
近年来,视觉语言模型 (VLM) 在连接图像、视频和文本模态方面取得了显著进展。然而,一个持续存在的限制依然存在:无法有效处理长上下文多模态数据,例如高分辨率图像或扩展视频序列。许多现有的 VLM 针对短上下文场景进行了优化,但在扩展以处理更长的输入时,会面临性能下降、内存使用效率低下或语义细节丢失等问题。克服这些限制不仅需要架构灵活性,还需要专门的数据采样、训练和评估策略。
Eagle 2.5:长上下文学习的通用框架
NVIDIA 推出 Eagle 2.5,这是一系列专为长上下文多模态学习而设计的视觉语言模型。与那些仅仅容纳更多输入标记的模型不同,Eagle 2.5 随着输入长度的增加,展现出可衡量且持续的性能提升。该系统的开发重点是大规模视频和图像理解,尤其针对那些对长篇内容丰富性至关重要的任务。
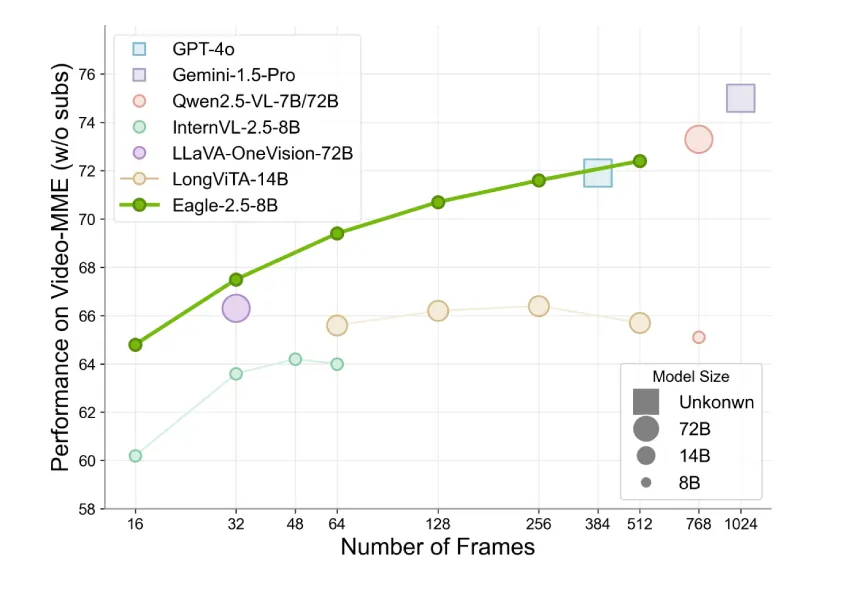
Eagle 2.5 采用相对紧凑的 8B 参数量,但在现有基准测试中取得了优异的成绩。在 Video-MME(512 帧输入)上,该模型的得分为 72.4%,接近或匹配 Qwen2.5-VL-72B 和 InternVL2.5-78B 等规模更大模型的结果。值得注意的是,这些提升无需依赖特定任务的压缩模块即可实现,这体现了该模型的通用设计理念。

培训策略:情境感知优化
Eagle 2.5 的有效性源于两个互补的训练策略:信息优先采样和渐进式后训练。
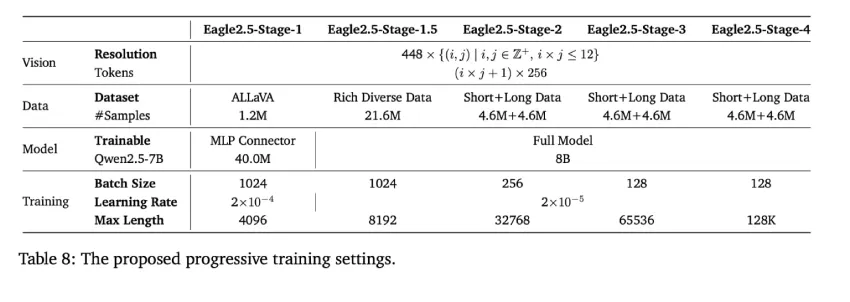
- 信息优先采样:优先保留关键的视觉和语义内容。它引入了图像区域保留 (IAP)机制,这是一种平铺方案,可保留超过 60% 的原始图像区域,同时最大限度地减少宽高比失真。此外,自动降级采样 (ADS) 机制可根据上下文长度限制动态平衡视觉和文本输入,从而保留完整的文本序列并自适应地优化视觉粒度。
- 渐进式后训练:逐步增加模型的上下文窗口——逐步增加 32K、64K 和 128K 个 token 的规模。这种逐步的训练使模型能够在不同的输入长度下发展出一致的能力。该方法可以避免对任何单一上下文范围的过拟合,并有助于在各种推理场景中保持稳定的性能。
这些方法基于 SigLIP 架构进行视觉编码,并利用 MLP 投影层与语言模型主干进行对齐。该系统放弃了特定领域的压缩组件,以保持跨不同任务类型的灵活性。
Eagle-Video-110K:用于扩展视频理解的结构化数据
Eagle 2.5 的一个关键组件是其训练数据流水线,它集成了开源资源和自定义数据集:Eagle-Video-110K。该数据集旨在支持长视频理解,并采用双重标注方案:
- 自上而下的方法使用人工注释的章节元数据和 GPT-4 生成的密集字幕和问答对引入故事级分割。
- 自下而上的方法使用 GPT-4o 为短片段生成 QA 对,并增强时间和文本上下文锚点以捕捉时空细节。
该数据集注重多样性而非冗余性。基于余弦相似度的筛选过程会从 InternVid、Shot2Story 和 VidChapters 等来源中筛选出新颖的内容。这最终形成了一个兼具叙事连贯性和精细注释的语料库,使模型能够捕捉跨时间的层级信息。
性能和基准测试
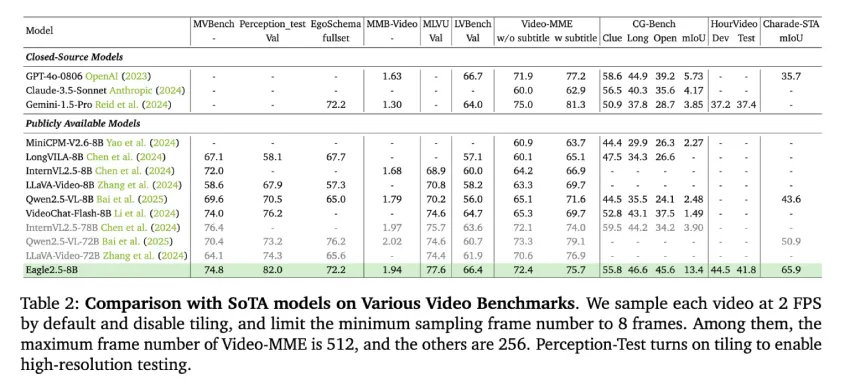
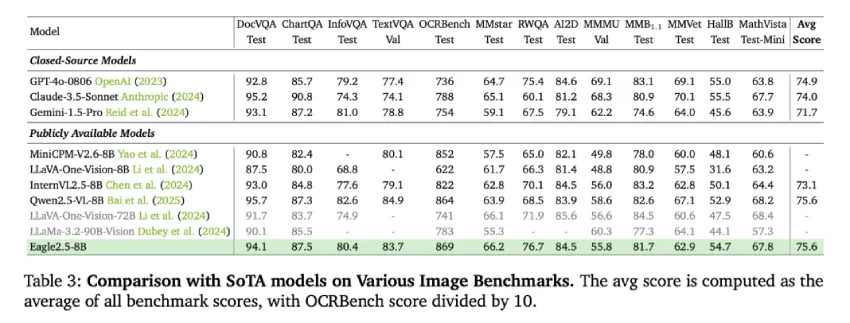
Eagle 2.5-8B 在多个视频和图像理解任务中展现出强大的性能。在视频基准测试中,该模型在 MVBench 上得分 74.8,在 MLVU 上得分 77.6,在 LongVideoBench 上得分 66.4。在图像基准测试中,该模型在 DocVQA 上得分 94.1,在 ChartQA 上得分 87.5,在 InfoVQA 上得分 80.4 等。
消融研究证实了 Eagle 采样策略的重要性。移除 IAP 会导致高分辨率基准测试中的性能下降,而省略 ADS 则会降低需要密集监督的任务的有效性。该模型还受益于渐进式训练:与一次性长上下文训练相比,连续增加上下文长度可以获得更稳定的增益。重要的是,添加 Eagle-Video-110K 显著提升了更高帧数(≥128 帧)下的性能,凸显了专用长格式数据集的价值。
结论
Eagle 2.5 提出了一种基于技术的长上下文视觉语言建模方法。它注重保持上下文完整性、逐步训练自适应和数据集多样性,使其能够在保持架构通用性的同时实现强大的性能。Eagle 2.5 无需依赖模型扩展,就证明了精心的训练策略和数据设计能够为复杂的多模态理解任务构建出具有竞争力且高效的系统。这使得 Eagle 2.5 成为构建更适用于现实世界多媒体应用的上下文感知型 AI 系统的重要一步。
资料
- 论文地址:https://arxiv.org/abs/2504.15271
- GitHub:https://github.com/NVlabs/EAGLE
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/57630.html