
本文提出了一个连续码率可调的深度学习图像编码框架,即非对称增益变分自动编码器(AG-VAE)。AG-VAE利用一对增益单元在一个单一的模型中实现离散可变码率,其额外的运算量可以忽略不计。然后,通过使用指数插值的方式,在不影响性能的情况下实现连续可变适应。此外,本文中还提出了非对称高斯熵模型,以实现更精确的熵估计。实验结果表明,该方法实现了与SOTA深度学习图像压缩方法相当的压缩性能。通过消融实验也证实了增益单元和非对称高斯熵模型的优越性。
论文标题:Asymmetric Gained Deep Image Compression with Continuous Rate Adaptation
来源:CVPR 2021
主讲人:Cui Ze, Wang Jing 等
内容整理:张一炜
引言
图像压缩是图像处理和计算机视觉中最基本的问题之一。一些基于VAE的图像压缩方法需要训练多个固定码率的模型来实现可变码率,每个模型用于一个码率点。因此,训练成本和内存需求随着所需速率范围的增长和细化而急剧增加。其他一些方法不使用多个模型,而是使用一个单一的模型实现可变码率。例如,基于RNN的方法采用渐进式编码的方式,这种方法的RD性能较差。条件自编码器的方法将全连接层与卷积层相结合来实现离散的可变码率,但这种方法明显增加了模型的复杂度和内存需求。混合量化仓大小的方法虽然可以将码率从有限的离散点扩展到可变范围,但该方法会导致RD性能的下降。bottleneck缩放方法忽略了自编码器和缩放参数之间的兼容性,在低比特率范围内性能较差。尽管在单一模型中提供了可行的可变码率解决方案,但上述方法有各种实际问题,如性能下降、计算复杂性增加和内存增加。
因此,本文提出了一个新的图像压缩框架,AG-VAE。它可以在一个单一的模型中连续调整码率,并在定量指标和定性视觉质量方面实现了与SOTA深度学习图像压缩方法相当的R-D性能。基于通道冗余的不均匀性,本文设计了一个即插即用的可变码率模块,即增益单元。通过简单的通道相乘,增益单元重新调整了隐变量latent的表示。然后在量化过程中控制信息损失的程度。另外,本文还提出了非对称高斯熵模型,以实现更准确的熵估计。在达到相同的失真水平时,只需要更少的码率。
模型架构
AG-VAE的模型框架如下图所示。通过在编码器后插入一个增益单元和在解码器前插入一个反增益单元来实现码率自适应变化。码率可以随着增益向量指数s和插值系数l的变化而不断调整。不对称的高斯熵模型准确地估计了获得的和量化的隐变量的熵。
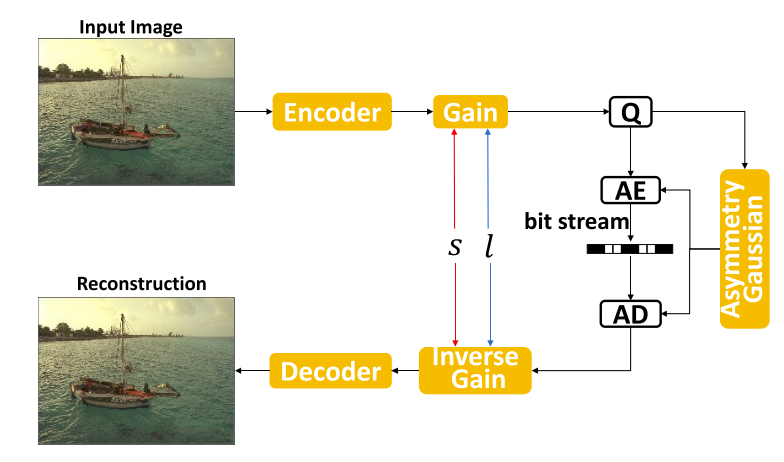

增益单元
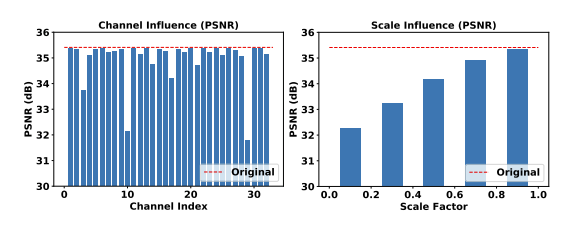
文章中首先进行了一项简单的实验,以展示基于VAE的图像压缩框架中普遍存在的通道不均衡冗余现象。以Kodak数据集的kodim20为例,将隐变量的前32个通道分别设置为零。然后将修改后的隐变量转换回RGB域,并比较不同通道缺失时重建图像的PSNR下降情况,如下图所示。缺失实验中去除通道29的重建质量下降最为严重。并且随着缩放系数的减小,重建质量也随之降低。因而可以得出结论,通道的重要性是不同的,并且可以进行缩放以控制重建质量。然而,许多学习的图像压缩方法忽略了通道之间的不均衡冗余,将它们在量化过程中同等对待。
因此为了利用上述性质,文章中设计了增益单元(gain unit)模块。gain unit中包括了n个与隐变量通道大小相同的增益向量 gain vector,并且可以表示为 ms = ms,0,ms,1…ms,c-1。每个通道都对应一个缩放的数值。对隐变量进行缩放的过程可以表示为通道维度的相乘:
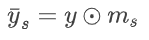
通过这种方式,可以实现在通道维度精细地调整隐变量的量化损失。因此,网络被引导将更多的比特率分配给影响重建质量显著的通道。
在将经过缩放和量化的隐变量提供给解码器之前,需要进行反向缩放操作。该操作用于将隐变量映射回原来的数值区间,从而确保重建的正确性。将缩放和反向缩放操作限制为严格的倒数关系是不可行的。由于中间存在量化操作,隐变量不能通过倒数反向缩放映射到相同的数值区间,因此,在解码器之前,文章中采用了另一个可训练的增益单元来自适应地进行重新缩放,称为反增益单元 inverse gain unit。inverse gain unit的向量与gain unit中的向量一一对应,并记做m`s。反向缩放的过程可以表示为
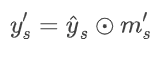
在压缩时,可以选择不同下标s对应的缩放向量与反缩放向量对。通过这种方式,可以在R-D曲线的几个离散点上获得所需的压缩性能。R-D曲线的范围取决于训练时所使用的拉格朗日乘子的大小。
指数插值
由于使用不同的增益单元只能实现离散的可变码率,因此可以通过在增益单元之间进行插值来实现连续的可变码率。增益单元对确保编码器输出与解码器输入的数值区间相同,可以表述为:

可变码率的超先验
超先验网络可以捕捉隐变量的空间依赖关系,并实现对其分布的更准确估计。超先验网络也采用了自编码器结构。它生成超先验隐变量z,由一个非参数,完全分解的熵模型建模。z也需要被算术编码和传输,并作为最终损失的一部分。因此,实现对z的可变码率有助于降低包含超先验网络的学习图像压缩方法的码率。这可以通过再引入一对增益单元来实现对超先验隐变量的缩放和反缩放。
高斯熵模型
参数化分布模型与隐变量的真实边际分布的匹配程度是影响量化隐变量的期望编码长度(比特率)和R-D性能的重要因素。作为目前主流的潜在表示分布估计模型,一般采用单个均值和方差可变的高斯分布来进行。然而,对于具有其他分布的自然图像,对称高斯熵模型的自由度不足,可能会导致较大的估计误差。因此在这篇文章中提出了以下的非对称高斯熵模型:

实验结果
率失真性能
AG-VAE可以实现更好的R-D性能,并且在避免性能下降的同时具备灵活调整码率的能力。并且AG-VAE在PSNR方面获得了比广泛使用的经典图像编解码器BPG更好的结果,与VTM的帧内编码方法获得了竞争性的结果。
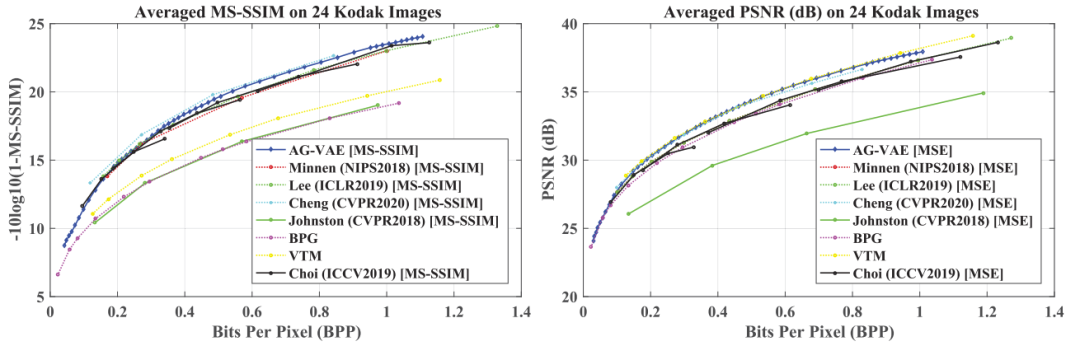

可变码率方法对比
如下图所示,本提出的可变码率方法相比于之前的方法,可以实现灵活调整输出码率,并在整个R-D曲线上取得较好的结果。
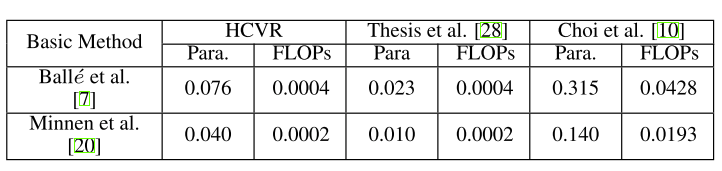
计算复杂度
下表展示了不同可变码率方法的额外参数和计算量增加对比。由于本文的方法只需要对模型输出的隐变量进行额外的乘法操作。本文的方法与bottleneck缩放的方法相比,额外参数百分比小了七倍,且额外FLOP百分比几乎小了100倍。但是,bottleneck缩放的方法在低码率性能下降严重。因此,本文提出方法可以在较小的额外参数和计算下,赋予固定码率模型连续可变码率能力,同时避免性能下降。
消融实验
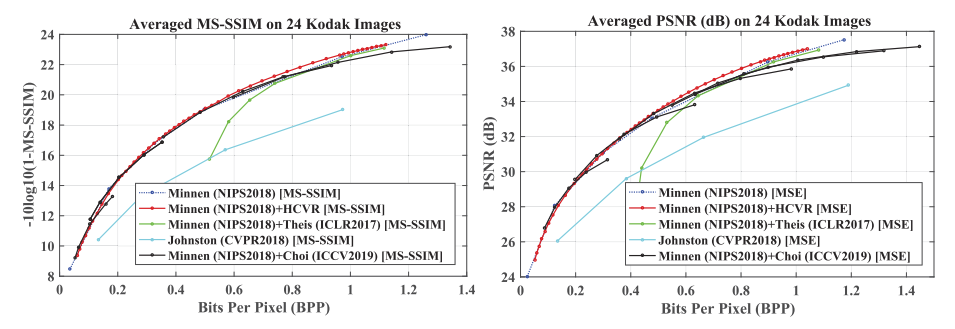
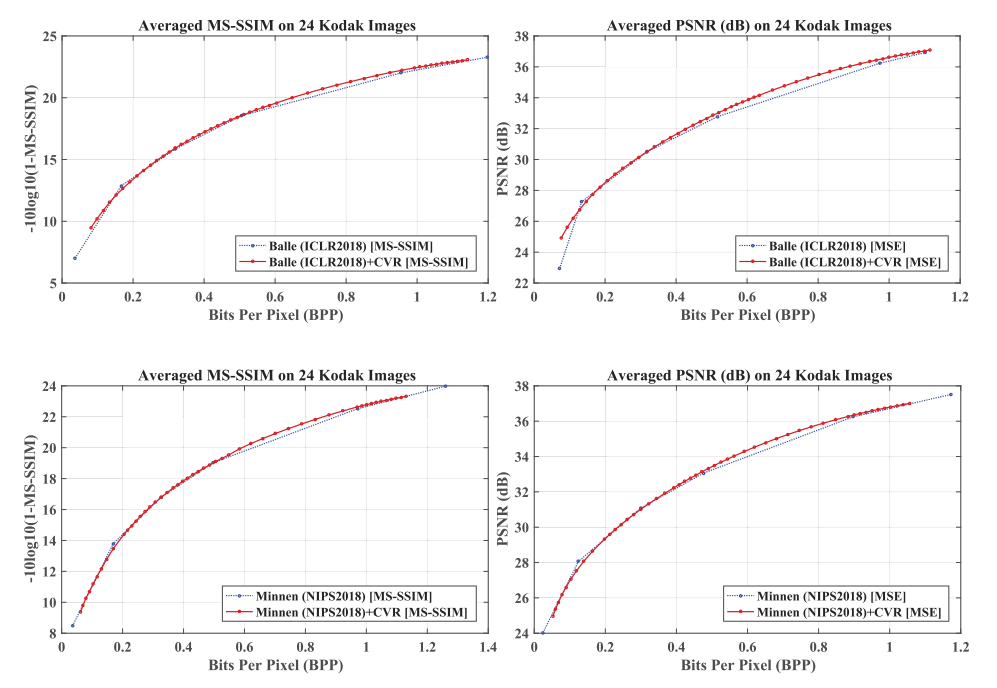
增益单元的通用性
如下图所示,在不同的基线模型上,本文提出的方法可以在避免压缩性能下降的同时实现连续可变码率。
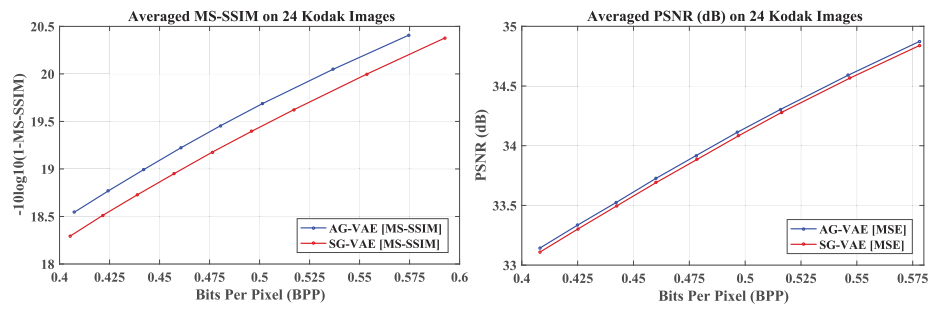
非对称高斯熵模型
在AG-VAE采用中之前的对称高斯熵模型时的版本并将其命名为SG-VAE,并进行对比。如下图所示,AG-VAE在两个度量指标上均实现了比SG-VAE更好的R-D性能。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。