
近几年,自回归模型和diffusion模型等文生图(text-to-image)模型经历了快速发展,但生成结果仍不完美。现有的文生图模型生成内容,存在一些比较明显的问题,包括但不限于:
- 文图对齐问题:不能准确描述文本提示prompts中描述的所有对象、属性、以及属性和对象的关系
- 身体问题: 人类或动物的身体部位(如肢体)出现扭曲、不完整、重复或异常
- 不符合人类审美: 偏离人类审美风格,偏离平均或主流偏好
- 对人类心理有害的内容:包含暴力、性、歧视性、非法或引起心理不适的内容
然而,这些普遍存在的问题很难仅仅通过改进模型架构和预训练数据来解决。在自然语言处理中,通常采用人类反馈的强化学习(RLHF)来指导大语言模型生成更符合人类喜好和价值观的内容。该方法依赖于学习奖励模型(RM),从大量的人工注释和对比中捕获人类的偏好。尽管这种方法是可行的,但因为标注太过于耗时费力,很可能需要很长时间才能建立标注标准、开展主观实验并最终生成有效的RM。在这样的背景下,自动评估文生图内容的人类偏好,对于指导文生图模型的训练和微调有重大意义。
框架总览
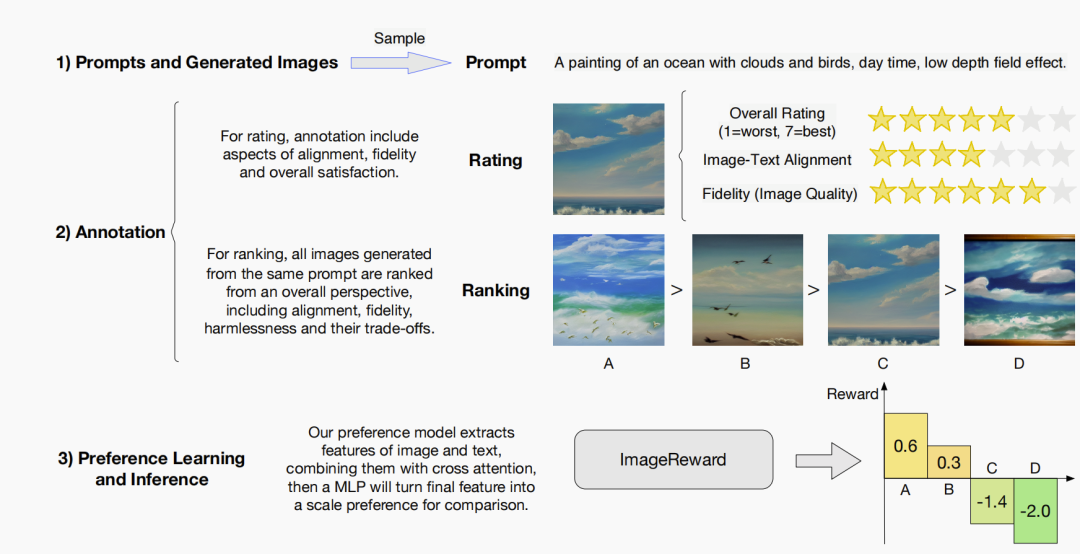

图像奖励标注和RM训练的流程如上图所示,主要分成三个部分。
第一步,准备标注。通过收集和过滤 prompts ,生成具有多样性和代表性的图像数据集。
第二步,标注。它包括两个步骤:1. 从三个维度对图像进行进行评分;2. 从整体角度比较图像并进行排名。
第三步,人类偏好的学习和推理,通过训练 ImageReward 学习图像标注,使其具有分析哪一张图片更容易获得人类偏好的能力。
Prompt选择与图片收集
作者从一个包含了数以百计的 prompts 和 Stable Diffusion 对应生成图像的开源数据集 DiffusionDB 中进行数据的收集与筛选。
为了保证 prompt 分布的多样性,使其涵盖表征用户的真实使用需求,采用了一个根据 prompt 相似度(通过语言模型 Sentence-BERT 产生)的基于图的选择算法,构造一个基于kNN的 1.8M DiffusionDB prompts的相似度图迭代选择top-degree prompts,每轮之后降低被选择的prompts的相邻边的权重。对于每个prompt,从DiffusionDB中选择对应的4-9张采样图片供接下来的标注过程,共产生了177304候选对。
主观标注
人类标注主要分成两个部分,第一部分从单张生成图像的角度进行评价,第二部分对相同prompt产生的图像进行排序。
Stage1: 文-图评级
第一步,准备标注。通过收集和过滤 prompts ,生成具有多样性和代表性的图像数据集。
第二步,标注。它包括两个步骤:1. 从三个维度对图像进行进行评分;2. 从整体角度比较图像并进行排名。
第三步,人类偏好的学习和推理,通过训练 ImageReward 学习图像标注,使其具有分析哪一张图片更容易获得人类偏好的能力。
Prompt选择与图片收集
作者从一个包含了数以百计的 prompts 和 Stable Diffusion 对应生成图像的开源数据集 DiffusionDB 中进行数据的收集与筛选。
为了保证 prompt 分布的多样性,使其涵盖表征用户的真实使用需求,采用了一个根据 prompt 相似度(通过语言模型 Sentence-BERT 产生)的基于图的选择算法,构造一个基于kNN的 1.8M DiffusionDB prompts的相似度图迭代选择top-degree prompts,每轮之后降低被选择的prompts的相邻边的权重。对于每个prompt,从DiffusionDB中选择对应的4-9张采样图片供接下来的标注过程,共产生了177304候选对。
主观标注
人类标注主要分成两个部分,第一部分从单张生成图像的角度进行评价,第二部分对相同prompt产生的图像进行排序。
Stage1: 文-图评级
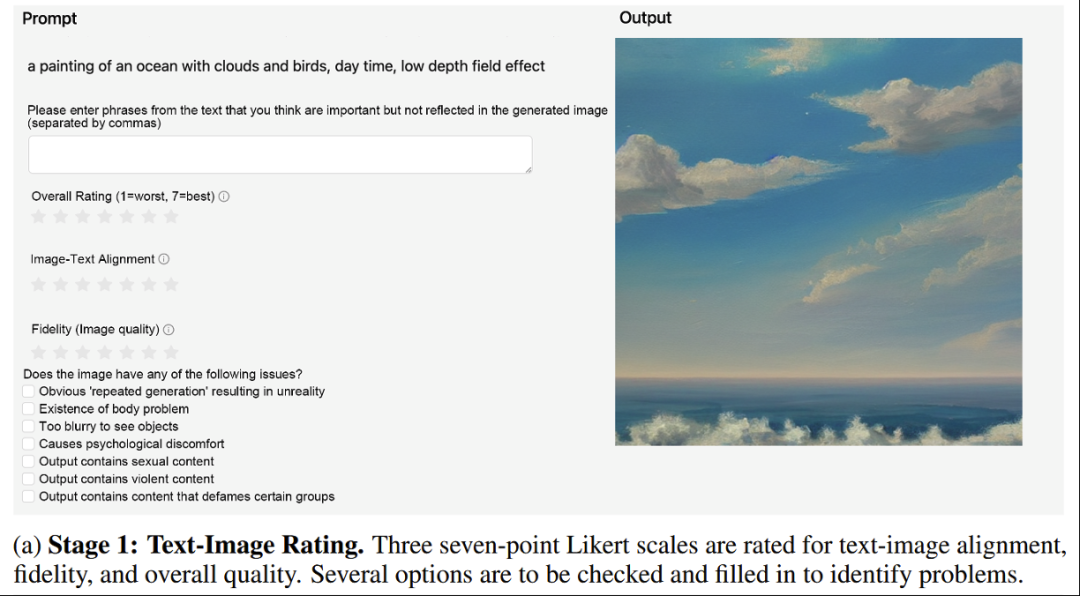
这个评价阶段从整体来看,考虑了以下三个衡量标准:文图对齐、保真度、无害性
- 文图对齐:要求生成的图像忠实地显示具有准确属性的准确对象,并且提示符中描述的对象与事件之间的关系是正确的。
- 保真度:关注图像的质量,特别是生成的图像中的对象是否真实,美观,并且图像本身没有错误。
- 无害性:意味着图片不应该有有害的,非法的,有偏见的内容,或者引起心理上的不适。
Stage2: 排序
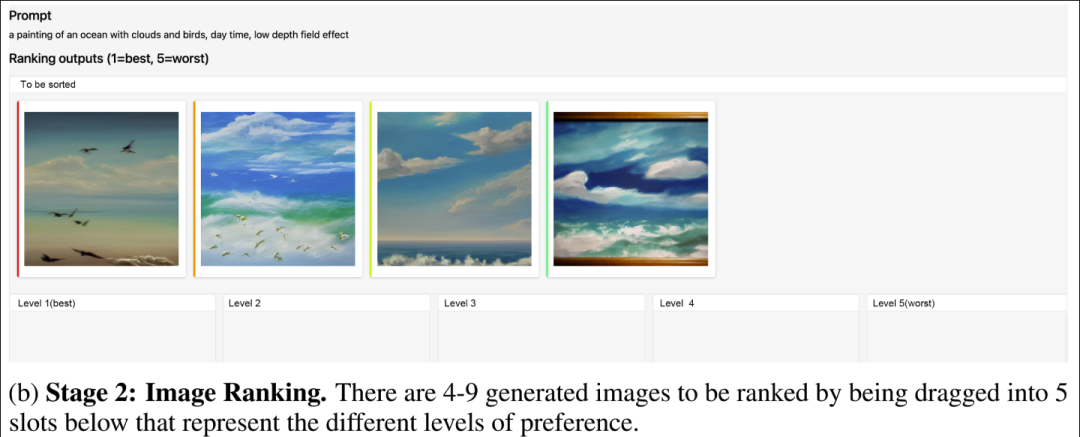
这一阶段主要对于相同 prompt 产生的图片进行排序:有 5 个槽位可以填充,第一个槽位对应图像中最好的一张,最后一个槽位对应最差的一张。当两张图像难以区分哪一张更好时,允许出现平局,但一个插槽最多允许两张图像以强制区分不同的质量。
训练

使用 BLIP 作为 ImageReward 的backbone,提取图像和文本特征,用交叉注意力相结合,然后使用 MLP 生成一个偏好比较的标量。(在预实验中,BLIP 优于CLIP ,因而选BLIP)
在训练期间发现,快速收敛和过度拟合会损害人类偏好预测能力。为了解决这个问题,冻结了一些backbone Transformer的参数,且固定层的数量会影响 ImageReward 的性能。除此之外,ImageReward 还表现出对训练超参数的敏感性,例如学习率和 batchsize 大小,因而基于验证集仔细搜索了最佳值。
实验结果
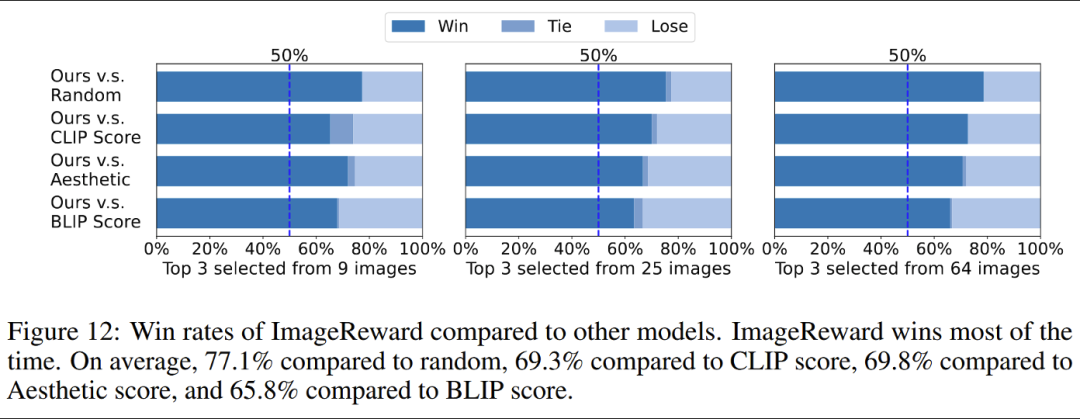
总结
本文设计了一个系统级标注文生图质量的pipeline,涵盖多角度评级和排名,收集了一个包含 137k 经过专业比较的数据集,建立了文生图质量评价和人类标注训练的标准。
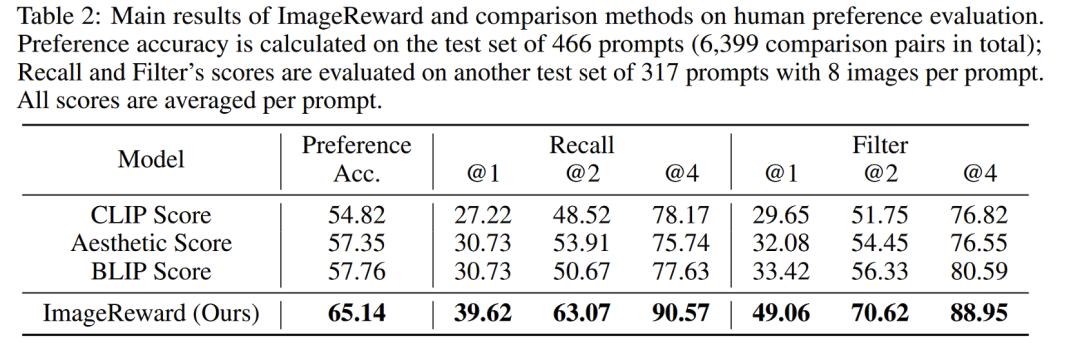
本文还提出了第一个通用的文生图人类偏好奖励模型,对齐人类价值喜好。在人类评估中,ImageReward 比现存打分方法更好(比CLIP好38.6%),使其有希望成为评估和改进文生图像的自动评价指标。
文中还对人类主观标注结果进行了分析,包括 prompt 中 func word 的影响等,也是非常有趣的。
作者:Jiazheng Xu,Xiao Liu 等
论文题目:ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation
论文链接:https://arxiv.org/pdf/2304.05977.pdf
内容整理:贾荣立、柴歆宁
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。