
理解音频一直是多模态领域中落后于视觉的前沿阵地。虽然图像语言模型已经迅速扩展到实际应用,但构建能够稳健地推理语音、环境声音和音乐(尤其是长音频)的开放模型仍然非常困难。NVIDIA 和马里兰大学的研究人员正着手弥合这一差距。
研究团队发布了Audio Flamingo Next (AF-Next),它是 Audio Flamingo 系列中最强大的模型,也是一个完全开放的大型音频语言模型 (LALM),该模型使用互联网规模的音频数据进行训练。
Audio Flamingo Next (AF-Next)提供三种针对不同使用场景的专用版本。该版本包括用于一般问答的AF-Next-Instruct 、用于高级多步骤推理的AF-Next-Think以及用于详细音频字幕的AF-Next-Captioner。
什么是大型音频语言模型(LALM)?
大型音频语言模型 (LALM)将音频编码器与仅解码器的语言模型相结合,可以直接对音频输入进行问答、字幕生成、转录和推理。你可以将其视为 LLaVA 或 GPT-4V 等视觉语言模型的音频版本,但它旨在同时处理语音、环境音和音乐,所有这些都集成在一个统一的模型中。


架构:四个组件协同工作
AF-Next 由四个主要组件构成:首先是AF-Whisper 音频编码器,这是一个基于 Whisper 的定制编码器,并在一个更大、更多样化的语料库上进行了预训练,该语料库包含多语言语音和多说话人自动语音识别 (ASR) 数据。给定一个音频输入,该模型将其重采样为 16 kHz 单声道,并使用 25 毫秒的窗口和 10 毫秒的步长将波形转换为 128 通道的对数梅尔频谱图。频谱图以不重叠的 30 秒片段的形式通过 AF-Whisper 进行处理,输出频率为 50 Hz 的特征,之后应用一个步长为 2 的池化层。隐藏层维度为 1280。
其次是音频适配器,这是一个两层多层感知器(MLP),它将AF-Whisper的音频表示映射到语言模型的嵌入空间。
第三部分是LLM骨干网络:Qwen-2.5-7B,这是一个仅包含解码器的因果模型,具有70亿个参数、36个Transformer层和16个注意力头,通过额外的长上下文训练,将上下文长度从3.2万个词元扩展到12.8万个词元。
一个微妙但重要的架构细节是旋转时间嵌入(RoTE)。Transformer 中的标准位置编码通过令牌的离散序列位置 i 来索引该令牌。RoTE 取代了这一机制:与标准的 RoPE 旋转角度 θ ← −i · 2π 不同,RoTE 使用 θ ← −τi · 2π,其中 τi 是每个令牌的绝对时间戳。对于以固定 40 毫秒步长生成的音频令牌,在输入 RoTE 模块前会对其离散时间位置进行插值。这产生了基于实际时间而非序列顺序的位置表示,这一核心设计选择使模型能够进行时间推理,特别是在处理长音频时。最后,流式 TTS 模块实现了语音到语音的交互。
时间音频思维链:关键推理方法
思维链(CoT)提示技术已显著提升了文本和视觉模型的推理能力,但以往的音频CoT研究成果提升有限,原因在于训练数据集仅限于包含简单问题的短音频片段。AF-Next通过时间音频思维链解决了这一问题。该技术在生成答案之前,会将每个中间推理步骤明确锚定到音频中的时间戳,从而鼓励模型忠实地聚合证据,并减少长时间录音中的幻觉。
为了训练这种能力,研究团队创建了AF-Think-Time数据集,该数据集包含从各种具有挑战性的音频源(包括预告片、电影回顾、悬疑故事和长篇多人对话)中精心挑选的问答思维链三元组。AF-Think-Time 包含约 4.3 万个训练样本,平均每个思维链包含 446.3 个单词。
大规模训练:100万小时,四个阶段
最终的训练数据集包含约 1.08 亿个样本和约 100 万小时的音频,这些数据来源于现有的公开数据集以及从开放互联网收集并经过人工标注的原始音频。新增的数据类别包括:超过 20 万个时长 5 至 30 分钟的长视频,用于长篇字幕和质量保证;涵盖说话人识别、中断识别和目标说话人自动语音识别的多说话人语音理解数据;约 100 万个用于跨多个同步音频输入的多音频推理样本;以及约 38.6 万个安全和指令遵循样本。
训练遵循四阶段课程,每个阶段的数据混合和上下文长度各不相同。
- 预训练分为两个子阶段:第一阶段仅训练音频适配器,同时保持 AF-Whisper 和 LLM 不变(音频最长 30 秒,上下文 8K 个标记);第二阶段在保持 LLM 不变的情况下,进一步微调音频编码器(音频最长 1 分钟,上下文 8K 个标记)。
- 中期训练也分为两个子阶段:第一阶段对整个模型进行全面微调,添加 AudioSkills-XL 和新整理的数据(音频最长 10 分钟,上下文 24K 个标记);第二阶段引入长音频字幕和质量保证,将第一阶段的混合数据下采样至原始混合权重的一半,同时将上下文扩展到 128K 个标记,音频扩展到 30 分钟。中期训练的模型专门发布为AF-Next-Captioner。
- 后训练阶段应用基于 GRPO 的强化学习,重点关注多轮聊天、安全、指令遵循和选定的特定技能数据集,生成AF-Next-Instruct 模型。
- 最后,CoT 训练从 AF-Next-Instruct 模型开始,对 AF-Think-Time 模型应用 SFT,然后使用后训练阶段的数据混合进行 GRPO 训练,生成AF-Next-Think 模型。
该研究团队的一项显著贡献是混合序列并行性,它使得在长音频上进行 128K 上下文训练成为可能。如果没有这项技术,音频标记的扩展将远远超出标准上下文窗口,而自注意力机制的二次方内存开销也将变得不可行。该解决方案结合了 Ulysses 注意力机制和 Ring 注意力机制。Ulysses 注意力机制利用全对全集合在具有高带宽互连的节点内分配序列和头部维度,而 Ring 注意力机制则通过点对点传输在节点间循环键值块。Ulysses 能够高效地处理节点内通信;Ring 则能够跨节点扩展。
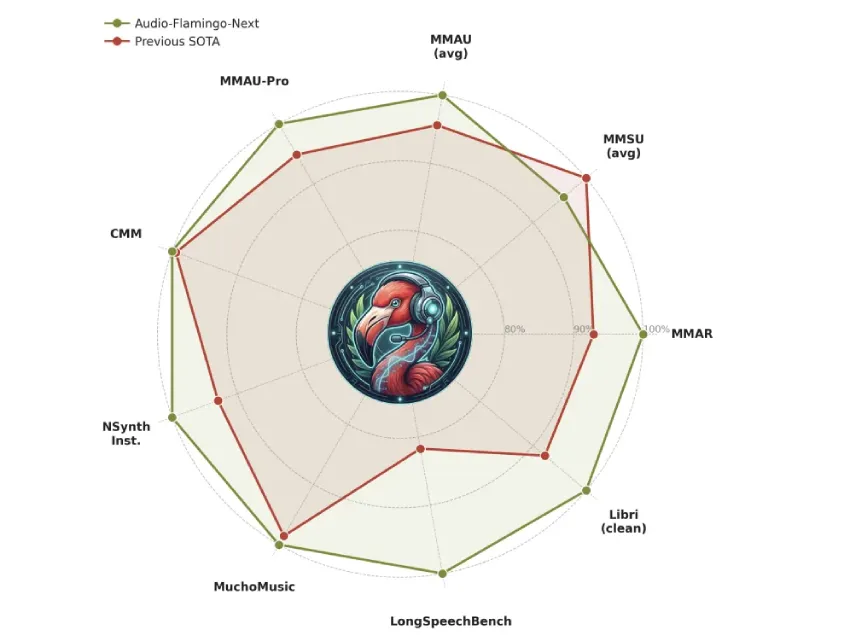
基准测试结果:各项指标均表现强劲
在应用最广泛的音频推理基准测试 MMAU-v05.15.25 中,AF-Next-Instruct 的平均准确率达到 74.20%,高于 Audio Flamingo 3 的 72.42;AF-Next-Think 达到 75.01;AF-Next-Captioner 则更进一步,达到 75.76——在所有三个子类别(声音 (79.87)、音乐 (75.3) 和语音 (72.13))中均有所提升。在更具挑战性的 MMAU-Pro 基准测试中,AF-Next-Think (58.7) 也超越了闭源的 Gemini-2.5-Pro (57.4)。
音乐理解能力提升尤为显著。在 Medley-Solos-DB 乐器识别测试中,AF-Next 的得分达到 92.13,而 Audio Flamingo 2 为 85.80。在 SongCaps 音乐字幕生成测试中,GPT5 的覆盖率和正确率分别从 AF3 的 6.7 和 6.2 跃升至 8.8 和 8.9。
AF-Next 在长音频理解方面表现最为突出。在 LongAudioBench 测试中,AF-Next-Instruct 的得分为 73.9,超过了 Audio Flamingo 3 (68.6) 和闭源的 Gemini 2.5 Pro (60.4)。在包含语音的测试版本 (+Speech) 中,AF-Next 的得分达到 81.2,而 Gemini 2.5 Pro 的得分为 66.2。在自动语音识别 (ASR) 方面,AF-Next-Instruct 在 LibriSpeech test-clean 测试中的词错误率仅为 1.54%,在其他测试中的词错误率也仅为 2.76,创下了语言辅助语言学习 (LALM) 的新低。在 VoiceBench 测试中,AF-Next-Instruct 在 AlpacaEval (4.43)、CommonEval (3.96) 和 OpenBookQA (80.9) 测试中均取得了最高分,其中在 OpenBookQA 测试中比 Audio Flamingo 3 高出 14 分以上。在 CoVoST2 语音翻译中,AF-Next 在阿拉伯语 EN→X 翻译方面比 Phi-4-mm 表现出特别显著的 12 个百分点的改进(21.9 对 9.9)。

要点总结
以下是5个关键要点:
- 互联网规模的完全开放音频语言模型:AF-Next 被认为是第一个将音频理解扩展到互联网规模数据的 LALM,大约 1.08 亿个样本和 100 万小时的音频。
- 时间音频思维链解决了长音频推理难题:与以往的思维链方法不同,AF-Next 在得出答案之前,会将每个中间推理步骤明确地锚定到音频中的时间戳。这使得该模型在处理长达 30 分钟的录音时,能够更准确地还原音频内容并提高其可解释性,而此前的模型大多回避了这个问题。
- 三种针对不同使用场景的专用变体:该版本包括用于一般问答的 AF-Next-Instruct、用于高级多步骤推理的 AF-Next-Think 和用于详细音频字幕的 AF-Next-Captioner,允许从业人员根据他们的任务选择合适的模型,而不是使用一刀切的检查点。
- 尽管体积更小,AF-Next-Instruct 在 LongAudioBench 测试中以 73.9 分的成绩超越了闭源的 Gemini 2.5 Pro (60.4) 和 Audio Flamingo 3 (68.6)。在更具挑战性的语音增强版测试中,AF-Next 的得分更是高达 81.2 分,远超 Gemini 2.5 Pro 的 66.2 分。
参考资料
- 论文地址:https://arxiv.org/pdf/2604.10905
- 项目页面:https://huggingface.co/spaces/nvidia/audio-flamingo-next
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/66173.html