B-v1,这是一个全双工语音到语音(Speech-to-Speech)对话模型,旨在实现具有精确角色控制的自然语音交互。
从 ASR→LLM→TTS 到单一全双工模型
传统的语音助手通常采用级联处理方式。自动语音识别 (ASR) 将语音转换为文本,语言模型生成文本回复,文本转语音 (TTS) 再将文本转换回音频。每个阶段都会增加延迟,而且这种处理流程无法处理重叠语音、自然中断或密集的反向信道。
PersonaPlex 用一个单一的 Transformer 模型取代了原有的技术栈,该模型在一个网络中即可完成流式语音理解和语音生成。该模型处理使用神经编解码器编码的连续音频,并自回归地预测文本标记和音频标记。传入的用户音频被增量编码,同时 PersonaPlex 生成自身的语音,从而实现了插话、重叠、快速轮换和上下文相关的语音交互。
PersonaPlex采用双流配置运行。一个流跟踪用户音频,另一个流跟踪智能体的语音和文本。两个流共享相同的模型状态,因此智能体可以在说话的同时持续监听,并在用户打断时调整其响应。此设计直接借鉴了Kyutai的Moshi全双工框架。
混合提示、语音控制和角色控制
PersonaPlex 使用两个提示来定义对话身份。
- 语音提示是一系列音频标记,用于编码声音特征、说话风格和韵律。
- 文本提示描述了角色、背景、组织信息和场景背景。
这些提示共同约束了代理的语言内容和声学行为。此外,系统提示还支持姓名、公司名称、代理姓名和公司信息等字段,预算上限为 200 个令牌。
架构、Helium 主干网和音频路径
PersonaPlex 模型拥有 70 亿个参数,并采用 Moshi 网络架构。一个结合了卷积神经网络 (ConvNet) 和 Transformer 层的 Mimi 语音编码器将波形音频转换为离散的词元。时间 Transformer 和深度 Transformer 处理代表用户音频、代理文本和代理音频的多个通道。一个同样结合了 Transformer 和 ConvNet 层的 Mimi 语音解码器生成输出音频词元。音频的输入和输出均采用 24 kHz 的采样率。
PersonaPlex 基于 Moshi 权重构建,并使用Helium作为底层语言模型骨干。Helium 提供语义理解,并支持在监督式对话场景之外进行泛化。这在“太空紧急情况”示例中体现得尤为明显:即使火星任务中反应堆堆芯故障的情况并非训练集内容的一部分,当提示出现时,PersonaPlex 也能做出连贯的技术推理,并带有恰当的情感语气。
训练数据融合,真实对话与合成角色
训练分为 1 个阶段,采用真实对话和合成对话相结合的方式。
这些真实对话来自 Fisher 英语语料库中的 7303 个通话,总时长约 1217 小时。我们使用 GPT-OSS-120B 对这些对话进行了反向标注,添加了提示信息。提示信息的粒度各不相同,从简单的个人特征提示(例如“你喜欢进行愉快的交谈”)到包含生活经历、地点和偏好等更详细的描述。该语料库提供了自然的对话反馈、语流不畅、停顿和情感模式,这些仅靠文本转语音 (TTS) 很难获得。
合成数据涵盖了助理和客服角色。NVIDIA 团队报告称,合成了 39,322 条助理对话(约 410 小时)和 105,410 条客服对话(约 1,840 小时)。Qwen3-32B 和 GPT-OSS-120B 生成文本转录,Chatterbox TTS 将其转换为语音。对于助理交互,文本提示固定为“您是一位睿智友好的老师。请以清晰易懂的方式回答问题或提供建议。”对于客服场景,提示信息包含组织机构、角色类型、客服人员姓名以及结构化业务规则,例如定价、工作时间和限制条件。
这种设计使 PersonaPlex 能够将主要来自 Fisher 的自然对话行为与主要来自合成场景的任务遵守和角色条件分开。
在 FullDuplexBench 和 ServiceDuplexBench 上进行评估
PersonaPlex 在 FullDuplexBench(全双工语音对话模型的基准测试)和名为 ServiceDuplexBench 的新扩展(用于客户服务场景)上进行了评估。
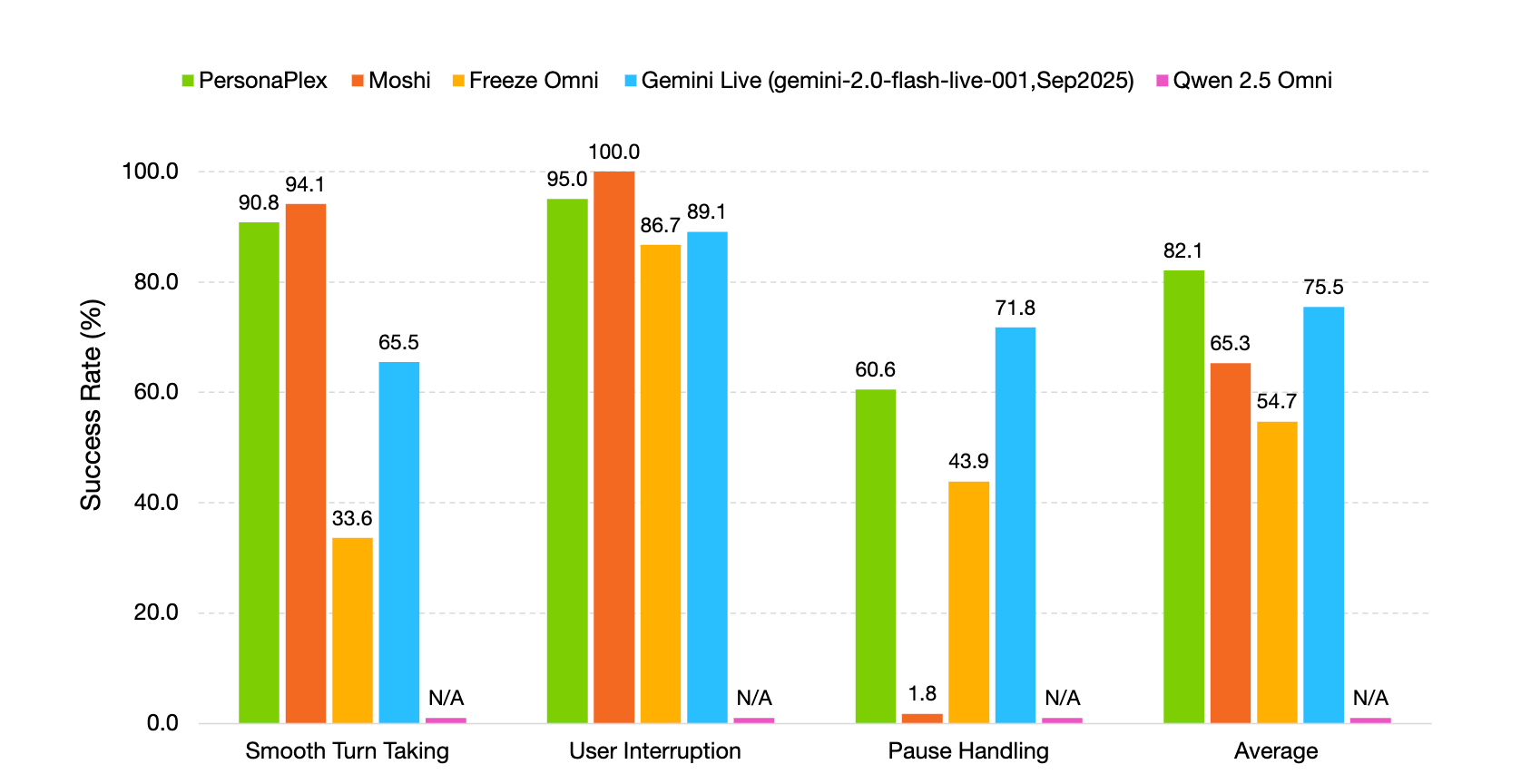
FullDuplexBench 使用接管率 (Takeover Rate) 和延迟指标来衡量对话动态,其任务包括流畅的轮流发言、用户打断处理、停顿处理和反向沟通。GPT-4o 作为 LLM 评判器,用于评估问答类别中的回复质量。PersonaPlex 在流畅轮流发言方面达到了 0.908 的接管率 (TOR),延迟为 0.170 秒;在用户打断处理方面达到了 0.950 的接管率 (TOR),延迟为 0.240 秒。在用户打断子集中,语音提示和输出之间的说话人相似度使用 WavLM TDNN 嵌入,达到了 0.650。
在助理和客户服务角色中,PersonaPlex 在对话动态、响应延迟、中断延迟和任务遵守方面都优于许多其他开源和封闭系统。

要点总结
- PersonaPlex-7B-v1 是 NVIDIA 推出的 7B 参数全双工语音对语音对话模型,基于 Moshi 架构,采用 Helium 语言模型骨干,代码采用 MIT 许可,权重采用 NVIDIA 开放模型许可。
- 该模型采用双流 Transformer,配备 24 kHz 的 Mimi 语音编码器和解码器,将连续音频编码为离散标记,并同时生成文本和音频标记,从而实现插话、重叠、快速轮换和自然的反向通道。
- Persona 控制通过混合提示进行处理,由音频标记组成的语音提示设置音色和风格,文本提示和最多 200 个标记的系统提示定义角色、业务上下文和约束,并提供现成的语音嵌入,例如 NATF 和 NATM 系列。
- 训练使用了 7,303 个 Fisher 对话(约 1,217 小时),这些对话使用 GPT-OSS-120B 进行标注;此外还使用了合成助手和客户服务对话(分别约 410 小时和 1,840 小时),这些对话分别使用 Qwen3-32B 和 GPT-OSS-120B 生成,并使用 Chatterbox TTS 进行渲染,从而将对话的自然性与任务的执行情况分开。
- 在 FullDuplexBench 和 ServiceDuplexBench 测试中,PersonaPlex 实现了 0.908 的平滑轮流接管率和 0.950 的用户中断接管率,延迟低于一秒,任务执行率得到提高。
参考资料:
https://research.nvidia.com/labs/adlr/personaplex/
https://github.com/NVIDIA/personaplex
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/64330.html