
VVC 作为最新的有损视频编码标准,一直受到视频编码界的关注。与其前身相比,该标准的压缩效率有了显著提高,然而,VVC 的增益是以显著的编码复杂度为代价:VVC 继承了早期标准中基于块的混合编码结构。在 VVC 中,输入视频帧被分成称为编码树单元 (CTU) 的块。CTU 由不同级别的编码单元 (CU) 组成,这些编码单元共享相同的预测风格(即帧内或帧间)。CU 分区过程是通过计算和比较所有分区的 RD 成本来实现的,这是一项非常耗时的任务。
到目前为止,在流行的视频编解码器(如 H.264/AVC 和 H.265/HEVC)上实现的高效 CU 分区方面已经做出了巨大的贡献。然而,由于编码结构的复杂变化,这些方法不能直接移植到新开发的 VVC 编解码器中。目前仍缺乏适合最新版本 VVC 的低复杂度编码算法。在现有的 VVC 算法中,低复杂度的帧内预测算法受到的关注较少。为了解决这个问题,本文提出了一个两阶段的框架。
来源:TMM 2022
论文题目:Efficient VVC Intra Prediction Based on Deep Feature Fusion and Probability Estimation
作者:Tiesong Zhao, Yuhang Huang, Weize Feng, Yiwen Xu and Sam Kwong
内容整理:王妍
提出的算法
VVC 的帧内预测包含两个步骤。首先,将 CTU 迭代分解为多个编码深度不同的 CU。其次,在每个编码深度中,对不同方向和模式的分区模式进行彻底检查,找出 RD 成本最小的分割模式。
因此,本文设计了一种两阶段复杂度优化策略:基于深度特征融合的帧内深度预测模型 (D-DFF) 确定最优深度,基于概率估计的分区模式预测模型 (P-PBE) 选择候选分区。最后利用所选择的深度和分区来加快 VVC 内编码中 CU 分区的速度。
基于深度特征融合的帧内深度预测
参考信息
VVC 与 HEVC 相比,采用了更大的 CTU 尺寸和深度。本文将 CTU 划分为 8×8 块,并尝试预测每个块的最佳深度(块大小 8×8 的选择是基于预测精度和编码复杂性之间的权衡)。因此,大小为 128×128 的 CTU 被划分为16×16块。
为了准确地预测最佳深度值,本文参考了时空相邻 CU 的深度信息。对于位于(x, y, t)的每个 8×8 块(其中 x, y, t 分别表示空间坐标和时间顺序),收集以下块的深度值:


D-DFF 网络结构
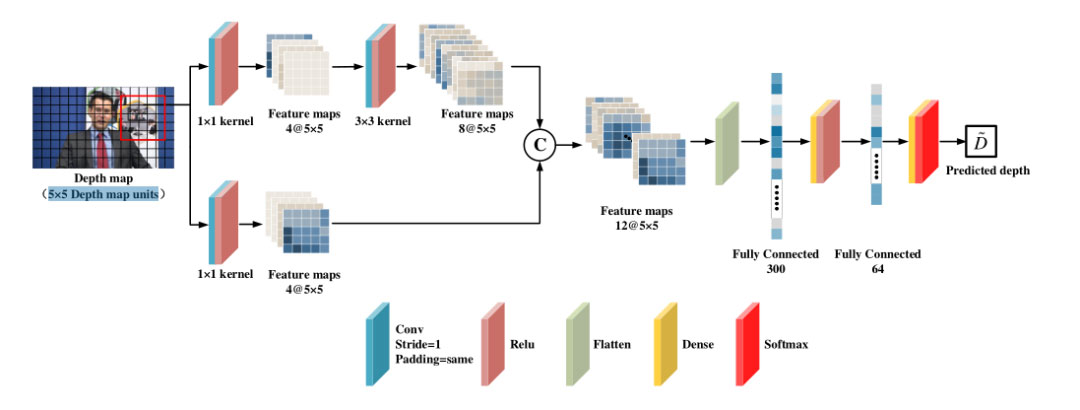
D-DFF 网络包括三个步骤:特征提取、特征拼接和分类。
D-DFF 网络包括三个步骤:特征提取、特征拼接和分类。
深度图特征提取有两条路径:一条是先利用 1×1 卷积核进行维度提升,然后用 3×3 卷积核结合 ReLU 进行尺度特征提取;另一个只使用 1×1 内核。这两条路径分别输出 8 个和 4 个 5×5 的特征映射。所有提取的特征输入到下一步进行特征融合。
特征拼接步骤将第一步的所有特征映射组合在一起,并将它们平展成一个向量。在这一步之后,12 张 5×5 特征图被拉伸成一个长度为 300 的向量。
最后,分类步骤接收特征向量并输出预测深度。使用具有 2 个隐藏层和一个 softmax 层的神经网络来完成该任务。由于帧内预测是在 CU 深度 1 或以上进行的,因此只有从 1 到 6 这 6 种输出深度。选择概率最大的深度值作为预测深度。
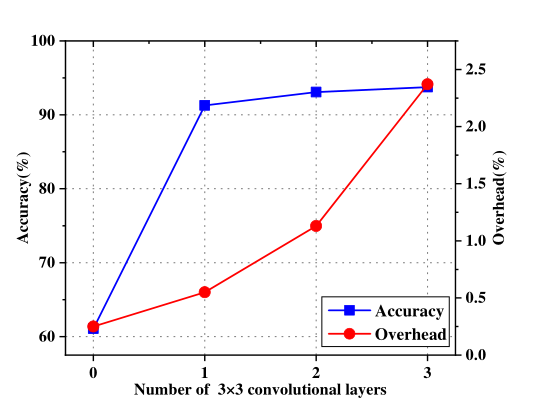
为了在模型精度和复杂性之间取得平衡,本文对该 D-DFF 模型的所有超参数进行了优化。该模型的一个重要设计是其双路径特征提取,以获得多尺度特征。在这一步中,最大卷积层数会影响模型的预测精度和计算开销。在上图中,给出了模型在不同 3×3 卷积层数下的平均精度和开销。可以看出,具有一个 3×3 卷积层的模型在模型精度和计算复杂度之间取得了很好的平衡。因此,本文在第一条路径中使用一个 1×1 和一个 3×3 卷积层。最大卷积层数为 2。
模型训练
本文从 LIVE 数据集、UVG 数据集和 AVS2/AVS3 的标准序列中收集了 58 个视频序列。这些序列覆盖了很大范围的分辨率,具有不同的帧率和位深度,还涵盖了广泛的空间信息 (SI) 和时间信息 (TI)。
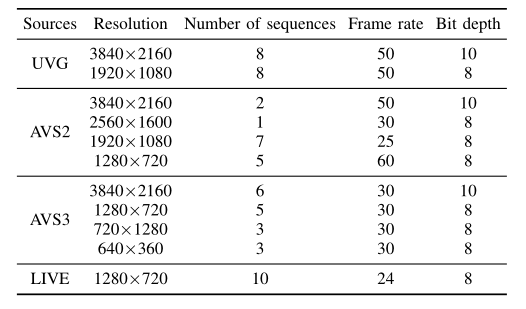
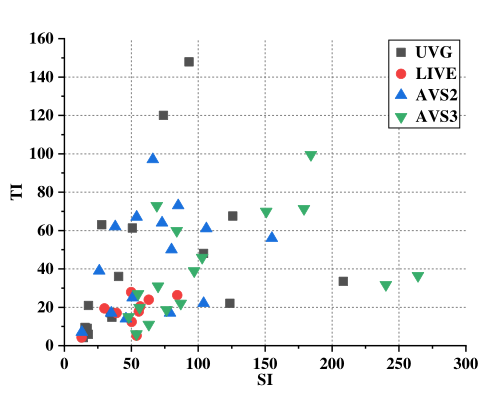
利用 VTM 12.0 对这些序列进行进一步压缩,量化参数 (Qps) 分别为 22、27、32 和 37。在压缩过程中,收集所有 CU 的深度值,并将其重组为预测深度和相应参考深度图对。这些数据对构成了一个大数据集,以 4:1 的比例分为训练集和测试集。
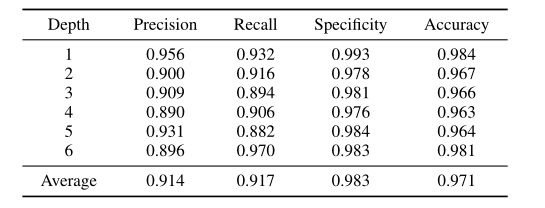
该深度模型在测试集中显示出较高的预测性能,平均精密度、召回率、特异性和正确率分别为 0.914、0.917、0.983 和 0.971。这些结果证明了 D-DFF 模型的有效性。
深度预测
虽然预测深度时选择了最可能的深度,但仍然可能存在一小部分不正确的预测。这些错误的预测可能在视频编码过程中累积到相当大的数量,并进一步导致 RD 成本增加。为了避免这种错误传播,采用了如下保守策略:

在编码过程中,当前的 CU 被迭代地分割,直到它的最佳深度。为节省编码时间,跳过大于最优深度的编码。
基于概率估计的帧内分区模式预测
在 CTU 编码中,迭代执行分割过程,直到每个 CU 的最优深度 Do。对于每一个小于 Do 的深度,CU 遍历 5 种可能的分区模式,包括四叉树 (QT) 分区、垂直二叉树 (BTV) 分区、水平二叉树 (BTH) 分区、垂直三叉树 (TTV) 分区和水平三叉树 (TTH) 分区。为了进一步跳过不必要的编码模式,需要预测所有分区模式的概率。
参考信息
记位于 (x, y, t) 处的 CU为 U(x, y, t),其大小在 VVC 中大于 4×4。设它的参考集为:
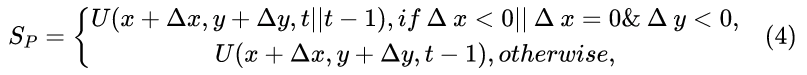
其中 ∆x 和 ∆y 的取值范围为 -1 至 1。该参考集与深度预测的参考集相似,但有两点不同:
- 在当前帧和左侧帧中收集顶部和左侧 CU 的分区。前人的研究表明,这些 CU 与当前 CU 具有较高的分区相关性。
- 降低了 ∆x 和 ∆y 的取值范围。没有卷积操作时,一个小而有效的参考集更实用。
概率估计
令 R 表示 CU 参考集 Sp 中所有最佳分区模式的集合。一个分区模式 M,其被选为最佳分区模式的概率可估计为:
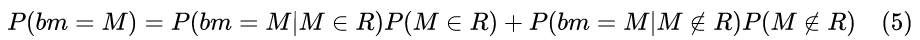


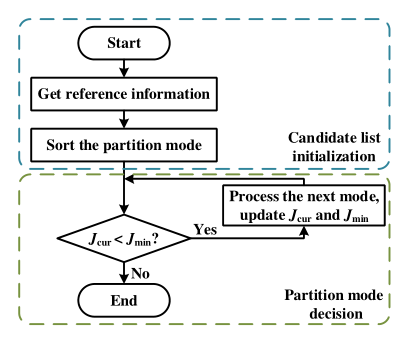
P-PBE 方法
在得到每个划分模式的概率后,对属于 R 的划分模式根据其概率进行降序排序,并将其他不在 R 中的划分模式加在最后。当当前分区模式的 RD 成本大于迄今为止获得的最小 RD 成本时,跳过未测试的分区,以节省总编码时间。
实验
实验配置
本文在 JVET 通用测试条件 (CTC) 下的 VTM-12.0 平台上使用 ALL-INTRA 配置实现了该算法。CTC 提供 6 组视频序列,分别是 A1 (3840×2160)、A2 (3840×2160)、B (1920×1080)、C (832×480)、D (416×240) 和 E (1280×720)。这些序列具有不同的空间信息 (SI) 和时间信息 (TI) 值。
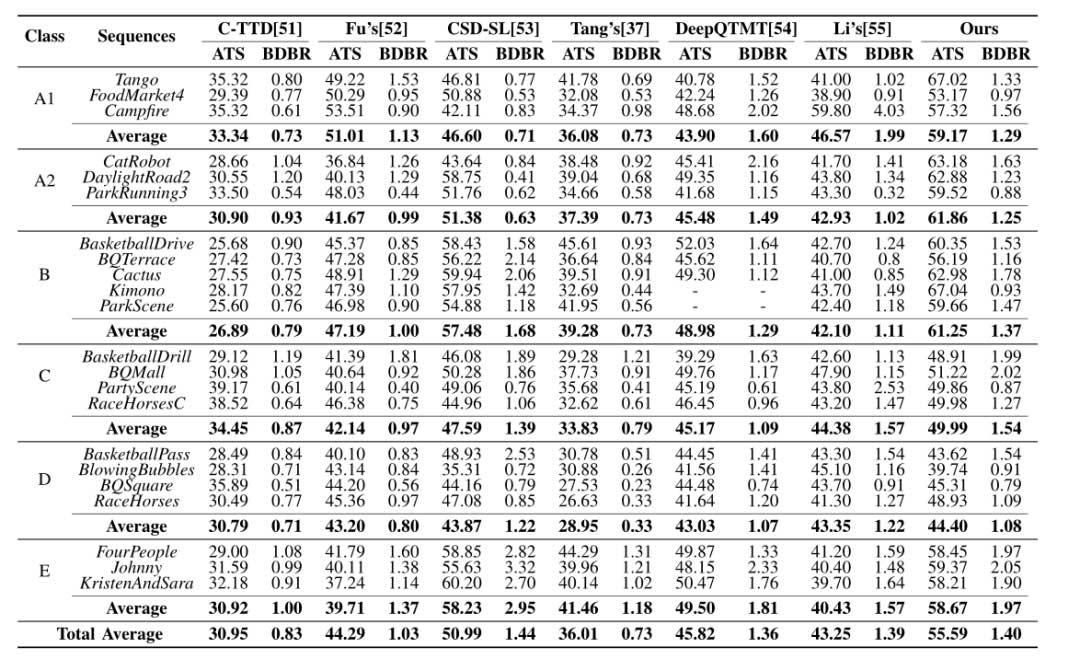
本文将所提出的算法与 C-TTD、Fu、CSD-SL、Tang、DeepQTMT 和Li 等最先进的算法进行了比较。评价标准包括四种 QPs(22、27、32 和 37)下的 BDBR(%) 和平均节省时间 (ATS)(%)。
实验结果
所有方法都增加了可以忽略不计的 BDBR 值,这证明了它们在降低计算复杂性的同时保持压缩视觉质量方面的高效率。相比之下,C-TTD、Fu、CSD-SL、Tang、DeepQTMT 和 Li 算法的平均 ATS 值分别为 30.95%、44.29%、50.99%、36.01%、45.82% 和 43.25%,RD 损失较小。与它们相比,本文的方案具有更好的计算复杂度降低,平均 ATS 为 55.59%。
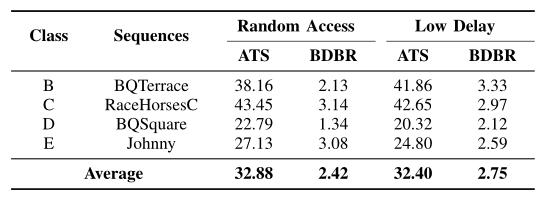
展望
将该框架应用于帧间预测时,可以用最接近的预测帧来预测当前帧的深度图。通过对该模型进行简单的迁移,结果显示,在没有明显 RD 损失的情况下,随机存取和低延迟的平均时间分别减少了 32.88% 和 32.40%。考虑到帧内和帧间预测的不同分区分布,还可以进一步完善该模型以提高 RD 性能。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。