
一、背景
1.1 语音传输频率支持
常见的语音通话系统包括手机通话、车载或音箱蓝牙通话、微信QQ等即时通讯VOIP通话,以及多人通话的会议、直播等场景。
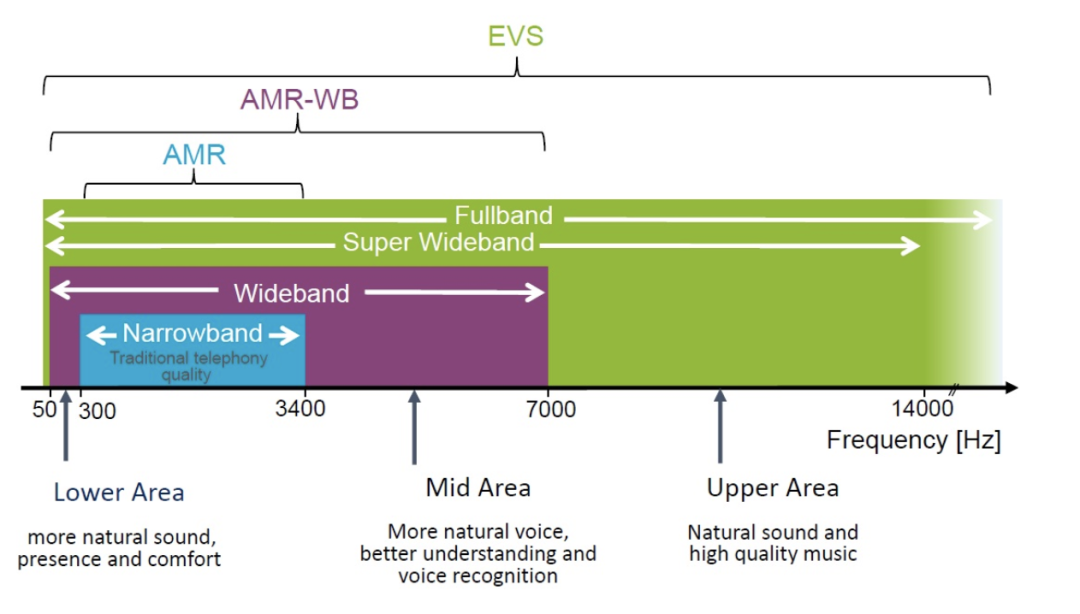
传统的通话是建立在运营商制定的各种传输协议上的一对一语音信息传输系统,随着互联网的高速发展,基于网际协议(IP)达成的语音或者视频通话与多媒体会议,“声临其境”的语音体验也不可获取。当然,传统运营商更高频率范围支持的编解码技术迭代也从未停止,图1中可以看到,从2G时代的窄带通信(Narrowband)到目前3G和4G普遍在用的宽带通信(Wideband),再到可以支持超宽带(Super Wideband)和全宽带通信(Fullband)的增强语音编码技术(Enhancement Voice Services),用户的语音体验也越来越“声临其境”。

1.2 语音评估主客观思路
当然用户不知编解码为何物,对于产品而言,用户体验最终的“音质好”才是王道,决定音质好坏除了上述的运营商或者服务器端带宽网络的技术支撑外,还有终端设备(包括器件、硬件、算法)、用户使用环境、用户个体主观经验差异等因素。其中网络、终端设备、物理环境均可在实验室进行高精度还原重构,可重复的客观物理条件也是语音音质能够客观评价的前提。主观的差异虽因人而异,但大部分人的听音反馈与可给予适度倾斜权重的专家意见也足够可以构成主观音质评价的主要内容。
如果把近端说话人的信号看作系统的输入,把远端设备播出的信号看作系统的输出,那么整个通话系统可以被抽象作“黑匣子”,通过对比输入语音(原始未失真的)和输出语音(经过处理的),提取两种信号的特征参数建立评价模型给出结果,基于此的语音评估是纯黑盒化的测试思路,但也最大程度接近用户体验。另外,如果评测中参考了未处理的语音则是有参评价,反之则是无参评价。目前业界绝大多数的评测都是有参评价。
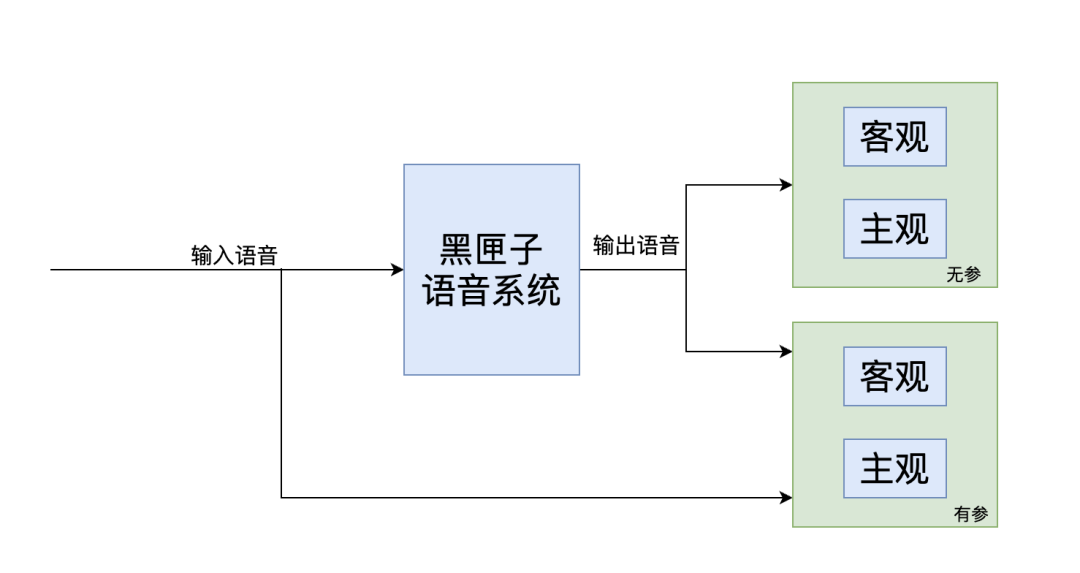
但由于系统链路的复杂,问题的定位因此变得棘手,拆解出的链路子模块验证必然成为寻找问题根因的手段,当然这种手段仍然不是纯白盒的测试,而是细分拆解式的模块化黑盒测试。因与最终评测验收的目标和思路不同,模块化验证一般集中在产品设计研发的早期阶段,但不管前期如何如何,产品最终的用户体验从始至末都是第一位的。
1.3 语音链路拆解
语音被处理按所在端划分,可分为“传输通道”、“输入通道”和“输出通道”。信号经算法处理之后网络或者信道的传输部分为“传输通道”;输入型电声器件(包括麦克风和AD)与上行算法处理、编码部分为“输入通道”,也即通信中经常提到的上行通路;解码部分、下行算法处理、输出型电声器件(包括扬声器、听筒、耳机和DA)为“输出通道”,即下行通路。除去一些对话双讲的验证场景外,上下行一般孤立地去验证语音效果。
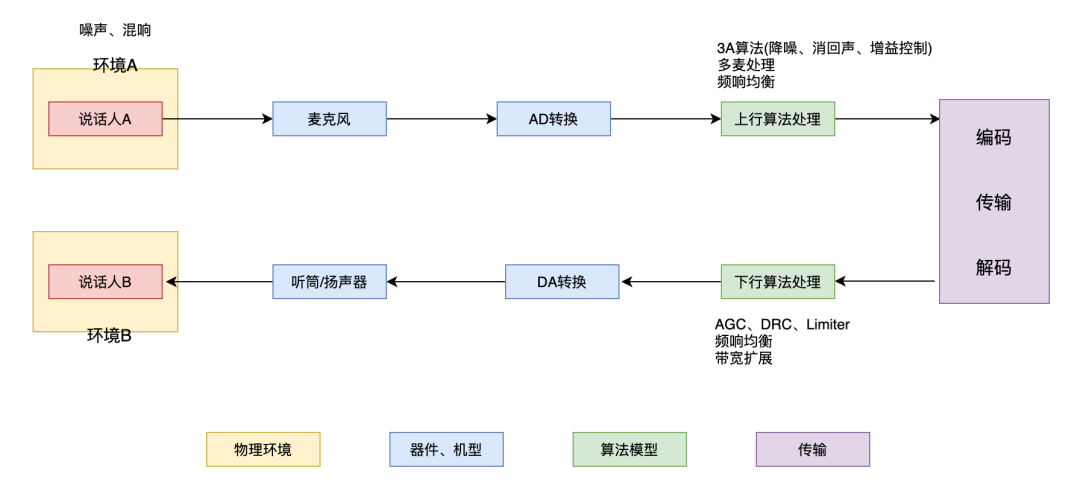
而语音模块化验证的思路一般从单体器件、硬件通路、算法三个维度出发。
- 单体器件,包括拾音的麦克风,扩声的扬声器,或者手持通话的听筒,耳机器件等,这些电声器件的声学指标,如频响、底噪、失真等很大程度决定音质的好坏。
- 硬件通路负责音频信号的传输,AD模块,升降采样模块,时钟,射频干扰,多通道串扰,谐波失真,本底噪声等诸多因素也同样影响算法能否完美的运行在系统之上。注重识别率的产品,如智能音箱要尤其注意硬件电路带来的影响。
- 算法能决定语音系统是否能完成一些基本功能(回声消除、降噪)的同时,又能决定产品是否具有自己的声学特色。上行算法又称语音增强算法,一般包括降噪、回声消除、自动增益控制(3A算法),在车载或者会议场景有时也会有波束形成算法完成定向收音的需求。
对于微信、抖音这些互联网产品来说,硬件层面的东西一般是不可改变的(图中蓝色,器件机型部分,包括单体器件、硬件通路模块),在验证这些产品语音时尽可能多的覆盖常用机型,算法相关的软特性才是验证重点。
二、语音质量评估概述
声音从远端传输而来,每经过一次不同模块的处理,声信号都会卷积上该模块的脉冲响应,语音带来一定程度增强的同时,也不可避免的会引入一些损伤。正是因为有了损伤,才会有语音质量评估的必要。早期,产品设计人员一般都采用纯主观的方法来进行评价,但主观评测耗时耗力,有时候主观差异也较大,因此专业有经验的听音人员的意见尤为重要,最后也需要科学合理的统计方法完成结果的输出。
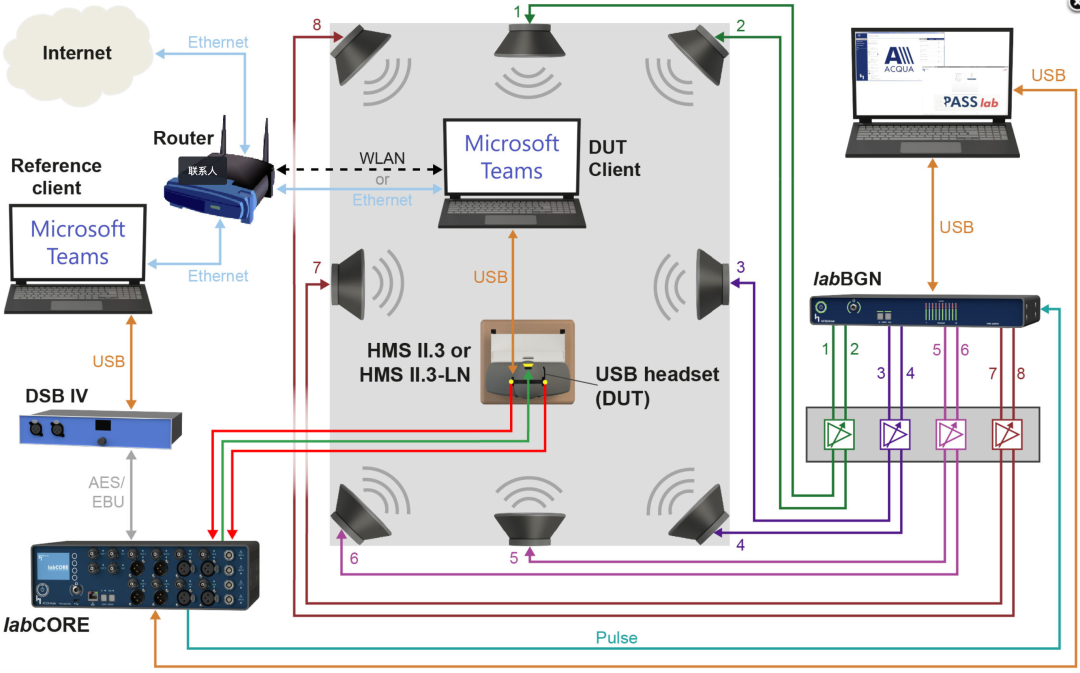
语音质量评测客观化,一直都是学术和商业界的热点。一些实验室和公司采用了能够模拟真实声学环境的设备来进行声音品质的测量,他们秉承“一切可听皆可测”的原则,针对不同的声音特性设计不同的测试信号与测试方法,结合傻瓜式的操作和美观简洁的报告,在业界也取得了一定的认可,比如德国Head Acoustics公司的Acqua测试系统,配合网络模拟器(Network Simulator)和高仿生的人工头(Hats),在人工构造的声学、网络环境中客观评测语音的性能。图4是微软对会议硬件设备的认证测试环境示意,虽然此种客观方法准确、可重复性高,但成套设备价格昂贵的令人咂舌,且非强制认证的终端设备对此并无硬性需求,另外也很难覆盖一些比较极限的使用场景,比如强风噪、强混响等场景。
目前国际上比较通用的语音质量评价标准主要是依据ITU-T的P系列关于语音系统性能评价标准,比如P.800的语音质量的主观评价方法、P.862的PESQ,P.863的POLAQ的客观性能方法等,另外还有针对不同终端设备的客观评价方法比如车载Carplay认证的的P.1100和P.1110系列,针对多人会议语音系统的P.1300系列等。
三、语音质量客观评估
2.1 语音客观评估设备介绍
如前所述,语音质量客观评估通常在专业的实验室中进行,会配套相应的实验室和测试仪器,包括:
- 消声室,A加权噪音小于25dB,截止频率小于250Hz,能提供足够安静的环境,屏蔽外界干扰,无声反射引起的染色效应。
- 依据ITU-T P.57 P.58标准制定的带有仿真耳和仿真嘴的人体躯干( Head and Torso Simulator),如图5所示。

- 网络模拟器,模拟电信运营商网络环境,能提供不同编解码方式、不同码率的网络模拟器,比如罗德施瓦茨的CMW500;即时通讯软件一般通过网络路由搭建。
- 背景噪声模拟器labBGN前端和3Pass三维声学场景回放系统,通过8路扬声器与1路低音炮,真实复现现实生活的背景噪声场景。
- 模拟前端MFE,能提供多种高性能数字和模拟接口,用于信号的采集和调节。
- 音频分析仪Acqua(Advanced Communication Quality Analysis),功能强大,易于使用,依托ITUT,3GPP,ETSI等标准,傻瓜式操作,可一键导出质量报告。
2.2 语音客观评价主要性能指标介绍
设备齐全了之后还要关注其他一些物理条件,比如手机手持通话场景,手机按压耳朵的压力(牛顿),免提或者会议终端时,人工嘴与麦克风之间的距离等,接下来就是重点要关注的指标了:
- 时延(Round Trip Delay),用来确定信号从发送到接受,经过系统所需要的时间,是所有测试的基础,主观表现为一端发送声音到另一端端接受声音时间的长短,如果时间过长,两端对话延迟感非常强,难以正常沟通,一般要求在200ms左右。
- 上下行响度评价(Loundness Rating),评价上下行音量大小,主观表现为人耳收听到声音的大小。下行响度测试时,还要注意不同音量的设置。
- 上下行频率响应(Frequency Response),描述系统对不同频率输入信号的响应特性,一般所指为幅度响应,主观表现为上下行频率均衡度。国际标准都有严格的框线来限定频响曲线的上下限。主观感受所描述的“声音闷”,一般是因为中高频响应过低,“声音尖”则是高频过多。
- 底噪(Idle Channel Noise),底噪分为上行和下行底噪两部分,通过控制底噪,使其低于某个限度且保证底噪均匀、连续,同时又不引起用户反感。底噪的主要来源有:硬件底噪(如上行有麦克底噪、电路底噪)和算法处理残留噪声。
- 失真(Distortion),原始的发送信号之外,接收到的其他信号分量,通常是由设备或者算法处理的非线性引入。
- 音质MOS(Objective Speech Quality Assessment),评分从1到5打分,分值越高,语音质量越好,主要用于衡量经过算法处理后,信号的畸变程度,通过算法处理后,信号畸变程度越小,MOS分值越高。
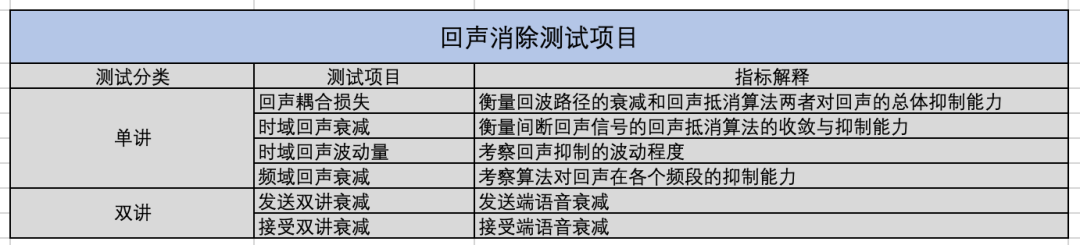
- 回声抑制(Echo Cancellation),回声抑制分单讲和双讲两种场景,双讲和单讲是一对矛盾,适当放松回声抑制量,双讲效果会得到提升。回声抑制量不够则容易残留弱回声或者残留回声声纹,表现为对端能听见自己的说话声,在免提设备(扬声器扩声)的场景下易表现明显。一些标准中,关于回声抑制的评测也细化的较为详细,见表1。
- 降噪3Quest,评价上行降噪后的噪声质量、语音质量,主观表现为本地降噪后对端听到语音质量的好坏,由标准 ETSI_202-396-3计算。测试时,在不同的背景噪声下,通过参考原始语音信号、终端处理完的发送信号、靠近终端标准麦克风录制到的信号三者之间的比对,完成S-MOS(Speech MOS),N-MOS(Noise Mos),G-MOS(Global Mos)三参量的计算。
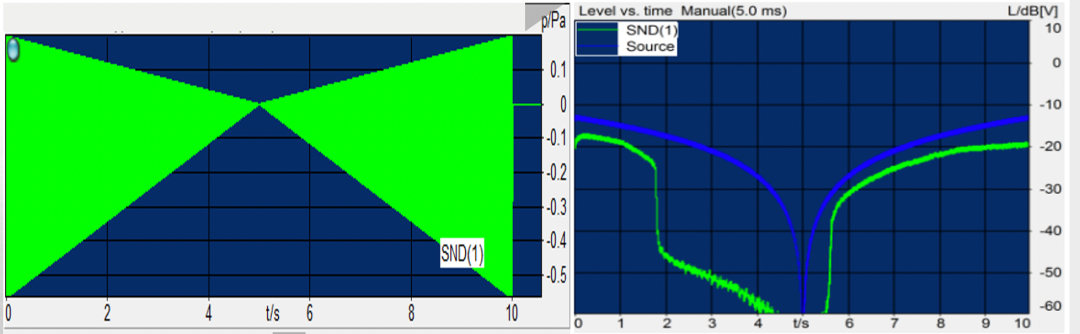
- AGC Test,图6中左图为测试源信号,信号从大到小,然后从小到大变化。图6中右图为测试结果,蓝线为源信号的Level vs time,绿线为处理完的信号的Level vs time。目前没有明确的标准规定,绿色曲线到什么状态是好,什么状态是不好,但个人认为,绿色曲线右半部分的特性较好,在小信号的时候当成噪声消除掉,当源信号慢慢变大时,发送信号的幅度也随着源信号的变化而缓慢增加。
2.3 语音客观质量综合评价
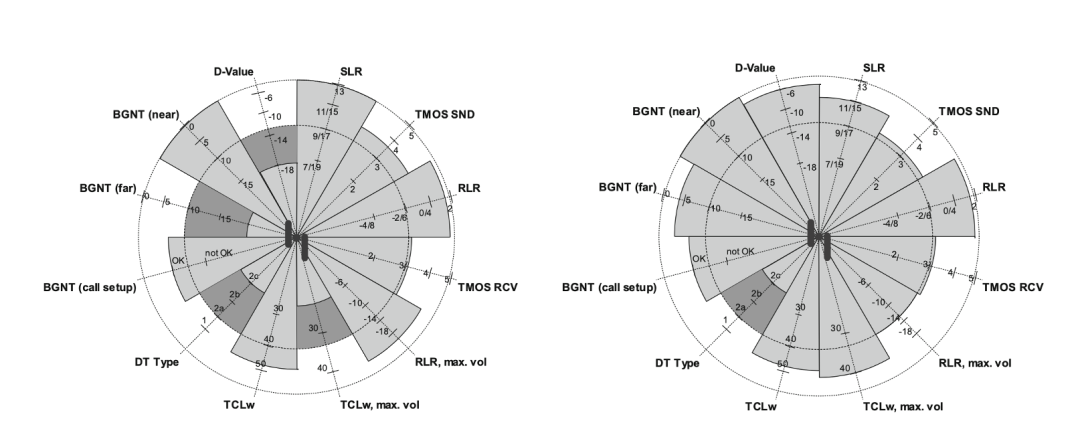
以上各指标都基于某一个明确的检测目标(针对降噪或回声),每个指标只能看护某一块算法或者特性,目前还没有一个能综合体现语音音质的指标。Tmos虽然综合了响度、频响、失真等因素,但是没有考虑到回声抑制、降噪的效果。不过,换一种思路,不执拗于找到一全能指标做这件事,通过直观的可视化展示也可给人带来最直观的“听感”体验,如图7所示的“语音客观质量玫瑰图”,可以轻松判断左图展示产品的综合性能要明显低于右侧。
另外,得益于计算力的提升,基于大数据驱动的,无参考的语音质量客观综合评估也有新进展。这也是一种找到“全能指标”衡量语音质量的一种新解法。比如,腾讯的无参考语音质量评估 LSQA算法,通过深度学习的方式,对语音进行综合质量评估给出1-5的分值,把以往复杂的主观实验 MOS 打分交给深度神经网络来完成。据了解,LSQA已经用于腾讯会议的日常语音质量监控。这也是语音质量客观评价未来的一个趋势。主要难点是如何收集海量的拥有真实用户打分的标签数据。
四、语音质量主观评估
客观的方法,虽然看起来很高大上,但却不能完全取代主观方法。比如主观方法可以是听音场景(单工)也可以是会话场景(双工),另外主观试验可以通过严格控制听音样本(年龄、地域、性别)、听音环境等来复制用户的使用环境,某种程度上来说,其本身就可以代表完全真实的用户的主观感受。在缺少精密设备的条件下,主观评测更应给予足够的重视。
4.1 主观听音对象
由于语音的特殊性,不同群体对声音的感受和描述是不一样的,所以一般的主观听音对象有三个群体:
1)普通群体,如果不刻意强调不会在意异常微小声音。这类人最接近广大的用户,在产品研发阶段,可以发动公司内部群体为第一批“天使用户”,通过筛选“天使用户”的反馈,提前发现一些问题。这部分是大家所说的众测部分。
2)声音敏感者群体,能对异常声音给出比较靠谱的描述,通过问卷教程等的引导能够关注产品的声学性能,能主动反馈问题,能够参与多样本的听音实验。
3)听音专家团队,声学产品研发团队必备的金耳朵,对异常声音尤其敏感,能指出产品同竞品之间的声学性能差异并能给出指导性的意见供调试的同学调参优化。
针对普通群体反馈的“天使意见”,严格意义上不属于主观听音的范畴。主观听音实验通常会在可以营造安静环境和噪声环境的听音室中进行,其中噪声环境是通过专用的音响设备播放各类噪声源进行模拟进行的。
4.2 主观评价方法
ITU-T P.800 «语音质量的主观评价方法》是对电话传输系统中声音质量主观评价的概述, 其本质是平均意见分, 同时给出语音质量主观评价的普遍方法和普遍测试环境,其他所有语音主观评测测试都应遵循该建议。
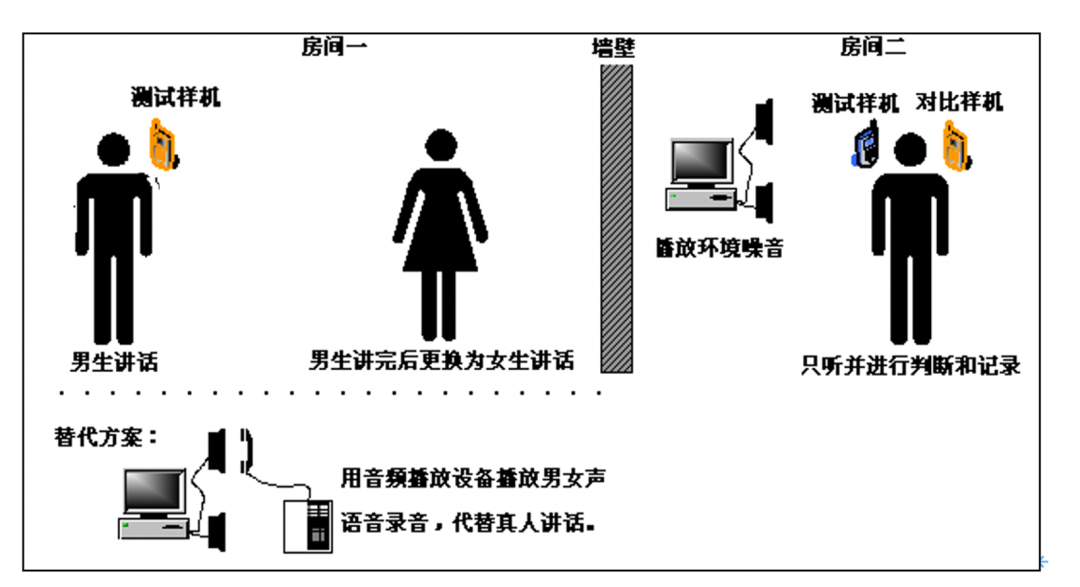
常用主观评价方法一般分为收听评价测试(listening-only opinion tests,简称收听测试)和会话评价测试(conversation opinion tests,简称会话测试)两种。会话测试要求测试人员两人一组进行,测试中要尽量模拟用户进行自然的对话交谈,交谈结束后对主观效果给出评价。这种测试方法虽然更接近于用户实际使用感受,但同时也容易忽略一些不太明显的语音损伤问题,如交谈过程中的轻微回声和双讲问题等,如图8。
收听测试则是在测试中,一名测试人员在一端讲话,其他人员在另一端进行收听,收听结束后对主观效果给出评价。这种测试方法虽然无法像会话测试那样模拟用户的真实使用感受,但测试人员却能更关注于语音质量的优劣;同时收听测试允许测试人员使用对比设备进行语音对比,所以测试中更易发现语音损伤的问题。
以上两种测试各有利弊,最理想的方式是将二者全部覆盖,但会耗费大量的时间与人力,因此考虑到实际测试项目的特点,主观评价方法采用以收听评价测试为主,在个别测试项中(如双讲、回声等)辅以会话评价测试的方式进行,以便更好的结合两者的优点。在主观听音过程中,主要关注点包括不限于:上下行响度是否合理、音质测试(可懂度、柔和度、还原度、平稳度)、底噪杂音、回声、双讲、噪声场景、异常场景等。
4.3 主观听音评定等级设计
在主观听音意见评定时,主要方法有绝对等级评定(ACR) 、损伤等级评定(DCR) 、比较等级评定( CCR)等。对于非音质类的指标,一般采用绝对标准,力使产品性能达到最优。比如,针对底噪,可设计以下评定等级进行评测:
5=没有噪音
4=轻微噪音,不易引起注意
3=噪音不能忽略,不影响语音
2=噪音非常明显,影响语音质量
1=噪音非常明显,导致语音很难听清
而对于音质类的描述,比如清晰度,需要参考竞品或者标杆产品为基准进行判断,比如产品的语音清晰度,参考设计比较等级如下:
5=卓越,明显超出竞品
4=较好,比竞品稍好
3=一般,与竞品相当
2=较差,稍差于竞品
1=差,明显差于竞品
实际测试过程中,每位听音者,针对不同关注点给出评定等级,最后通过一定的数理统计方法得到产品综合等级评分。具体等级的设定,也视具体情况而定。
4.4 极限场景
常规场景没问题的产品不一定是优秀的产品,但在极限场景下发挥依然稳定的产品一定算得上优秀。在主观验证的时,可刻意复制用户的极限场景来验证系统的鲁棒性。语音的极限场景,通常包括以下,当然也要考虑不同产品的实际使用情况:
• 强噪声场景,比如手机在吵闹的车站机场、车载麦克风距离空调出风口太近。
• 强混响场景,声反射较强的小房间,浴池、卫生间等。
• 用户使用不当场景,麦克风进粉尘遮挡收音口,手机麦克被手机保护套完全挡住等。
某些极限场景,算法处理不了亦属正常的,此类问题的解决应在于正确引导用户的使用场景。
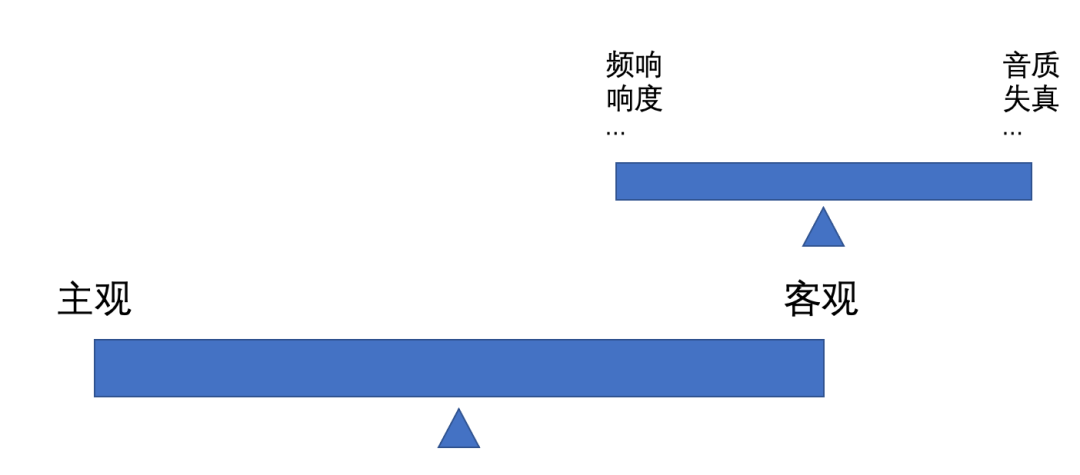
总体而言,主客观也是一个相互权衡Tradeoff的过程,主观好,客观不一定好,客观好,主观也不一定好,二者要维持在一个平衡的状态,如图9。目前业界的统一做法是,总体原则是以主观为主,客观不追求最高,但必须要满足一些硬性的指标(运营商标准等)。
以上就是关于通话质量保障的评测方案,当然对于VOIP产品来说,网络依赖、多终端依赖等特点会决定其一些独有的评测方式,有关这部分内容会在后续的文章中再给大家分享。
最后,欢迎大家转发并关注,更多关于音视频评测的干货内容等着你!
六、参考文献
1.客观听音质量模型的开发 朱晓峰 中国泰尔实验室
2.语音增强理论与实践 【美 罗艾州】2012版
3.httpswww.head-acoustics.cncn Head Aouctics 产品说明
4.ITU-T P.1301 Subjective quality evaluation of audio and audiovisual multiparty telemeetings
5.ITU-T P.1312 Method for the measurement of the communication effectiveness of multiparty telemeetings using task performance
6.ITU-T P862 Perceptual evaluation of speech quality (PESQ) An objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs
7.ITU-T Recommendation P.808, Subjective evaluation of speech quality with a crowdsourcing approach. Geneva: International Telecommunication Union, 2018.
8.ITU-T Recommendation P.835, Subjective test methodology for evaluating speech communication systems that include noise suppression algorithm. Geneva: International Telecommunication Union, 2003.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。