
潜在扩散模型 (LDM) 可实现高质量图像合成,同时通过在压缩的低维潜在空间中训练扩散模型来减少计算量。将 LDM 应用于高分辨率视频生成是一项特别耗费资源的任务。本文首先仅在图像上预训练 LDM;然后,通过将时间维度引入潜在空间扩散模型并对编码图像序列(即视频)进行微调,将图像生成器转变为视频生成器。在时间上对齐扩散模型上采样器,将它们变成时间一致的视频超分辨率模型。本文专注于两个相关的实际应用:使用文本到视频建模模拟野外驾驶数据和创意内容创建。特别是,在分辨率为 512 x 1024 的真实驾驶视频上验证视频 LDM实现了最先进的性能。此外,本方法可以轻松利用现成的预训练图像 LDM,因为在这种情况下只需要训练时间对齐模型。本文将公开可用的、最先进的文本到图像 LDM 稳定扩散转变为分辨率高达 1280 x 2048 的高效且富有表现力的文本到视频模型。实验表明,时间层经过训练以这种方式推广到不同的微调文本到图像 LDM。利用此属性,展示了个性化文本到视频生成的第一个结果,为未来的内容创建开辟了令人兴奋的方向。
来源:CVPR 2023
作者:Andreas Blattmann, Robin Rombach等
论文链接:https://research.nvidia.com/labs/toronto-ai/VideoLDM/
内容整理:王寒
原文:https://mp.weixin.qq.com/s/gg08X3M6txKVa2OACcWqLw
引言
本文提出了用于计算高效高分辨率视频生成的视频潜在扩散模型(Video LDM)。为了减轻高分辨率视频合成的密集计算和内存需求,利用 LDM 并将其扩展到视频生成。视频 LDM 将视频映射到压缩的潜在空间,并对与视频帧对应的潜在变量序列进行建模。从图像 LDM 初始化模型,并将时间层插入 LDM 的去噪神经网络,以对编码的视频帧序列进行时间建模。时间层基于时间注意力和 3D 卷积。此外,还微调了模型的视频生成解码器。
视频潜在扩散模型
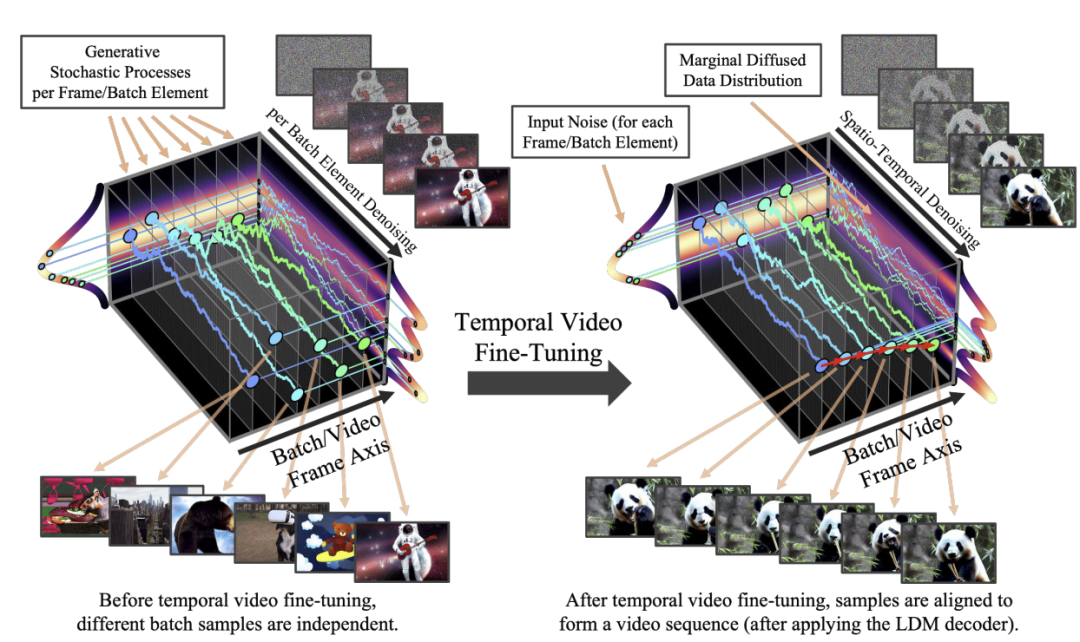

本文将预先训练的图像扩散模型转换为时间一致的视频生成器。最初,由模型合成的批次的不同样本是独立的。在时间视频微调之后,样本在时间上对齐并形成连贯的视频。微调前后的随机生成过程可视化为一维toy分布的扩散模型。为清楚起见,上图对应于像素空间中的对齐。在实践中,我们在 LDM 的潜在空间中执行对齐并在应用 LDM 的解码器后获得视频。
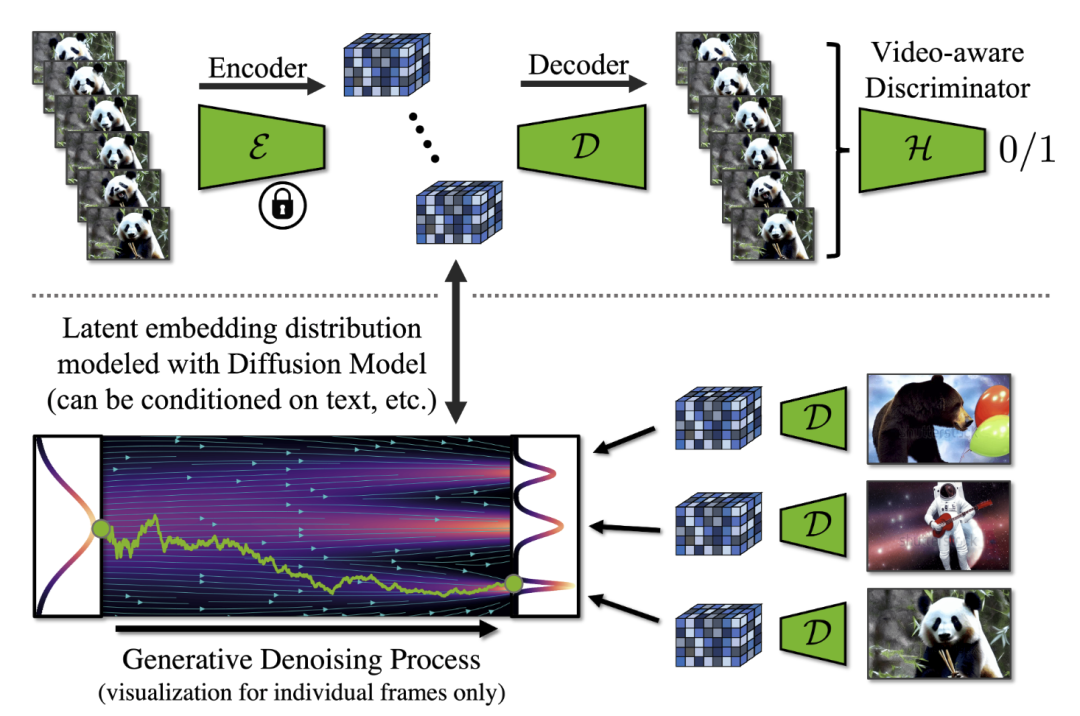
上图是对潜在扩散模型框架和解码器的视频微调。图片上部分:在时间解码器微调期间,使用冻结的每帧编码器处理视频序列,并强制跨帧进行时间相干重建。还使用了一个视频感知鉴别器。图片下部:在 LDM 中,扩散模型在潜在空间中进行训练。它合成潜在特征,然后通过解码器将其转换为图像。请注意,在实践中,对整个视频进行建模,并对潜在扩散模型进行视频微调以生成时间一致的帧序列。
视频 LDM 最初以低帧率生成稀疏关键帧,然后通过另一个插值潜在扩散模型在时间上对其进行两次上采样。此外,可选地通过对起始帧进行调节来训练视频 LDM 进行视频预测,使其能够以自回归方式生成长视频。为了实现高分辨率生成,进一步利用空间扩散模型上采样器并在时间上对齐它们以进行视频上采样。整个生成堆栈如下所示。
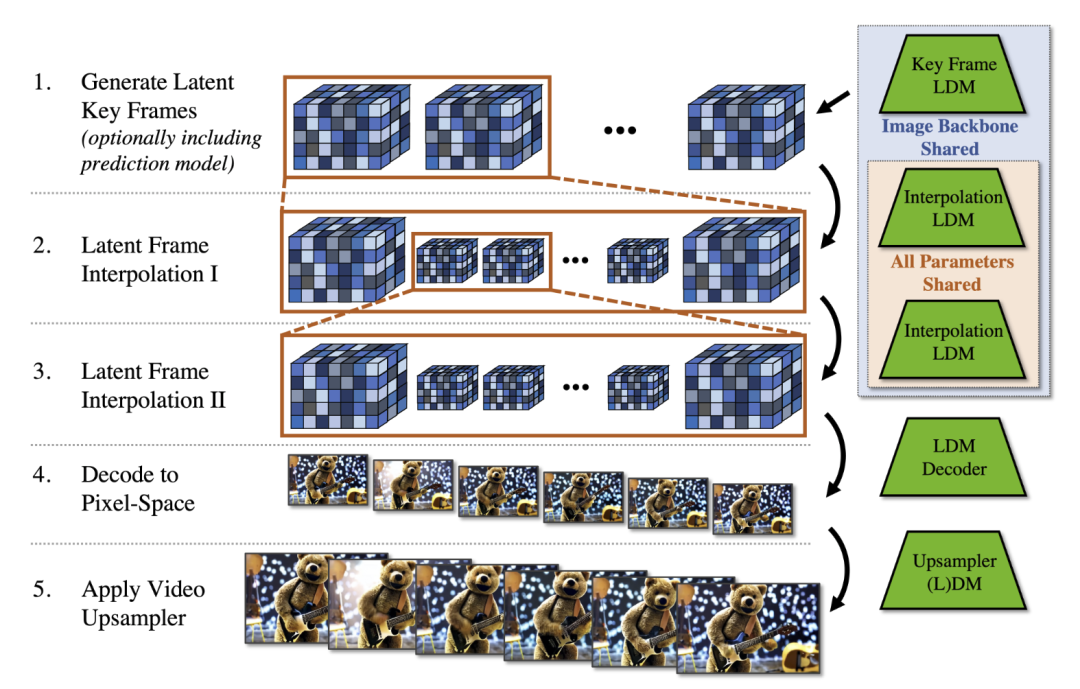
首先生成稀疏关键帧。然后使用相同的插值模型分两步进行时间插值以实现高帧率。这些操作使用共享相同图像主干的潜在扩散模型 (LDM)。最后,将潜在视频解码到像素空间,并可选地应用视频上采样器扩散模型。
文本到视频合成
生成的视频分辨率为 1280 x 2048 像素,由 113 帧组成,以 24 fps 的速度呈现,产生 4.7 秒长的剪辑。本文用于文本到视频生成的 Video LDM 基于 Stable Diffusion,共有 4.1B 个参数,包括除 CLIP 文本编码器之外的所有组件。这些参数中只有 2.7B 是在视频上训练的。这意味着本模型比几个并行工作的模型小得多。还可以制作高分辨率、时间一致且多样化的视频。这可以归因于高效的 LDM 方法。
个性化视频生成。 将之前为本文视频 LDM 训练的用于文本到视频合成的时间层插入到图像 LDM 主干中,图像 LDM 主干预先在DreamBooth生成的的一组图像上进行过微调。时间层泛化到 DreamBooth checkpoints,从而实现个性化的文本到视频生成。
时间卷积合成。 本文还探索了通过学习到的时间层来“自由”合成稍长的视频。
驾驶场景视频生成
本文还在野外真实驾驶场景视频上训练视频 LDM,并生成 512 x 1024 分辨率的视频。在这里,本文另外训练预测模型以生成长视频,从而能够生成几分钟长的时间连贯视频。
特定驾驶场景模拟。 在实践中可能对模拟特定场景感兴趣。为此,本文训练了一个边界框条件的纯图像 LDM。利用这个模型,可以放置边界框来构建感兴趣的设置,合成相应的起始帧,然后从设计的场景开始生成合理的视频。
多模式驾驶方案预测。 作为另一个潜在相关的应用程序,可以采用相同的启动帧并生成多个合理的结果。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。