
本文分享来自 Meta 的工程师采用一种基于机器学习 (ML) 的方法,能够跨层全面解决网络问题,如 BWE(带宽估计)、网络弹性和传输。作者: Santhosh Sunderrajan, Liyan Liu。
Meta 现有的带宽估算(BWE)模块基于 WebRTC 的谷歌拥塞控制器(GCC)。我们通过参数调整进行了一些改进,但这导致系统更加复杂,如图 1 所示。
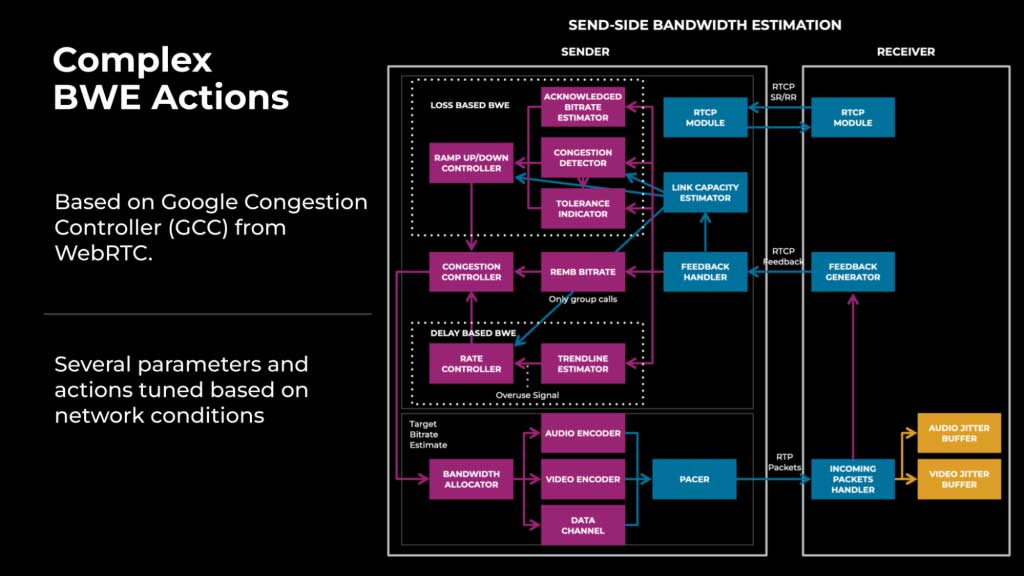

调整后的拥塞控制(CC)/BWE 算法面临的一个挑战是,它有多个取决于网络条件的参数和操作。例如,在质量和可靠性之间存在权衡;为高带宽用户提高质量往往会导致低带宽用户的可靠性下降,反之亦然,这使得在不同网络条件下优化用户体验具有挑战性。
此外,我们还注意到在改进和维护具有复杂 BWE 模块的模块方面存在一些效率低下的问题:
- 由于我们在实验过程中缺乏真实的网络条件,因此需要多次尝试为用户客户端微调参数。
- 即使在推出之后,也不清楚优化后的参数是否仍然适用于目标网络类型。
- 这导致工程师需要维护复杂的代码逻辑和分支。
为了解决这些效率低下的问题,我们开发了一种基于机器学习(ML)的网络目标方法,为手工调整规则提供了更简洁的替代方案。这种方法还允许我们跨层整体解决网络问题,如 BWE、网络弹性和传输。
网络特征描述
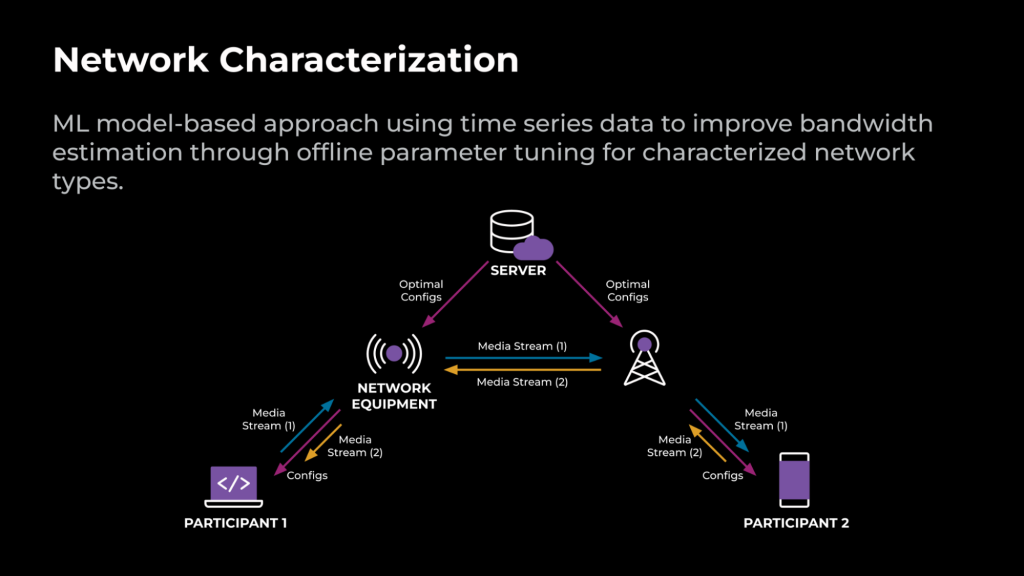
基于 ML 模型的方法利用时间序列数据,通过对特征网络类型进行离线参数调整来改进带宽估算。
要完成 RTC 呼叫,端点必须通过网络设备相互连接。经过离线调整的最佳配置存储在服务器上,并可实时更新。在呼叫连接设置过程中,这些最佳配置会传送到客户端。在通话过程中,媒体在端点之间直接传输或通过中继服务器进行传输。根据通话期间收集到的网络信号,基于 ML 的方法将网络特征分为不同类型,并针对检测到的类型应用最佳配置。
图 2 举例说明了使用基于 ML 的方法优化的 RTC 呼叫。
模型学习和离线参数调整
如图 3 所示,网络特征描述包括两个主要部分。第一个部分是离线 ML 模型学习,使用 ML 对网络类型进行分类(随机丢包与突发丢包)。第二个部分是使用离线模拟,针对分类后的网络类型优化参数。
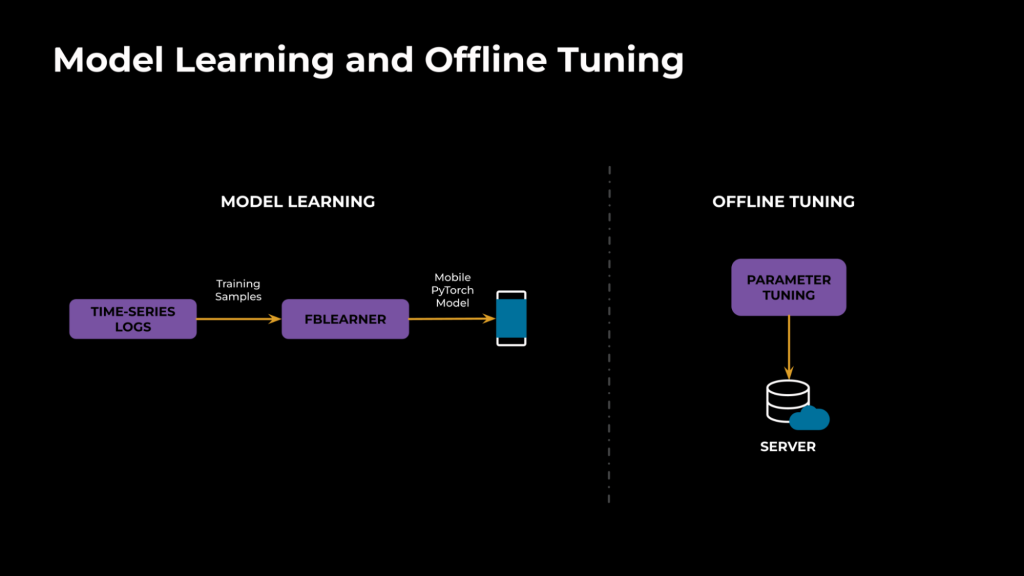
在模型学习方面,我们利用了来自生产调用和模拟的时间序列数据(网络信号和非个人身份信息,见下图 6)。与调用后记录的综合指标相比,时间序列能捕捉到网络和动态的时变特性。我们使用内部人工智能堆栈 FBLearner 作为训练管道,并在调用开始时按需向客户提供 PyTorch 模型文件。
在离线调整方面,我们使用模拟来为检测到的类型运行网络配置文件,并根据技术指标(如质量、冻结等)的改进情况为模块选择最佳参数。
模型架构
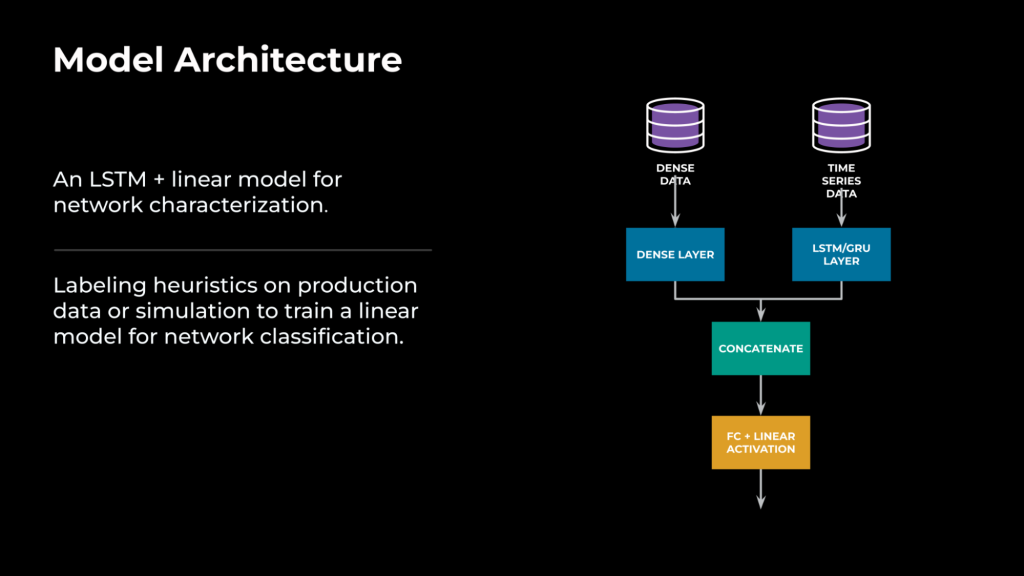
根据我们的经验,我们发现有必要将时间序列特征与非时间序列(即时间窗口中的衍生指标)相结合,以实现高精度建模。
为了同时处理时间序列和非时间序列数据,我们设计了一个模型架构,可以处理来自两个来源的输入。
时间序列数据将通过一个长短期记忆(LSTM)层,该层会将时间序列输入转换为一维向量表示,如 16×1。非时间序列数据或密集数据将通过密集层(即全连接层)。然后,这两个向量将被串联起来,以完全表示过去的网络状况,并再次通过全连接层。神经网络模型的最终输出将是目标/任务的预测输出,如图 4 所示。
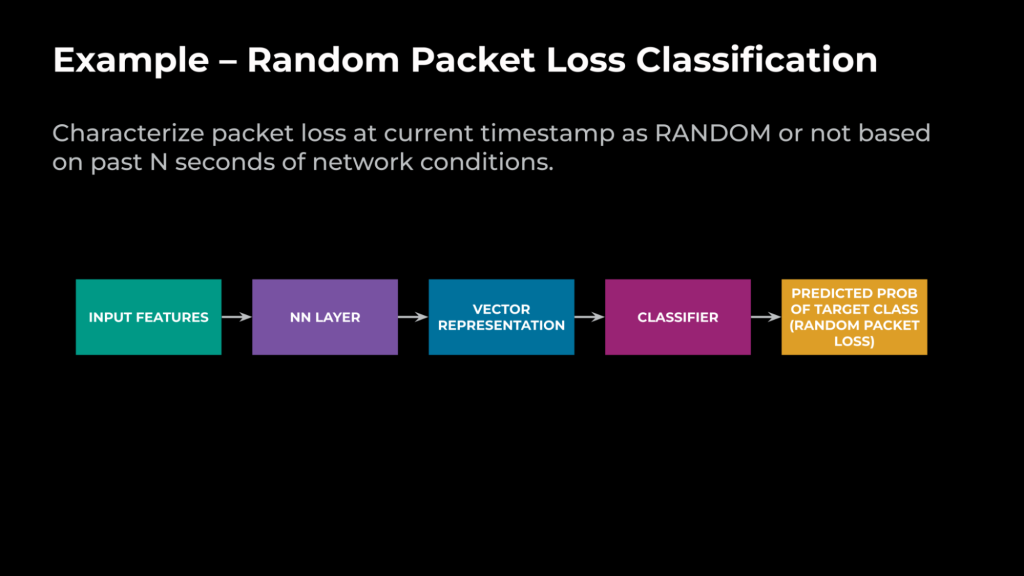
用例:随机丢包分类
让我们考虑一下将丢包分为随机丢包和拥塞丢包的用例。前者的损失是由网络组件造成的,后者的损失是由队列长度限制(与延迟有关)造成的。下面是 ML 任务的定义:
给定过去 N 秒(10)内的网络条件,并且网络当前正在发生数据包丢失,目标是将当前时间戳下的数据包丢失描述为随机或非随机。
图 5 展示了我们如何利用架构来实现这一目标:
时间序列特征
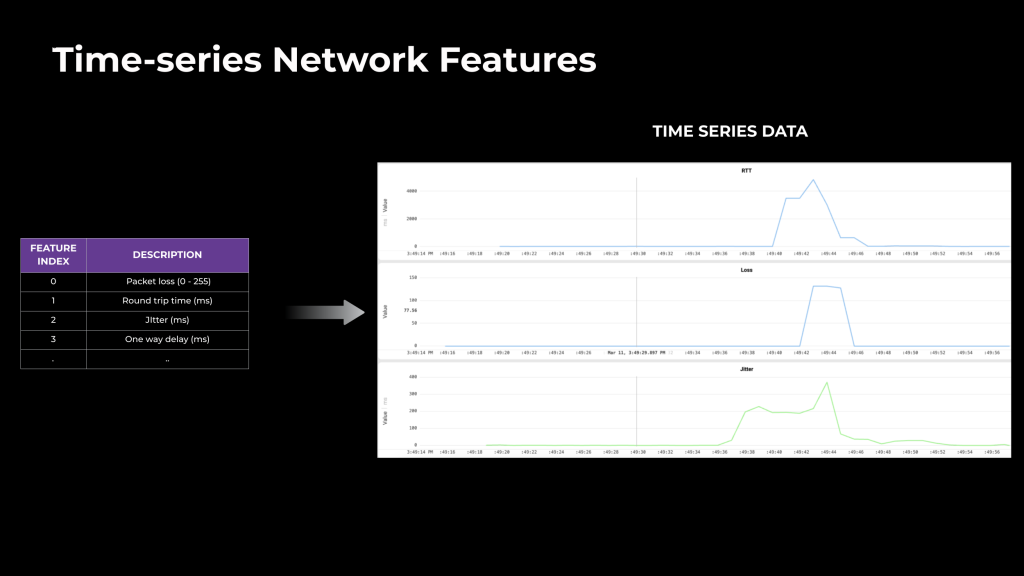
我们利用从日志中收集的以下时间序列特征:
BWE 优化
当ML模型检测到随机丢包时,我们通过以下方式对BWE模块进行局部优化:
- 提高基于丢失的 BWE(保持比特率)中对随机数据包丢失的容忍度。
- 提高加速速度,具体取决于高带宽上的链路容量。
- 通过发送额外的前向纠错数据包以从数据包丢失中恢复来提高网络弹性。
网络预测
前面几节讨论的网络表征问题重点是使用时间序列数据根据过去的信息对网络类型进行分类。对于那些简单的分类任务,我们使用手动调整的规则来实现这一点,但有一些限制。然而,利用机器学习进行网络的真正力量来自于使用它来预测未来的网络状况。
我们应用机器学习来解决拥塞预测问题,以优化低带宽用户的体验。
拥塞预测
通过对生产数据的分析,我们发现低带宽用户经常会因 GCC 模块的行为而导致拥塞。通过预测这种拥塞,我们可以提高此类用户行为的可靠性。为此,我们利用往返时间(RTT)和数据包丢失来解决以下问题:
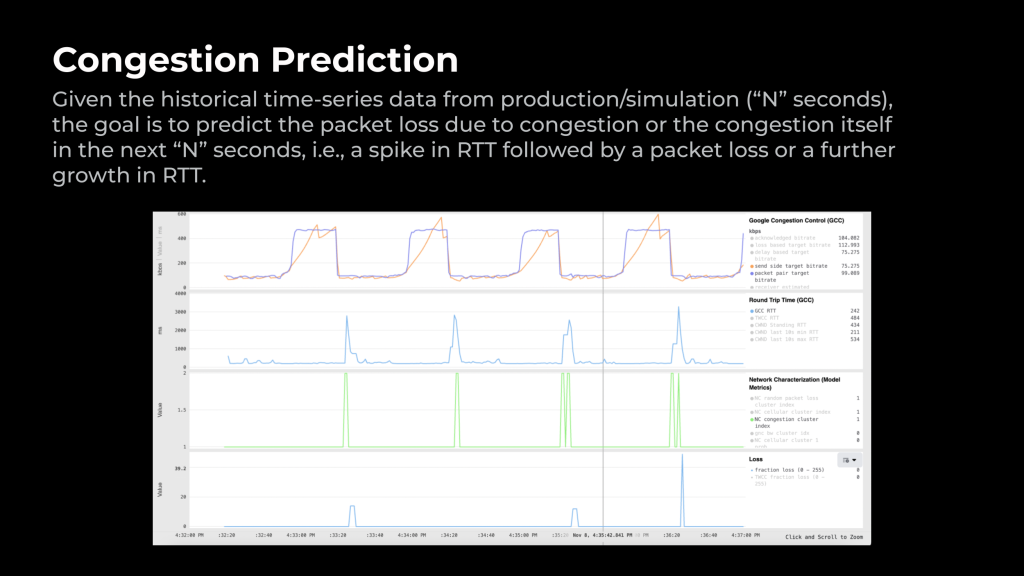
给定来自生产/模拟的历史时间序列数据(”N “秒),目标是预测下一个 “N “秒内由于拥塞或拥塞本身造成的数据包丢失;也就是说,RTT 出现峰值,随后出现数据包丢失或 RTT 进一步增长。
图 7 显示了一个模拟示例,带宽每 30 秒在 500 Kbps 和 100 Kbps 之间交替变化。当我们降低带宽时,网络就会出现拥塞,而 ML 模型预测甚至会在延迟尖峰和数据包丢失发生之前就触发绿色尖峰。这种对拥塞的早期预测有助于更快地做出反应,从而通过防止视频冻结和连接中断来改善用户体验。
生成训练样本
建模的主要挑战在于为各种拥塞情况生成训练样本。通过模拟,我们很难捕捉到真实用户客户端在生产网络中可能遇到的各种拥塞情况。因此,我们使用实际的生产日志来标记拥塞样本,并根据以下假设在过去和未来窗口中遵循 RTT 峰值标准:
- 如果没有过去的 RTT 峰值,过去和未来的数据包丢失是独立的。
- 如果没有过去的 RTT 峰值,我们无法预测未来的 RTT 峰值或部分损失。
我们将时间窗口分为过去(4 秒)和未来(4 秒)进行标记。

模型性能
与无法获得基本事实的网络特性分析不同,我们可以在未来时间窗口过去后对其进行检查,然后将其与四秒前的预测进行比较,从而获得基本事实。有了这些从真实生产客户端收集到的日志信息,我们就可以将离线训练的性能与来自用户客户端的在线数据进行比较:

实验结果
以下是我们部署各种 ML 模型来改进带宽估算的一些要点:
拥塞预测以可靠性取胜
✅ connection_drop_rate -0.326371 +/- 0.216084
✅ last_minute_quality_regression_v1 -0.421602 +/- 0.206063
✅ last_minute_quality_regression_v2 -0.371398 +/- 0.196064
✅ bad_experience_percentage -0.230152 +/- 0.148308
✅ transport_not_ready_pct -0.437294 +/- 0.400812
✅ peer_video_freeze_percentage -0.749419 +/- 0.180661
✅ peer_video_freeze_percentage_above_500ms -0.438967 +/- 0.212394
高带宽中随机丢包特征的质量和用户参与度胜出
✅ peer_video_freeze_percentage -0.379246 +/- 0.124718
✅ peer_video_freeze_percentage_above_500ms -0.541780 +/- 0.141212
✅ peer_neteq_plc_cng_perc -0.242295 +/- 0.137200
✅ total_talk_time 0.154204 +/- 0.148788
蜂窝低带宽分类的可靠性和质量获胜
✅ connection_drop_rate -0.195908 +/- 0.127956
✅ last_minute_quality_regression_v1 -0.198618 +/- 0.124958
✅ last_minute_quality_regression_v2 -0.188115 +/- 0.138033
✅ peer_neteq_plc_cng_perc -0.359957 +/- 0.191557
✅ peer_video_freeze_percentage -0.653212 +/- 0.142822
蜂窝高带宽分类的可靠性和质量双赢
✅ avg_sender_video_encode_fps 0.152003 +/- 0.046807
✅ avg_sender_video_qp -0.228167 +/- 0.041793
✅ avg_video_quality_score 0.296694 +/- 0.043079
✅ avg_video_sent_bitrate 0.430266 +/- 0.092045
将 ML 应用于 RTC 的未来计划
通过在生产客户端上执行项目和进行实验,我们注意到基于 ML 的方法在目标定位、端到端监控和更新方面比传统的手工调整联网规则更有效。然而,ML 解决方案的效率在很大程度上取决于数据质量和标记(使用模拟或生产日志)。通过应用基于 ML 的解决方案来解决网络预测问题(尤其是拥塞问题),我们充分发挥了 ML 的威力。
未来,我们将使用多任务方法将所有网络表征模型合并为一个模型,以解决由于模型下载、推理等方面的冗余而导致的低效率问题。我们将为时间序列建立一个共享表示模型,以解决网络表征中的不同任务(如带宽分类、丢包分类等)。我们将专注于构建真实的生产网络场景,以进行模型训练和验证。这将使我们能够利用 ML 确定网络条件下的最佳网络操作。我们将坚持不懈地改进基于学习的方法,通过考虑现有的网络信号来提高网络性能。
原文:https://engineering.fb.com/2024/03/20/networking-traffic/optimizing-rtc-bandwidth-estimation-machine-learning/
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/yinshipin/45570.html