
中国科学院计算技术研究所的研究人员推出了LLaMA-Omni2,这是一系列支持语音的大型语言模型(SpeechLM),现已在Hugging Face上可用。这项研究引入了一个模块化框架,通过将语音感知和合成与语言理解相结合,实现了实时口语对话。与早期的级联系统不同,LLaMA-Omni2采用端到端流水线运行,同时保留了模块化的可解释性和较低的训练成本。
LLaMA-Omni2 架构概述
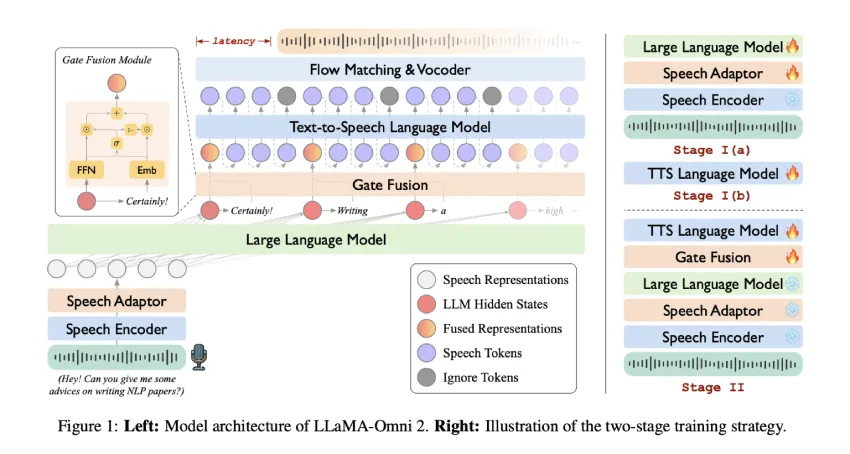
LLaMA-Omni2 包含 0.5 亿到 140 亿个参数的模型,每个模型都构建于 Qwen2.5-Instruct 系列之上。该架构包括:
- 语音编码器:利用 Whisper-large-v3 将输入语音转换为标记级声学表示。
- 语音适配器:使用下采样层和前馈网络处理编码器输出,以与语言模型的输入空间对齐。
- 核心LLM:Qwen2.5模型作为主要推理引擎。
- 流式 TTS 解码器:使用自回归转换器将 LLM 输出转换为语音标记,然后通过受 CosyVoice2 启发的因果流匹配模型生成梅尔频谱图。
在语音合成之前,一种门控机制将 LLM 隐藏状态与文本嵌入相融合,从而提高了生成音频的上下文保真度。

具有读写调度的流式生成
该模型采用读写策略,以促进流式输出。具体而言,RLLM 生成的每个 tokenW都会生成相应的语音 token。这实现了文本和语音的同步生成,从而在不影响流畅度的情况下最大限度地减少延迟。
实证结果表明,设置 R = 3 和 W = 10 可以在延迟(~583 毫秒)、对齐(ASR-WER:3.26)和感知质量(UTMOS:4.19)之间实现良好的权衡。
训练方法
尽管 LLaMA-Omni2 的性能很有竞争力,但它是在一个相对紧凑的语料库,200K 多轮语音到语音对话样本上进行训练的。这些样本由指令跟读文本数据集(Alpaca、UltraChat)合成,使用 FishSpeech 和 CosyVoice2 模型生成不同的输入语音和一致的输出语音。
训练分两个阶段进行:
- 第一阶段:独立优化语音转文本、文本转语音模块。
- 第二阶段:微调语音到语音生成路径,包括门控和自回归解码组件。
基准测试结果
使用语音转文本 (S2T) 和语音转语音 (S2S) 模式对模型进行口头问答和语音指令任务评估。
| 模型 | Llama Q (S2S) | Web Q(S2S) | GPT-4o Score | ASR-WER | 延迟(毫秒) |
|---|---|---|---|---|---|
| GLM-4-语音 (9B) | 50.7 | 15.9 | 4.09 | 3.48 | 1562.8 |
| LLaMA-Omni (8B) | 49.0 | 23.7 | 3.52 | 3.67 | 346.7 |
| LLaMA-Omni2-7B | 60.7 | 31.3 | 4.15 | 3.26 | 582.9 |
性能与模型大小一致。值得注意的是,LLaMA-Omni2-14B 在所有任务中的表现均优于基线模型,即使训练数据量远少于 GLM-4-Voice 等原生 SpeechLM 模型。
成分分析
- 门控融合模块:去除门控机制会增加 ASR-WER 并降低语音质量,从而确认了其在对齐文本和上下文信号中的作用。
- TTS 预训练:使用 Qwen2.5 初始化 TTS 模型,并在流式设置中进行微调,可获得最佳性能。从头开始训练无法有效收敛。
- 读/写策略:调整读/写比例会影响延迟和质量。增大读/写比例可以提高 UTMOS,但会以响应延迟为代价。
此外,研究表明,多轮对话数据在训练语音交互能力方面比单轮数据更有效,并且性能在 200K 个样本左右达到稳定状态。
结论
LLaMA-Omni2 证明了,无需在海量语音语料库上进行大量预训练,即可利用 LLM 实现高质量、低延迟的语音交互。该系统将模块化架构与自回归流式合成相结合,为实时语音应用提供了一条切实可行的途径。
资料
- 论文地址:https://arxiv.org/abs/2505.02625
- GitHub:https://github.com/ictnlp/LLaMA-Omni2
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/57886.html