
这篇文章提出了一种用于在自然视频中对人物的情绪状态进行真实感操纵的深度学习方法。该方法基于输入场景中人物的 3D 人脸参数表示,从头部姿态和面部表情中解耦了人脸身份,然后使用一个新颖的深度域翻译框架,以一致且合理的方式改变面部表情,最后基于特别设计的神经人脸渲染器对输入场景中的面部区域进行真实感操纵。广泛的定性和定量评估和对比表明了该方法相对于 SOTA 的优势和在自然视频中的有效性。
来源:CVPR 2022 Oral
论文题目:Neural Emotion Director: Speech-preserving semantic control of facial expressions in “in-the-wild” videos
链接:https://openaccess.thecvf.com/content/CVPR2022/papers/Papantoniou_Neural_Emotion_Director_Speech-Preserving_Semantic_Control_of_Facial_Expressions_in_CVPR_2022_paper.pdf
作者:Foivos Paraperas Papantoniou 等人
内容整理: 林宗灏
引言


近年来,对图像或视频中的人脸进行真实感操纵受到了广泛的关注,其成果在视频编辑、内容创作、VFX 等方面具有重要应用。然而,当问题聚焦于改变视频中的面部表情时,基于静态图像的方法在不对嘴部加以约束的情况下直接应用于视频序列会严重影响口型同步,基于视频的方法仅能使得目标人脸模仿源人脸的面部动作,无法从语义上加以控制。
在这项工作中,我们提出的神经情感导演(NED)将参数化的 3D 人脸表示转化至不同的域,然后通过基于视频的神经渲染器来驱动合成目标人脸,实现了在自然视频中对人物情感的真实感操纵。如图 1 所示,NED 可以只使用语义标签或外部参考视频作为输入,在保留原始嘴部动作的同时对面部情感进行转换。本文的主要贡献如下:
- 我们提出了第一个在自然场景中“指导演员”,将他们的面部表情转换为其他多种情感或风格,而不改变所说语音的基于视频的方法。
- 我们引入了一个名为 3D 情感操纵器的情感转换网络,它接收表情参数并将其转换至给定目标域或参考风格;设计了一个基于视频的人脸渲染器,将参数化表示解码为照片级视频帧。
- 我们进行了大量的定性及定量实验、用户研究和消融实验来评估我们的方法,证明了我们方法在挑战性场景下的有效性和优势。
方法
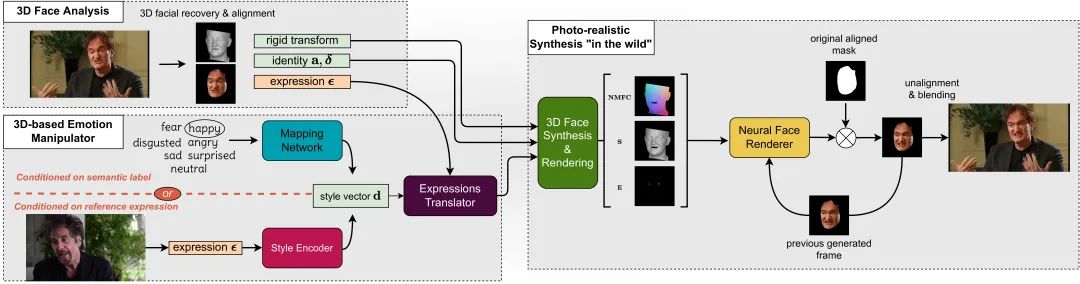
我们的 NED 框架解决了在视频中对面部情感进行语义相关操纵的挑战性问题。如图 2 所示,NED 由 3D 人脸分析、3D 情感操纵器和自然视频中的照片级合成三个主要模块组成。
3D 人脸分析
人脸检测分割
我们首先对人脸进行检测并裁剪调整至 256 x 256 ,然后使用 FSGAN 来分割人脸并去除背景。
3D 人脸重建

关键点检测与人脸对齐
我们使用 FAN 来获得每一帧的 68 个人脸关键点,然后基于眼部区域像素的逆强度估计眼睛瞳孔坐标,并生成眼睛图像 E 来为人脸渲染器提供关于眼睛注视的信息。我们基于人脸特征点和 Procrustes 分析,将所有的人脸帧对齐到同一人脸模板上,这样的对齐方式提高了我们人脸渲染器的泛化能力。
3D 情感操纵器
给定含有 7 种情感标签(中性、高兴、恐惧、悲伤、惊讶、愤怒、厌恶)的集合 γ,我们设计了一个 3D 情感操纵器,该模块将表情序列 s 转换至反映给定情感 y ∈ γ 的序列,并且保持了原始的嘴部运动。
表情转换器

自然视频中的照片级合成
3D 人脸合成与渲染
经过 3D 情感操纵器的表情参数调整,我们得以在新的情感条件下合成 3D 人脸几何。我们使用经典 3D 图形学将其渲染为 NMFC 图像,并与形状图像 S 和眼睛图像 E 串联,以便于后续的神经渲染。
神经人脸渲染器
我们将 NMFC、S 和 E 作为神经渲染器的条件输入。我们基于 Head2Head++ 架构对其进行实现,并以自重现的方式使用原始人脸几何在目标演员的训练镜头上进行训练。考虑到背景的变化,我们除了将当前帧及其前两帧作为生成器的输入外,还引入了原始对齐掩膜将图像合成限制于脸部区域。为了合成训练集中不存在的面部表情,我们先在多名演员的混合视频上训练一个元渲染器,然后在目标演员视频上进行独立微调以保持演员身份不变性。
融合
我们利用对齐矩阵的逆来对生成的人脸图像进行逆对齐,然后使用多频带融合的方式来将合成的面部与原始背景融合,从而得到最终的合成视频。
实验
我们在 YouTube Actor dataset 和 MEAD 数据集上开展了大量的实验来对 NED 进行了全面的定性和定量评估,并与最近的 SOTA 方法进行了比较。
定量比较
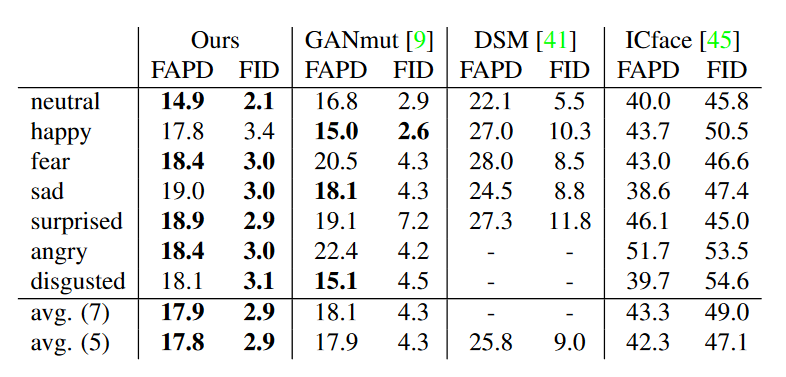
为了评估每种方法在情感操纵方面的性能,我们以自重现的方式进行实验并使用 FAPD 和 FID 作为衡量指标。实验结果如表 1 所示,可视化比较如图 3 所示。可以看出,我们的方法在这两个指标上均优于其他方法,并在所有情感上合成了更具真实感的视频,展现了强大的表情迁移能力。

我们开展了两项用户研究。在第一项用户研究中,参与者以 5 分制对来自 MEAD 数据集的 3 名演员表现 6 种情感的合成视频进行评分,并识别演员表现出的情感类别。结果如表 2 所示,所有的合成方法的真实感分数都相对较低,这可能是因为 MEAD 中的真实视频包含特别强烈的情感表达,导致4、5分出现的频率较低并且更倾向于被赋予真实视频。然而,我们的方法比其他方法在所有 6 种情感上均取得了明显更高的真实感分数。在情绪识别准确性方面,我们的方法相比 DSM 合成了情感更容易被识别的视频。GANmut 方法的识别准确性甚至高于真值视频,这是因为其合成视频具有不真实的强烈表情,非常易于用户识别。
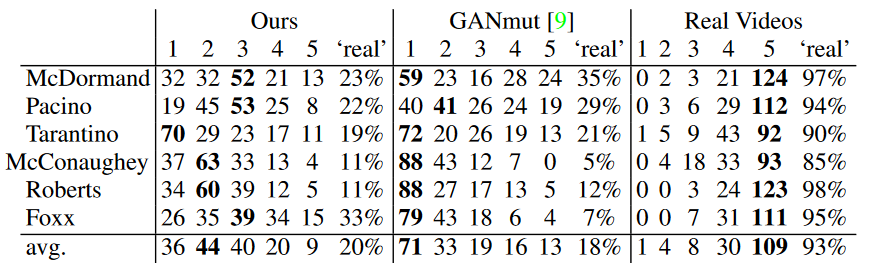
在第二项用户研究中,参与者以 5 分制对来自 YouTube Actor 数据集的 6 名演员表现 6 种情感的合成视频进行评分。结果如表 3 所示,两种合成方法的真实感得分都较低,这是因为操纵修改视频中的人脸表情是一项高挑战性的任务,尤其是在自然情形下。然而,我们的方法比 GANmut 取得了更高的平均分数,体现了我们方法的前途与潜力。
消融实验
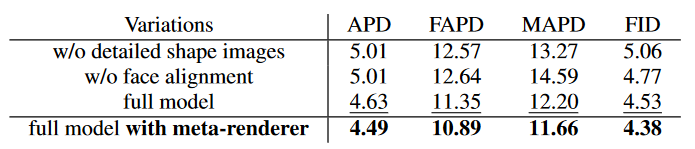
为了在实验上验证我们对人脸渲染器的设计,我们以自重现的方式对形状图像 S、人脸对齐步骤、元渲染器进行了消融实验。实验结果如表 4 所示,形状图像 S 、人脸对齐和元渲染器对合成视频结果(尤其是嘴部区域)均有不同程度的改进。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。