
通用的图像补全旨在通过借用周围的信息来填充损坏的图像,这几乎不会产生新颖的内容。相比之下,多模态的图像补全为需要填补的内容提供了更灵活和有用的控制,例如,文本提示可以用来描述具有更丰富属性的对象,掩码可以用来约束修复对象的形状,而不仅仅被视为缺失区域。本文提出了一种新的基于扩散的模型,名为SmartBrush,使用文本和形状引导补全缺失区域。为了更好地保留背景,本文提出了一种新的训练和采样策略,通过目标掩模预测来增强扩散 U-net,并引入了一种多任务训练策略,通过将修复与文本到图像的生成联合训练来利用更多的训练数据。
论文题目:SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model
来源:CVPR 2023
作者:Shaoan Xie, Zhifei Zhang, Zhe Lin, Tobias Hinz, and Kun Zhang
内容整理:刘希贝
引言
传统的图像补全的做法是,以周围的像素为依据填补图像的缺失区域,这样会导致缺乏对补全内容的控制。为了解决这个问题,多模态图像补全(multi-modal image inpainting)通过附加信息来提供更多的控制要素,例如类标签、文本描述、分割图等。在本文中,我们考虑了以文本描述和待绘制对象的形状为条件的多模态对象补全任务。
扩散模型(Diffusion models, DMs)在文本到图像的生成方面显示出强大的能力。将它应用于补全任务时,需要在扩散反向过程中,将背景区域的随机噪声替换为原始图像的带噪版本。然而,现存的Diffusion-based Inpainting Model存在如下问题:
- Text misalignment: 由于训练过程中的text prompt是针对全局图片的,缺失的区域(局部内容)与全局文本描述之间的语义不一致可能会导致模型用背景内容填充mask的区域,而不是精确地按照文本提示进行填充(如下图中GLIDE和Stable Diffusion模型,会把火烈鸟生成到背景部分);
- Mask misalignment: 结合多模态language-vision的模型倾向于捕获全局和高级图像特征,因此不会在给定的mask形状内生成内容(如下图中的Blended diffusion模型);
- background preservation: 会在补全的物体周围产生扭曲的背景(下图中的第二行)


为了解决上述问题,我们在输入masks中引入了一个精度因子,即我们的模型不仅将mask作为输入,还将所绘制的对象应遵循mask形状的准确程度的信息作为输入。为了实现这一点,我们通过将高斯模糊应用于精确的实例掩码来生成从精细到粗略的不同类型的掩码,并使用掩码及其精度类型来训练引导扩散模型。通过这种设置,我们允许用户使用粗略的mask,它将在mask中的某个位置包含所需的对象,或者提供精确勾勒对象形状的详细的mask。因此,我们可以提供非常精确的mask,模型将用文本提示所描述的对象填充整个mask(见上图中的第一行),而另一方面,我们也可以提供非常粗略的mask(例如边界框),此时模型可以自由地在mask区域内插入所需的对象。
一个重要的特性是,尤其是对于边界框等粗略的mask,我们希望保持补全区域内的背景与原始图像一致。为了实现这一点,我们不仅使模型修复mask区域,而且还利用正则化损失来使模型预测它正在生成的对象的实例掩码。在测试时,我们将粗掩膜用采样过程中得到的精确的掩膜代替,从而能够尽可能地保留背景。
总结来说,本文的贡献点有:
- 引入了一种基于扩散模型的文本和形状引导的目标补全模型,该模型能够对mask的精度进行控制,使模型对于不同精度的mask敏感;
- 为了保留粗mask输入时的图像背景,训练模型在补全过程中预测一个前景mask,以保留合成对象周围的原始背景;
- 没有使用描述整个图像的随机mask和文本标题进行训练,而是使用实例分割mask以及对应局部区域的文本描述来训练模型;
- 提出了一种多任务训练策略,同时训练object inpainting任务和text-to-image generation任务来利用更多的训练数据。
方法
扩散模型

形状精度控制
我们训练用的mask来自于分割数据集,因此都是一些精确的实例masks。使用这些masks将使模型在测试时更倾向于生成与输入mask形状完全一致的物体。为了允许用户能够提供精确的(如猫的形状)或粗略的(如边界框)的mask,我们提出以不同的精度生成mask。具体来说,我们利用了mask精度指示器s ~ [0,S],并为每个指示器定义了一系列参数:
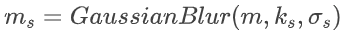
其中ks表示高斯核的大小,σs是高斯核的标准差。如果 s = 0,则mask保持不变,保持为数据集注释中的精准的实例掩码。当s = S,那么掩码ms则是实例掩码m的一个边界框(bounding box),丢失了所有细节的形状信息。在训练过程中,对于每个训练物体,我们使用一组从细到粗的掩模模型{ms,s},对扩散模型添加精度指标s为条件:
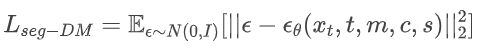
通过这种方式,我们可以通过指定不同的 掩码精度指标来控制生成的对象是否应该与输入掩码对齐。下图是一些mask的示例。

背景保留
在推理过程中,扩散模型将对masked区域进行去噪,并根据给定的文本提示生成目标。因此,如果输入的mask是粗糙的,则会改变这部分区域的背景。例如,模型可能会在给定的正方形框掩码区域中生成一个猫,但正方形框区域中的其他像素也会发生变化。理想情况下,我们希望保留背景,但是我们不知道模型将在粗掩模的哪里生成所需的对象。
我们通过利用掩码精度信息来解决这一挑战。具体来说,在扩散模型中添加一个额外的输出通道,使其从输入的粗糙版本的ms中预测得到一个准确的实例掩码m:
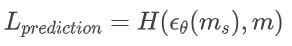
其中H可以是任何合适的分割标准。在此使用DICE loss:
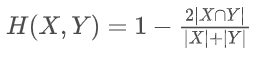
训练策略
结合上述两项损失函数,最终网络的优化目标为:
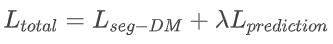
其中超参数λ设置为0.01。
网络整体结构如下图所示,我们在Stable Diffusion text-to-image v1.2模型的基础上进行微调。
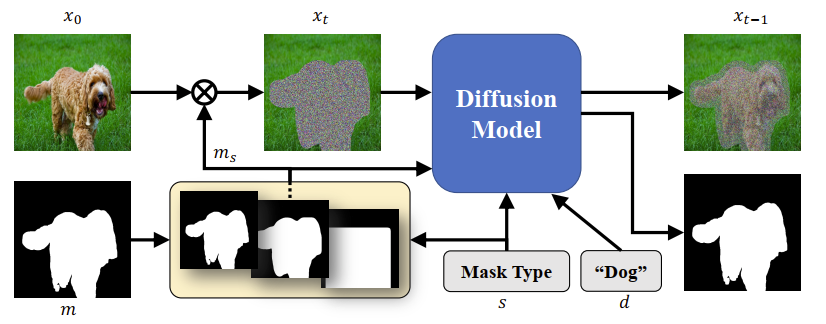
为了将文本描述与掩码内容对齐,避免前面提到的文本不对齐的问题,我们使用OpenImages v6的训练集进行训练,其中含有分割图和相应的标签。然而,实验发现,这种分类文本会降低长句子的生成质量。因此,我们采用BLIP模型为这些局部的分割图收集更丰富、更长的标签。在训练过程中,我们随机将分割自带的标签或BLIP生成的标签与相应的掩码配对。因此,模型在推理过程中可以很好地处理单字文本和短语。
此外,为了利用更多的训练数据,处理更多样化的文本描述和图像内容,在分割数据集之外,我们提出了一种多任务训练策略,通过联合训练我们的主要任务和基作为基础的文本到图像生成任务,使用延续Stable Diffusion的 LAION-Aesthetics v2 5+子集的图像/文本配对数据。对于文本到图像生成任务,我们将输入掩码设置为覆盖整个图像,将其视为一种特殊的补全情况。
实验
在训练时,batch size设置为1024,分别以80%和20%的概率训练补全任务和文本到图像生成任务。我们的模型在8个 A100 GPU上训练了大约20K步。作为参考,Stable Inpainting需要在256个 A100 GPU上训练大约440K步。
实验结果
本文提出的SmartBrush不仅可以绘制对象,还可以通过遵循文本和形状指导来绘制日落天空等一般场景。对于对象绘制,我们考虑两个常见用例:1)精确的对象掩膜和2)边界框掩膜。前者期望生成的对象遵循给定的掩膜形状,而后者不约束生成对象的形状,只要它们在框内即可。相应的定量结果如下面两个表格所示。
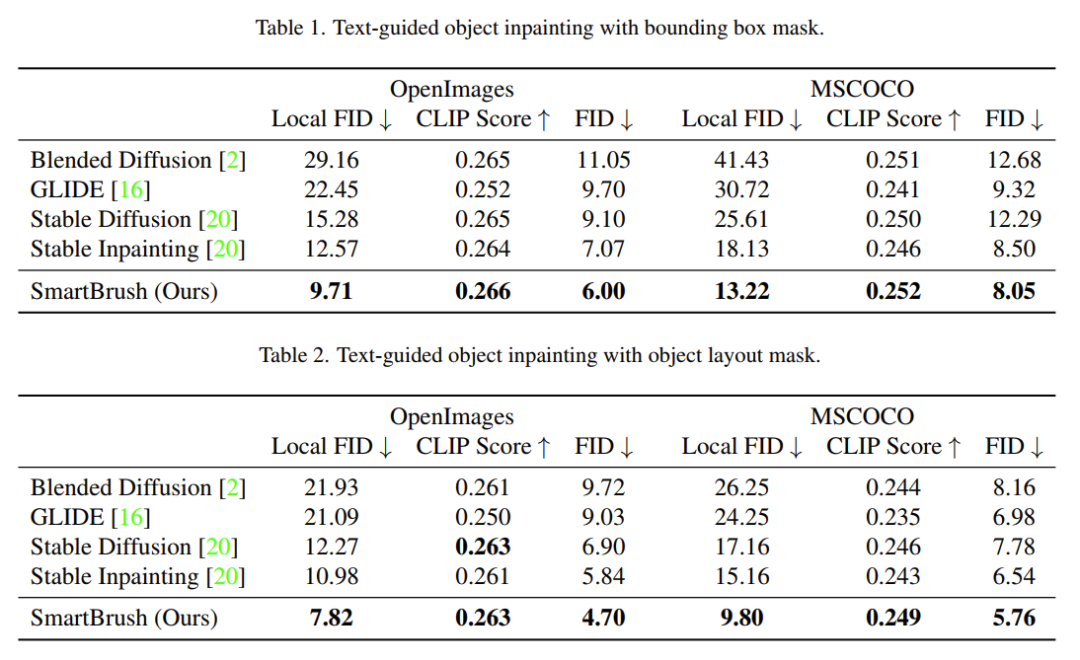
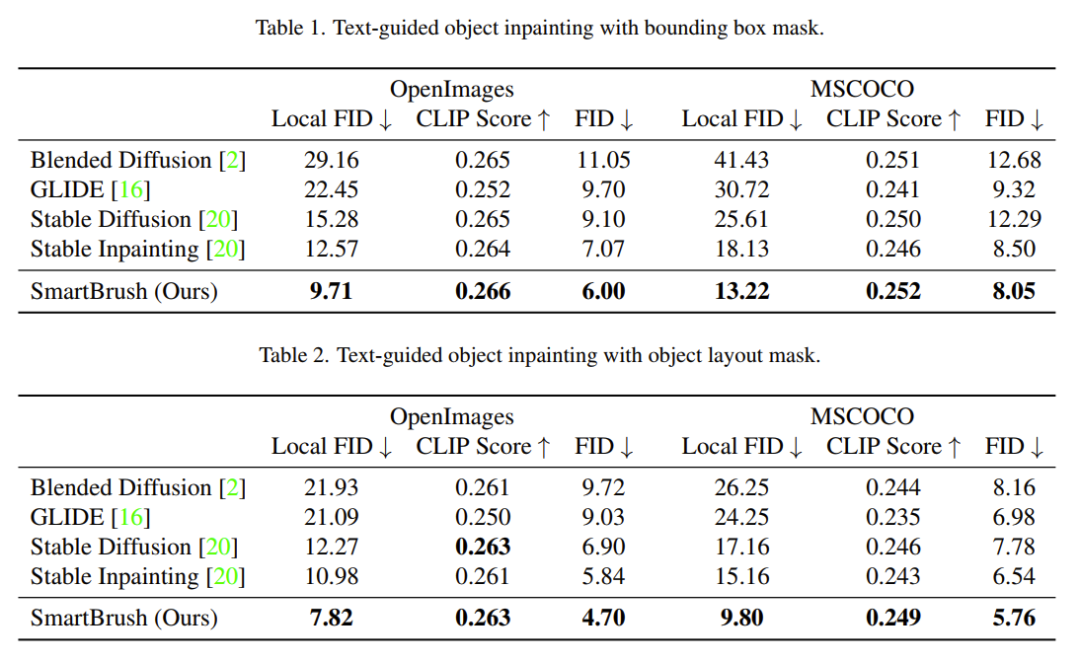
由于我们的主要任务是在被遮挡区域生成对象,因此 全局FID不能很好地反映生成的质量,因为被遮挡的区域可能只占了图像中的一小部分。因此,我们根据掩模的边框 对图像进行裁剪,并测量局部区域上的FID, 称为“local FID”。为了衡量文本与生成内容之间的一致性,采用CLIP指标进行评分。
可以看到我们的方法比Stable Inpainting获得了更高的CLIP值,这表明随机mask不是文本引导的Inpainting任务的最佳训练策略。Blended Diffusion获得了相对较高的CLIP分数,它的FID值较差,这是因为CLIP模型仅仅关注全局内容而不是局部对象。相比之下,我们的SmartBrush在所有指标上都获得了最佳性能,这证明了我们提出的文本和形状指导训练策略的有效性。

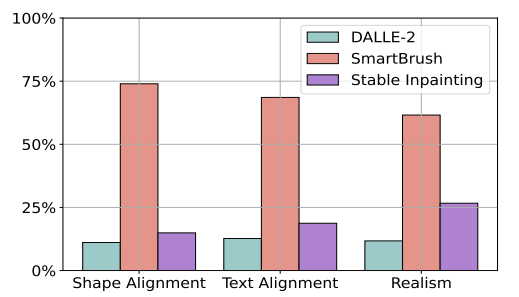
上图展示了我们的方法与其他相关方法的一些结果图。总的来说,SmartBrush可以根据mask形状和文本生成高质量的对象/场景,无论是短单词还是长句子。相比之下,所有的对比方法在遵循mask形状方面都失败了。即使在给定这些局部文本描述的情况下,Blended Diffusion和GLIDE也无法生成像样的对象。Stable Diffusion、Stable Inpainting和DALLE-2可能略好一点,但是由于文本不对齐而导致文本误解的可能性很高。用户调研结果如下图所示:
掩膜精度控制
在现实世界中,用户并不能总是提供他们想要绘制的对象的精确掩模。下图展示了不同类型的mask所得到的不同结果。其中Stable Diffusion的结果基本不受掩模类型的影响。Stable Inpainting的结果仅随mask大小而改变对象大小,但不遵循mask的形状。相比之下,当提供更精细的掩模时,我们的结果严格遵循掩模形状,而如果提供粗糙的掩模,则大致遵循掩模形状。对于极端情况,给定一个类似盒子的掩膜(最后一列),我们允许在盒子内的任何地方生成相应的物体。

背景保留
要绘制一个对象,特别是当给出一个框状掩膜时,背景保留是非常重要的,因为被绘制的对象只会占据掩膜中的部分区域。下图展示了当给出框状掩膜时不同方法在背景保留方面的对比。在没有任何背景保留正则化约束的情况下,DALLE-2在掩膜内生成对象的同时改变了其中的非对象像素。SmartBrush具有对象掩膜预测,可以在采样期间通过利用预测的掩膜更好地保留背景信息。

总结
现有的文本和形状引导的图像补全模型面临着三个典型挑战:mask不对齐、文本不对齐和背景保留。本文提出了一个新的训练方法,利用分割数据集中的文本和形状来解决文本不对齐问题。然后进一步提出创建不同级别的掩模(从细到粗)来允许控制生成物体对齐的精确程度。最后,提出了一个额外的训练损失函数,以鼓励模型根据输入框掩膜进行对象预测,然后便可以利用预测的掩膜来避免内部不必要的变化。定量和定性结果证明了该方法的优越性。
该方法的主要限制是在有大片阴影的情况下,物体的阴影超过了物体的mask,例如,一个人的影子在早上可能很长,而边界框通常不能覆盖整个阴影。我们的方法可能无法生成这么长的阴影,因为最粗的mask是对象边界框。我们将在不久的将来探索这个问题的解决。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。