
语音AI正在成为多模态AI领域最重要的前沿领域之一。从智能助手到交互式代理,理解和推理音频的能力正在重塑机器与人类互动的方式。然而,尽管模型的能力迅速提升,但评估模型的工具却未能跟上步伐。现有的基准测试仍然碎片化、缓慢且侧重点狭窄,这往往使得比较模型或在真实的多轮测试环境中进行测试变得困难。
为了弥补这一差距,德克萨斯大学奥斯汀分校和 ServiceNow 研究团队发布了AU-Harness,这是一款全新的开源工具包,旨在大规模评估大型音频语言模型 (LALM)。AU-Harness 旨在实现快速、标准化和可扩展性,使研究人员能够在统一的框架内测试各种任务的模型,从语音识别到复杂的音频推理。
为什么需要一个新的音频评估框架?
当前的音频基准测试主要集中在语音转文本或情感识别等应用上。AudioBench 、VoiceBench和DynamicSUPERB-2.0等框架扩大了覆盖范围,但也留下了一些非常关键的缺陷。
有三个问题尤为突出。首先是吞吐量瓶颈:许多工具包没有利用批处理或并行性,导致大规模评估极其缓慢。其次是引发不一致性,导致不同模型的结果难以比较。第三是任务范围受限:在许多情况下,诸如二值化(谁在何时说话)和语音推理(遵循音频中的指令)等关键领域都缺失了。
这些差距限制了 LALM 的进步,特别是当它们演变为必须处理长时间、上下文密集和多回合交互的多模式代理时。
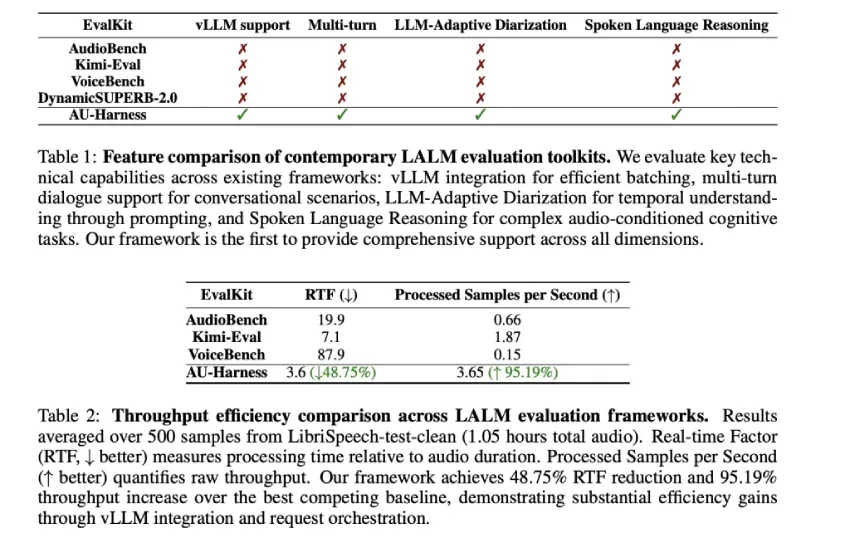

AU-Harness 如何提高效率?
研究团队在设计 AU-Harness 时注重速度。通过与vLLM 推理引擎集成,它引入了一个基于令牌的请求调度程序,用于管理跨多个节点的并发计算。它还对数据集进行分片,以便工作负载按比例分配到各个计算资源。
这种设计允许近乎线性地扩展评估,并保持硬件的充分利用。实际上,与现有套件相比,AU-Harness 的吞吐量提高了 127%,实时因子 (RTF) 降低了近 60%。对于研究人员而言,这意味着曾经需要数天才能完成的评估现在只需数小时即可完成。
评估可以定制吗?
灵活性是 AU-Harness 的另一个核心特性。评估运行中的每个模型都可以拥有自己的超参数,例如温度或最大标记设置,而不会破坏标准化。配置允许对数据集进行过滤(例如,按口音、音频长度或噪声配置文件),从而实现有针对性的诊断。
或许最重要的是,AU-Harness 支持多轮对话评估。早期的工具包仅限于单轮任务,但现代语音代理可以处理扩展对话。借助 AU-Harness,研究人员可以对多步骤对话中的对话连续性、语境推理和适应性进行基准测试。
AU-Harness 涵盖哪些任务?
AU-Harness 极大地扩展了任务覆盖范围,支持6 个类别中的50 多个数据集、380 多个子集和 21 个任务:
- 语音识别:从简单的 ASR 到长篇和代码转换语音。
- 副语言学:情感、口音、性别和说话人识别。
- 音频理解:场景和音乐理解。
- 口语理解:问答、翻译和对话总结。
- 口语推理:语音到编码、函数调用和多步骤指令遵循。
- 安全与保障:稳健性评估和欺骗检测。
有两项创新引人注目:
- LLM-自适应二值化,通过提示而不是专门的神经模型来评估二值化。
- 口语推理,测试模型处理和推理口头指令的能力,而不仅仅是转录它们。

基准测试揭示了当今模型的哪些方面?
当应用于GPT-4o、Qwen2.5-Omni和Voxtral-Mini-3B等领先系统时,AU-Harness 既突出了优势,也突出了劣势。
模型在自动语音识别 (ASR) 和问答方面表现出色,在语音识别和口语问答任务中表现出色。但它们在时间推理任务(例如二值化)和复杂的指令执行(尤其是当指令以音频形式给出时)方面表现较差。
一项关键发现是教学模态的差距:当相同的任务以口头指令而非文本呈现时,绩效会下降多达9.5 分。这表明,虽然模型擅长处理基于文本的推理,但将这些技能应用于音频模态仍然是一个悬而未决的挑战。
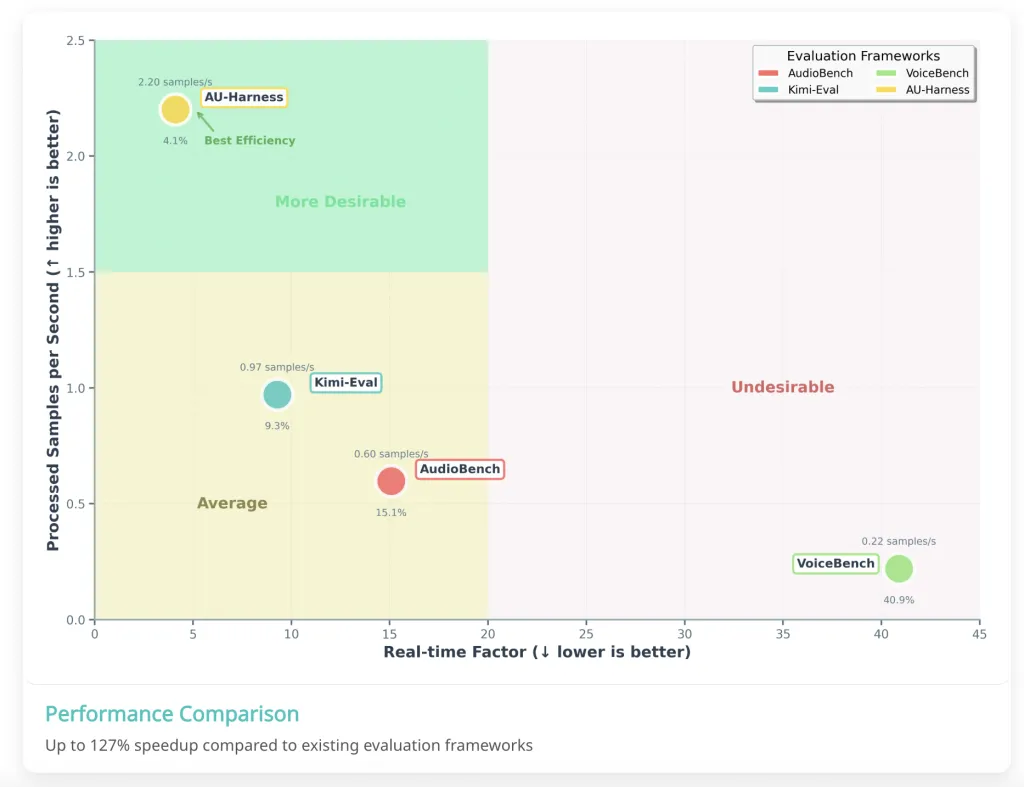
概括
AU-Harness 标志着音频语言模型评估朝着标准化和可扩展性迈出了重要一步。通过结合效率、可重复性和广泛的任务覆盖范围(包括二值化和口语推理),它解决了语音 AI 基准测试中长期存在的差距。它的开源版本和公开排行榜邀请社区合作、比较,并突破语音优先 AI 系统所能实现的极限。
参考资料:
https://arxiv.org/abs/2509.08031
https://au-harness.github.io/
https://github.com/ServiceNow/AU-Harness
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/61561.html