
Lyra是一种基于机器学习的语音编解码器,通过引入预测方差正则化来降低对异常值的敏感性,从而提高性能。Lyra使用自回归模型WaveNet进行过程建模,并通过输入噪声抑制来显着提高性能。Lyra的实验表明其质量与双倍速率运行的传统编解码器相似或更好,并且适用于低速率视频通话和消费类设备。Lyra基于波形编码和机器学习技术,具有以下特点:
- 低比特率高质量:Lyra专门设计用于处理极低比特率的音频信号,例如3kbps,而在这样的比特率下,传统的编码器通常不能提供满意的音质。
- 机器学习驱动:Lyra的设计主要依赖于机器学习模型,这些模型经过大量的训练数据训练,可以有效地学习到音频信号的模式,并在编码和解码时复现这些模式。
- 适用于实时通信:Lyra的设计初衷是用于实时的音频通信,如VoIP(Voice over IP)等,它的延迟很低,能够在网络条件差的情况下提供良好的音频质量。
- 开源:Lyra是一个完全开源的项目,开发者可以自由地使用和修改其代码。
来源:arxiv
题目:SoundStream: An End-to-End Neural Audio Codec
作者:Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, Marco Tagliasacchi Runway等人
文章地址:https://arxiv.org/pdf/2107.03312.pdf
内容整理:胡玥麟
简介
音频编解码器分为波形编解码器和参数编解码器。波形编解码器旨在对输入音频样本进行精确重建,而参数编解码器通过模型参数提高编码效率。波形编解码器通常对音频类型没有假设,适用于各种音频,但在低比特率下可能引入伪像。参数编解码器通过对音频特征的假设以及具有强先验的参数模型,以实现高效编码。
感知模型控制波形编解码器的比特分配和量化过程。机器学习模型应用于音频压缩领域,优化波形编解码器的质量。例如,通过音频超分辨率、噪声去除或数据包丢失隐藏来提高音频质量。另外,基于机器学习的音频编解码器(如神经音频编解码器)应用于低比特率语音。
本文主要介绍了一种新型音频编解码器——SoundStream,实现了更高效的音频压缩。SoundStream采用了神经音频合成领域的最先进技术,并引入了新的可学习量化模块。全卷积编码器接收时域波形作为输入,生成较低采样率的嵌入,随后全卷积解码器重建原始波形。而Lyra就是基于一种名为SoundStream的新型音频编解码器(以下统称为音流),可以比以往的编解码器更有效地压缩语音、音乐和一般音频。
SoundStream通过端到端训练实现,使用因果卷积。全模型架构延迟取决于原始时域波形与嵌入之间的时间重采样率。总结来说,本文主要贡献包括:
- 提出了端到端训练的神经音频编解码器SoundStream,结合了重建和对抗性损失,实现出色的音频质量。
- 引入了新的残差矢量量化器和训练技术,“量化器丢失”,以处理不同比特率。
- 证明相对于梅尔谱图特征,学习编码器可以显著提高编码效率。
- 通过主观质量指标证明SoundStream在广泛比特率范围内优于Opus和EVS。
- 设计支持低延迟流式推理的模型,可在单个CPU线程上实时运行。
- 提出了一种联合执行音频压缩和增强的SoundStream编解码器变体,无需额外延迟。
Lyra中所使用的音流SoundStream技术
音流利用了神经音频合成领域的最新解决方案,并引入了一个可学习的量化模块,以在低到中比特率下提供高感知质量的音频。下图显示了编解码器的高级模型架构。完全卷积编码器接收时间域波形作为输入,并以较低的采样率生成嵌入序列,其中,一个或多个判别器被联合训练,目的是区分解码的音频和原始音频,并提供一个基于特征的重构误差的计算空间。编码器和解码器都仅使用因果卷积,因此模型的总体架构延迟仅由原始时间域波形和嵌入之间的时间重采样比率确定。
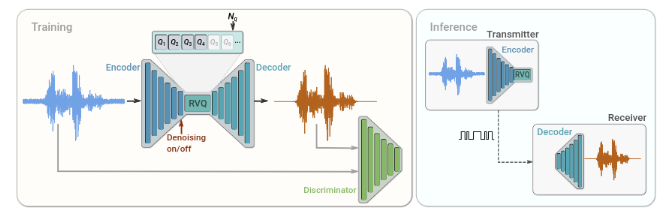

音流考虑一个单声道录音x ∈ RT,采样率为 fs。音流模型由三个构建块组成,如上图所示:
- 编码器将x映射为一系列嵌入向量;
- 残差向量量化器用来将每个嵌入向量替换为一组来自有限码本的向量之和,从而将表示压缩为目标比特数;
- 解码器从量化后的嵌入向量中产生有损重构x ∈ RT。该模型与一个判别器一起端到端训练,使用对抗训练和重构损失的混合。可选地,可以添加一个调制信号,
编码器架构
编码器架与流式SEANet编码器具有相同的结构,但没有跳跃连接。它由一维卷积层(具有C_enc个通道)和 B_enc 个卷积块组成。每个块都包含三个残差单元,分别包含扩张率为1、3和9的扩张卷积,然后是一个下采样层,采用步幅卷积的形式。每次下采样时通道数翻倍,从C_enc开始。最后,使用长度为3且步长为1的一维卷积层将嵌入向量的维度设置为D。为了保证实时推断,所有卷积都是因果的。这意味着在训练和离线推断中,填充仅应用于过去而不是未来,而在流式推断中不使用填充。音流使用ELU激活函数],并不应用任何归一化。卷积块数B_enc和相应的步幅序列决定了输入波形和嵌入向量之间的时间重采样比率。例如,当 B_enc = 4 并使用(2,4,5,8)作为步幅时,每320个输入样本计算一个嵌入向量。因此,编码器输出enc(x) ∈ RS x D,其中 S = T/M,M = 245 * 8 =320。
解码器架构
解码器架构遵循类似的设计,如下图所示。一个一维卷积层后面是一系列 B_dec 个卷积块。解码器块镜像了编码器块,由一个转置卷积进行上采样,然后是同样的三个残差单元。音流的步幅与编码器相同,但顺序相反,以便重构波形具有与输入波形相同的分辨率。每次上采样时,通道数减少一半,以便最后一个解码器块输出个C_dec 通道。最后,一个具有一个滤波器、大小为7的核和步长为1的一维卷积层将嵌入向量投影回波形域,以产生重构的x_hat。
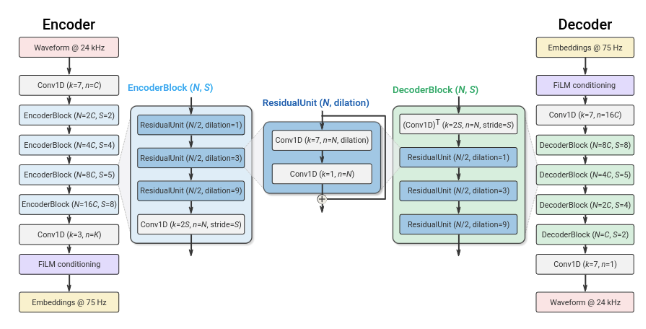
残差矢量量化器(Residual Vector Quantizer)
残差矢量量化器(RVQ)由Nq层矢量量化器(VQ)级联而成,可以灵活控制比特率。RVQ首先使用VQ对输入矢量进行量化,然后迭代量化量化残差。总比特率预算在每个VQ之间均匀分配。Nq控制VQ的层数,从而在计算复杂性和编码效率之间进行权衡。增加Nq可以减少每个VQ的词典大小,降低计算复杂性,但会产生更多量化误差,降低编码效率。
判别器
Lyra有两种基于波形和基于短时傅立叶变换(STFT)的判别器。由于两个判别器都是全卷积的,输出中的logit数与输入音频长度成比例。
基于波形的判别器采用多分辨率卷积判别器。三个结构相同的模型以不同分辨率应用于输入音频:原分辨率、2倍下采样和4倍下采样。每个单分辨率判别器由初始普通卷积开始,后跟四组组卷积,每组组大小为4,下采样因子为4,通道乘数最高为1024个输出通道。然后跟着另外两个普通卷积层产生最终输出,即logit。
基于STFT的判别器在单个尺度上操作,使用窗口长度W = 1024个样本和跨度H = 256个样本计算STFT。2D卷积(核大小7×7,32个通道)后跟一系列残差块。每个块以3×3卷积开始,后跟3×4或4×4卷积,步幅为(1,2)或(2,2)。通过在(1,2)和(2,2)步幅之间进行交替,总共6个残差块。通道数随网络深度逐渐增加。在最后一个残差块的输出,激活具有形状T/(H·23)×F/26,其中T表示时间域中的样本数,F = W/2表示频率bin的数目。最后一层通过1×F/26卷积(实现为全连接层)聚合不同频率bin的logit,以在(下采样的)时间域中获得1维信号。
通过使用多分辨率和多域判别器,本文的判别器设计旨在区分各种音频表示,包括原始波形、STFT和编码器输出。多分辨率和多域结构有助于判别器学习更丰富的audio embedding空间的内部表示。
本文采用的判别器设计旨在有效地推动生成器学习产生更逼真的音频表示,这有助于训练出高质量的神经语音编码器。
音流 Sound Stream 的效果
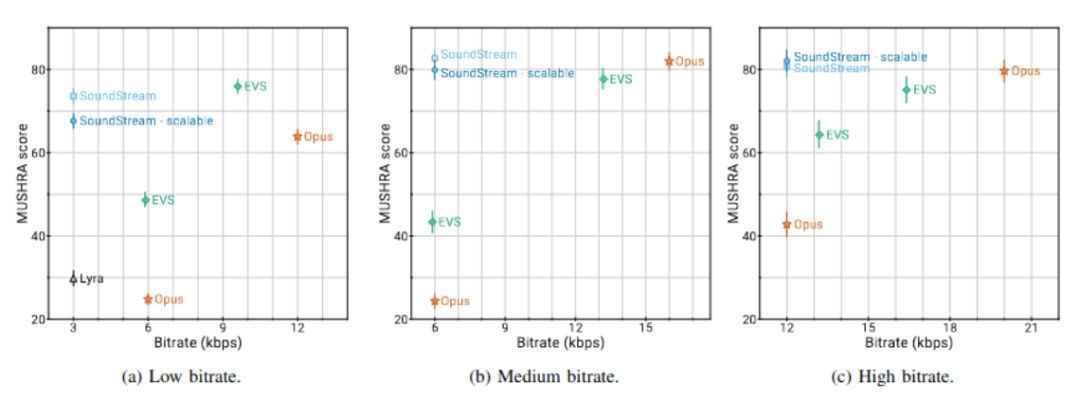
上图比较了不同比特率下的SoundStream、Opus和EVS。该比较具体重复进行了一项主观评估,该评估基于MUSHRA启发的众包方案,当音流以三种不同比特率操作时:
- 低(3kbps);
- 中(6kbps);
- 高(12kbps)。
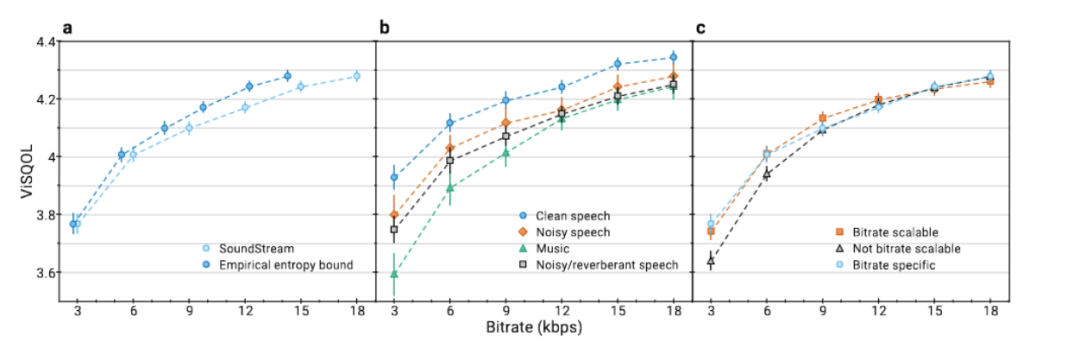
上图a显示,尽管使用一半比特率,但3kbps下的音流明显优于6kbps下的Opus和5.9kbps下的EVS(即这些编解码器可以操作的最低比特率)。要达到音流的质量,EVS至少需要9.6kbps,Opus至少需要12kbps,即比音流多3.2倍到4倍比特。当音流和Lyra均以3kbps操作时,音流优于Lyra。当音流以6kbps和12kbps操作时,是类似的结果。在中等比特率下,EVS和Opus分别需要2.2倍到2.6倍的比特来达到同样的质量。在高比特率下,需要1.3倍到1.6倍的比特。
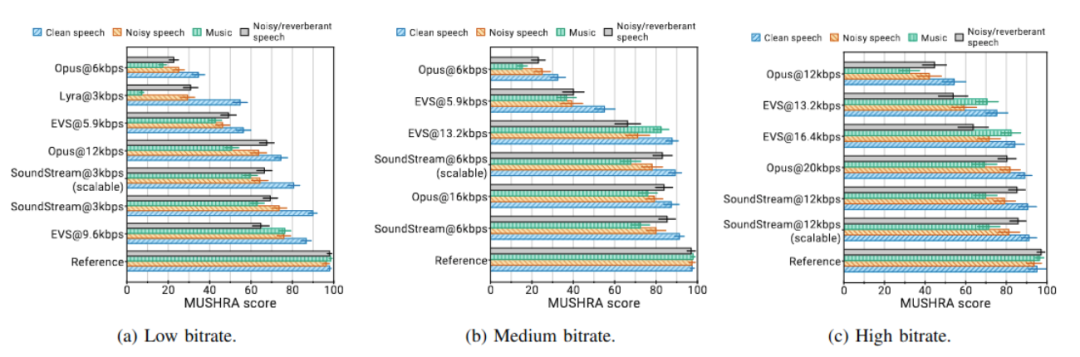
下图说明了主观评估的结果按内容类型。我们观察到,编码清晰语音和嘈杂语音时,音流的质量保持一致。此外,音流可以在使用仅3kbps时编码音乐,质量明显优于12kbps下的Opus和5.9kbps下的EVS。这是首次展示一个编解码器可以在如此低的比特率下操作各种内容类型。
下图a显示了音流在广泛比特率范围内的速率-质量曲线,从3kbps到18kbps。可以从图中观察到,以ViSQOL测量的质量随着比特率的降低而平稳下降,且即使在最低比特率下也保持在3.7以上。在测试中,音流以恒定比特率操作,即每个编码帧分配相同数量的比特。同时,通过计算矢量量化器的量化符号的经验熵来测量比特率下限,假设每个矢量量化器是一个离散无记忆源,即不同残差矢量量化器的层之间以及时间上没有利用统计冗余。下图a表示潜在的速率节省在7%到20%之间。
如下图b所示,该图展示了对不同内容类型进行编码时达到的速率-质量权衡。毫不奇怪,清晰语音的编码可达到最高质量。由于其固有的内容多样性,音乐代表了一种更具挑战性的情况。
Lyra的效果评析
为了评估不同信噪比下不同系统的绝对质量,研究进行了均值意见分数(MOS)听觉测试。除了数据收集之外,还要求遵循ITU-T P.800(ACR)建议。使用众包平台收集数据,要求听众为母语为英语并使用耳机。评估数据集由来自Noisy-VCTK数据集的30个样本组成:15个干净的和15个加了不同信噪比(2.5、7.5和12.5dB)的附加噪声。每个系统的每个话语被评分约200次,每个信噪比计算平均值和95%置信区间。
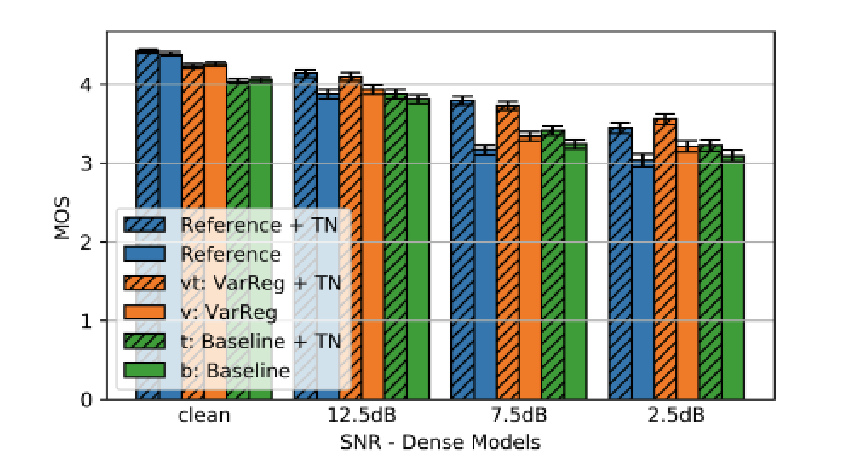
上图显示了预测方差正则化和降噪(TN)对质量的影响,不包括权重剪枝和量化。预测方差正则化显著提高了质量,并减少了输入信号中噪声的敏感性。当存在噪声时,降噪有助于提高性能。
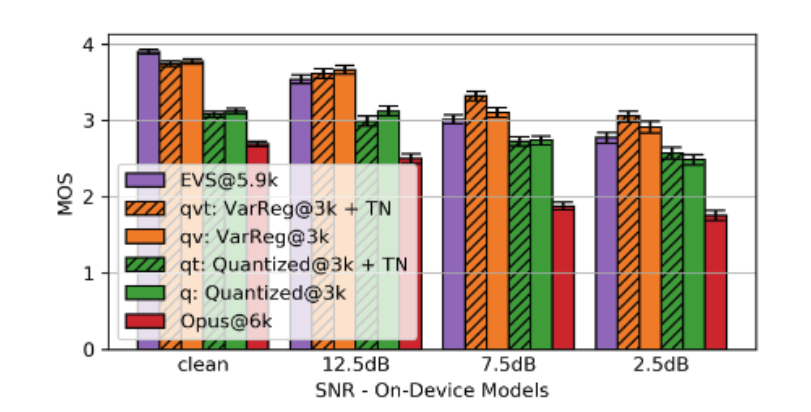
上图显示了被剪枝和量化的系统的质量。对于这种情况,由于干净信号,方差正则化的改进特别大。降噪的效果(TN)随着信噪比的变化而变化,这可能是噪声抑制和量化之间相互作用的结果。这可能与噪声抑制减少信号可变性和量化自身减少噪声有关。
结论
论文提出了 SoundStream,这是一种新颖的神经音频编解码器,在各种比特率和内容类型上都优于最先进的音频编解码器。SoundStream 由一个编码器、一个残差矢量量化器和一个解码器组成,它们使用对抗性和重建损失的混合进行端到端训练,以实现卓越的音频质量。该模型支持流式推理,可以在单个智能手机 CPU 上实时运行。当使用量化器丢失进行训练时,与比特率特定模型相比,单个 SoundStream 模型可实现比特率可扩展性,并且性能损失最小。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。