
理解音频片段的内容其实是一个难度极高的问题。转录语音只是其中一部分。一个真正强大的系统还需要识别说话者是谁,检测其情绪状态,解读背景声音,分析音乐内容,并回答诸如“说话者在2分钟时说了什么?”之类的时间相关问题。要实现所有这些功能,需要将多个专用系统整合在一起。
OpenMOSS 团队、MOSI.AI 和上海创新研究院发布了MOSS-Audio:一个开源音频理解模型,旨在将所有这些功能统一到一个基础模型中。
MOSS-Audio 的实际功能
MOSS-Audio 支持语音理解、环境音理解、音乐理解、音频字幕、时间感知问答以及基于真实音频的复杂推理。其功能集分为几个不同的领域。“语音与内容理解”能够准确识别和转录语音内容,支持词级和句级时间戳对齐。“说话人、情感与事件分析”能够识别说话人特征,基于音调、音色和上下文分析情感状态,并检测音频中的关键声学事件。“场景与声音线索提取”能够从背景音、环境噪声和非语音信号中提取有意义的信号,从而推断场景上下文和氛围。“音乐理解”能够分析音乐风格、情感发展和乐器配置。“音频问答与摘要”能够处理语音、播客、会议和访谈等各种音频内容的问答和摘要。最后,“复杂推理”能够基于链式思维训练和强化学习,对音频内容进行多跳推理。
实际上,单个 MOSS-Audio 型号即可完成上述所有操作,而无需在不同的专用系统之间切换。
四种变体
该团队在发布时推出了四个变体:MOSS-Audio-4B-Instruct、MOSS-Audio-4B-Thinking、MOSS-Audio-8B-Instruct和MOSS-Audio-8B-Thinking。如果您正在决定使用哪个模型,了解命名规则非常重要。“指令”变体针对直接指令执行进行了优化,因此非常适合需要可预测、结构化输出的生产流水线。“思考”变体提供了更强大的思维链推理能力,更适合需要多跳推理的任务。4B 模型使用Qwen3-4B作为 LLM 骨干,8B 模型使用Qwen3-8B,因此模型的总参数量分别约为 46 亿和 86 亿。
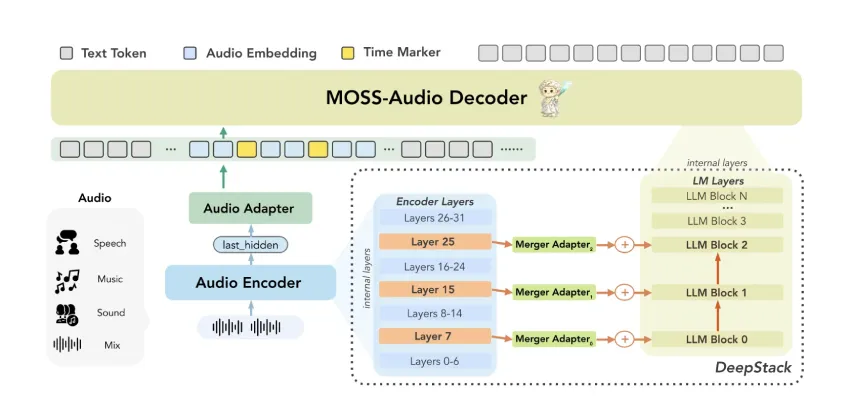

架构:三个组件协同运作
MOSS-Audio 采用模块化设计,包含三个组件:音频编码器、模态适配器和大型语言模型。原始音频首先由MOSS-Audio-Encoder编码成12.5 Hz的连续时间表示。然后,这些表示通过适配器投影到语言模型的嵌入空间,最终由 LLM 用于自回归文本生成。
研究团队没有采用现成的音频前端,而是从零开始训练编码器。他们的理由是:专用编码器能够提供更稳健的语音表示、更精确的时间对齐以及更好的跨声学域扩展性。
MOSS-Audio 内部的两项架构创新值得详细了解。
DeepStack 跨层特征注入:音频模型的一个常见缺陷是,仅依赖编码器的顶层特征往往会丢失底层声学信息,例如韵律、瞬态事件和局部时频结构。MOSS-Audio 通过一个受DeepStack启发的跨层注入模块解决了这个问题,该模块位于编码器和语言模型之间:除了编码器的最终层输出之外,它还会选择来自更早层和中间层的特征,并将它们独立投影并注入到语言模型的早期层中。这保留了从底层声学细节到高层语义抽象的多粒度信息,帮助模型保留单个高层表示无法完全捕捉的节奏、音色、瞬态和背景结构。
时间感知表示:时间是音频中一个至关重要的维度,而文本模型本身并不擅长处理时间信息。MOSS-Audio 通过在预训练期间插入时间标记来解决这个问题:在音频帧表示之间以固定的时间间隔插入显式的时间标记,以指示时间位置。这使得模型能够在统一的文本生成框架内学习“事件发生的时间”,从而自然地支持时间戳自动语音识别 (ASR)、事件定位、基于时间的质量保证 (QA) 和长音频回溯,而无需单独的定位组件或后处理流程。
基准性能
数据表现强劲。在通用音频理解方面, MOSS-Audio-8B-Thinking在四个基准测试中平均准确率达到 71.08% —— MMAU 为 77.33%,MMAU-Pro 为 64.92%,MMAR 为 66.53%,MMSU 为 75.52%,优于大多数开源模型。这其中包括规模更大的模型:Step-Audio-R1(33B)得分为 70.67%,Qwen3-Omni-30B-A3B-Instruct(30B)得分为 67.91%。作为对比,Kimi-Audio(7B)在相同基准测试中的平均得分为 61.14%,MiMo-Audio-7B 为 62.97%。4B Thinking 变体得分为 68.37%,这意味着采用思维导图训练的小型模型击败了所有规模更大的开源指令模型竞争对手。
在语音字幕方面,采用 LLM 作为评判员的方法,从性别、年龄、口音、音调、音量、速度、质感、清晰度、流畅度、情感、语气、个性和摘要等 13 个细粒度维度进行评估,MOSS-Audio-Instruct 变体在 13 个维度中的 11 个维度上领先,其中 MOSS-Audio-8B-Instruct 获得了3.7252的最佳总体平均分。
在涵盖 12 个评估维度(包括健康状况、语码转换、方言、唱歌和非语音场景)的自动语音识别 (ASR)中,MOSS-Audio-8B-Instruct 在所有测试模型中实现了最低的总体 CER(字符错误率)11.30。

要点总结
- 单一模型,完整音频堆栈:MOSS-Audio 将语音转录、说话人和情感分析、环境声音理解、音乐分析、音频字幕、时间感知质量保证和复杂推理统一到一个开源模型中,无需将多个专用系统串联在一起。
- 两项架构创新推动性能提升:DeepStack 跨层特征注入通过将中间编码器层的特征直接注入 LLM 的早期层来保留多粒度声学信息,而预训练期间的时间标记插入则使模型对基于时间戳的任务具有明确的时间感知能力。
- 高效规模下的最佳基准测试结果:MOSS-Audio-8B-Thinking 在一般音频理解基准测试中平均准确率达到 71.08,优于所有开源模型,包括 30B+ 系统,而 4B Thinking 变体本身就击败了所有更大的开源仅指令竞争对手。
- 时间戳 ASR 准确率领先:MOSS-Audio-8B-Instruct 在 AISHELL-1 上的 AAS 得分为 35.77,在 LibriSpeech 上的 AAS 得分为 131.61,在同一基准测试中显著优于 Qwen3-Omni-30B-A3B-Instruct (833.66) 和闭源 Gemini-3.1-Pro (708.24)。
参考资料:
https://huggingface.co/collections/OpenMOSS-Team/moss-audio
https://github.com/OpenMOSS/MOSS-Audio
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/66462.html