
视频内容正越来越多地被专门或主要用于机器分析,典型应用场景包括监控摄像、自动驾驶、工业检测及无人机航拍等。H.264 与 HEVC 等传统编解码标准以人类视觉感知为优化目标,而非机器视觉任务,这一局限性为面向 AI 工作流的新型压缩方案提供了发展空间。目前,三项新兴标准从不同维度应对上述挑战:MPEG的面向机器的视频编码(VCM)、MPEG的面向机器的特征编码(FCM),以及V-Nova的LCEVC。
题目:Three Paths to Compression for Machine Vision: VCM, FCM, and the V-Nova Wild Card
作者:Jan Ozer
原文链接:https://streaminglearningcenter.com/articles/three-paths-to-compression-for-machine-vision-vcm-fcm-and-the-v-nova-wild-card.html
内容整理:梁盈
面向机器的视频编码(VCM)
面向机器的视频编码(Video Coding for Machines,VCM)目前正处于 MPEG-AI 路线图的最终投票阶段,即将成为国际标准(ISO/IEC 23888-2)。在技术层面,VCM 保留了像素域的处理方式,但将优化目标转向机器视觉任务。与追求人眼视觉效果不同,VCM 致力于保留有助于计算机视觉模型执行检测、跟踪与分类等任务的信息。在实践中,这意味着通过感兴趣区域编码等技术,将更多码率分配给对模型任务影响较大的目标区域,而对背景等低影响区域则适当降低码率分配。
图 1 展示了 VCM 的编码机制:对图像特征(边缘提取、结构编码与色彩编码)进行面向机器任务的优化编码,同时生成可解码的码流。解码后的输出同时支持机器视觉任务(如人脸关键点检测)与人工视觉审查,体现了 VCM 的双用途架构设计。然而需要指出的是,尽管像素信息仍可供人工查看或审计,经过深度优化的 VCM 码流往往存在明显的失真、块效应等视觉质量问题。


面向机器的特征编码(FCM)
面向机器的特征编码(Feature Coding for Machines,FCM,ISO/IEC 23888-4)是 MPEG-AI 路线图上更为前沿的技术方向,目前处于工作草案阶段。与 VCM 不同,FCM 不传输压缩像素,而是传输由神经网络提取的压缩特征,使接收端直接获得机器可用的数据,而非可视化图像。因此,FCM 从设计之初便定位为纯机器处理方案:在无需人工监看的场景下具有极高效率,但不适用于同时需要提供常规视频输出的场合。
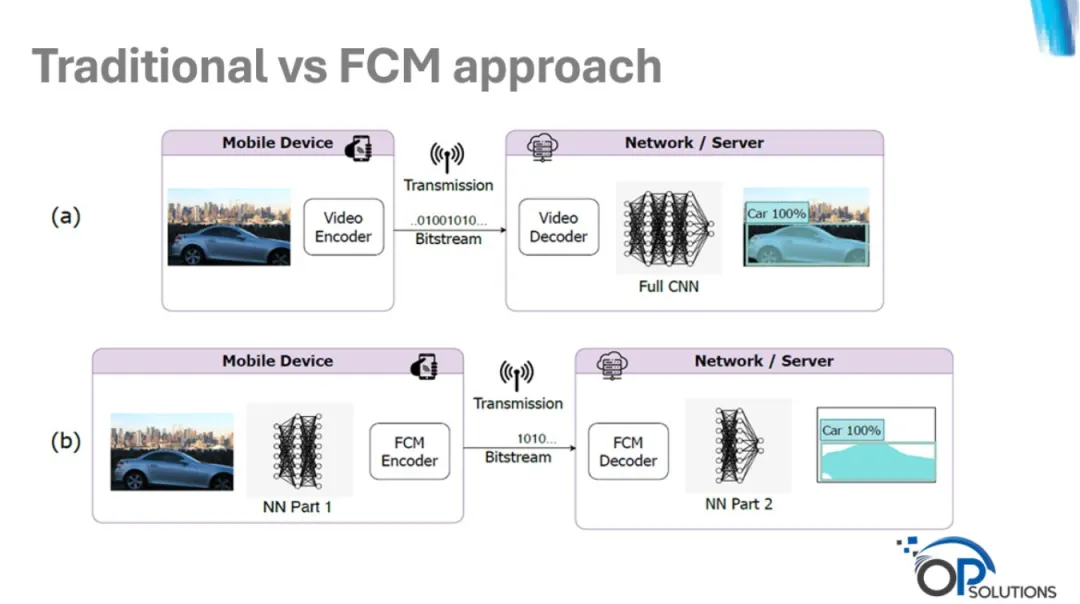
图 2 对比了传统视频处理流程与 FCM 方案的差异。在传统流程 (a) 中,移动设备对原始视频进行编码并传输压缩码流,服务器解码还原像素后再运行完整的CNN模型完成目标检测(置信度 100% 识别车辆)。在 FCM 流程 (b) 中,移动设备运行神经网络前半部分 (NN Part 1) 提取中间特征,经 FCM 编码器压缩后传输。服务器接收压缩特征码流并解码,再运行神经网络后半部分 (NN Part 2) 完成检测任务。通过直接传输神经网络特征而非像素数据,FCM 完全省去了像素解码步骤,从而大幅降低了传输码率。
LCEVC:面向机器的基础层与面向人类的增强层
V-Nova 的 LCEVC 采用了一种截然不同的架构设计。它采用分层结构,基础层由 H.264、HEVC或AV1 等传统编解码器生成低分辨率视频,增强层则用于补充细节信息。若播放设备不支持 LCEVC 解码,仅基础层以低分辨率播放;若支持 LCEVC 解码,则可还原全分辨率视频。该架构使 AI 系统可直接处理低分辨率基础层,同时保留供人工查看的完整码流,从而实现单一编码资产同时服务于机器分析与人工视觉的双重需求。
图 3 展示了 LCEVC 的分层编码结构。编码器将 1080p 输入分解为两个组成部分:包含可解码场景内容的低分辨率基础层(540p),以及存储重建全质量视频所需残差信息的增强层。AI系统可仅解码基础层完成推理任务,避免全分辨率解码带来的额外计算开销;人工用户则可同时解码两层,重建原始 1080p 输出。

值得注意的是,AI 功能使用低分辨率基础层并不构成性能瓶颈。大多数 AI 视觉模型的处理分辨率远低于人工视觉所需的视频分辨率。以主流目标检测模型 YOLO 为例,其典型输入分辨率仅为 640×640 像素或更低;ResNet 等图像分类网络通常采用 224×224 像素输入。受图像尺寸与计算量呈平方级关系的制约,即便是先进模型也鲜少超过 1024×1024 的输入分辨率。
LCEVC 的双层架构使其有别于上述两种 MPEG 方案。VCM 本质上仍是面向机器优化的像素域编码,FCM 则专注于机器端的特征传输,而 LCEVC 定位为连接两者的实用化桥梁方案。V-Nova 的核心主张在于:许多实际部署场景并不希望在 AI 专用码流与人工视觉码流之间二选一,而是希望通过统一的工作流同时满足两类需求。
LCEVC性能评测
V-Nova 亦以公开测试数据支撑上述主张。在与英特尔联合开展的评测中,采用超高清交通监控视频、英特尔深度学习流媒体框架及 MobileNet SSD 模型,V-Nova 报告称:仅解码 LCEVC 基础层可将 CPU 端解码与分析的综合耗时降低 30% 至 50%,集成 GPU 的推理吞吐量提升约 3 倍,同时检测精度基本保持不变。上述数据来源于 V-Nova 官方公告,但至少为其“AI 就绪”的技术主张提供了具体的量化依据。
相较于 FCM,上述性能提升较为有限。FCM 并非对像素进行编码,而是压缩神经网络提取的中间特征图,仅传输推理所需的任务相关数据。在标准化测试中,FCM 相较于 H.264 实现了 90% 的码率压缩,相较于 VVC 实现了 67% 的码率压缩,同时保持等效的目标检测精度。这意味着在机器视觉任务中,FCM 仅需 H.264 约 10%、VVC 约 33% 的传输带宽。
然而,FCM 架构要求通信两端均部署兼容的 AI 模型,且所生成的码流无法解码为可视图像,压缩特征不具备图像可读性。LCEVC 在码率压缩效率上相对保守,但保持了与现有编解码基础设施的兼容性,并支持人机共用同一码流的双用途场景,代价是在纯机器视觉工作流中压缩效率显著低于 FCM。
总结
综合来看,当前技术格局可概括如下:VCM 保留像素域处理,但针对机器任务进行优化;FCM 跳过像素传输,直接传递特征数据;LCEVC 在保持视频可视性的同时,允许机器基于低分辨率层进行处理。三种方案共同立足于同一判断:视频压缩的首要服务对象,正在从人类观看者向机器系统转变。
市场最终选择哪种折中方案,仍是一个悬而未决的问题。若工作流为纯机器处理,FCM 逻辑最为清晰,其大幅度的带宽节省足以证明基础设施投入的合理性。若优先考虑与现有视频基础设施的兼容性,VCM 则是更为自然的选择:无需在源端引入 AI 处理,可与标准视频编解码技术无缝衔接,融入现有编码工作流。若实际需求是以单一编码资产同时服务于AI推理与人工视觉,V-Nova 则已在这一细分赛道占据了先发优势。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。