
什么是 ProRLv2?
ProRLv2是 NVIDIA 延长强化学习 (ProRL) 的最新版本,专为突破大语言模型 (LLM) 的推理能力而设计。通过将强化学习 (RL) 步数从 2,000 扩展到 3,000,ProRLv2 系统地测试了扩展强化学习如何解锁新的解决方案空间、创造力和高级推理能力,这些能力此前即使在像拥有 1.5B 参数的 Nemotron-Research-Reasoning-Qwen-1.5B-v2 这样的小型模型中也难以企及。


ProRLv2 的关键创新
ProRLv2 采用了多项创新来克服 LLM 培训中常见的 RL 限制:
- REINFORCE++-Baseline:一种强大的 RL 算法,能够进行数千步的长期优化,处理 LLM 中 RL 中典型的不稳定性。
- KL 散度正则化和参考策略重置:定期使用当前最佳检查点刷新参考模型,通过防止 RL 目标过早占主导地位,实现稳定进展和持续探索。
- 解耦剪辑和动态采样(DAPO):通过提升不太可能的标记并将学习信号集中在中等难度的提示上来鼓励发现多样化的解决方案。
- 预定长度惩罚:循环应用,有助于保持多样性并防止随着训练时间延长而导致熵崩溃。
- 扩展训练步骤:ProRLv2 将 RL 训练范围从 2,000 步扩展到 3,000 步,直接测试 RL 可以将推理能力扩展多长时间。
ProRLv2 如何扩展 LLM 推理
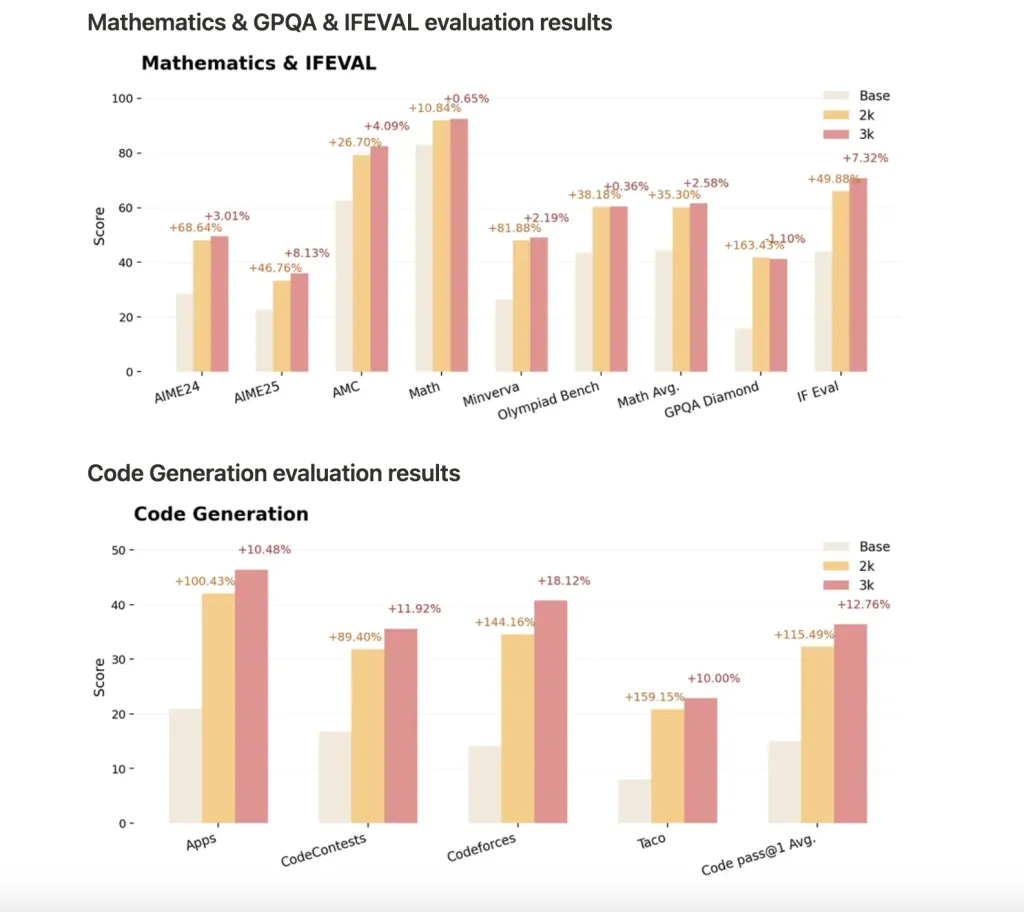
Nemotron-Research-Reasoning-Qwen-1.5B-v2 使用 ProRLv2 进行了 3,000 个 RL 步骤的训练,为推理任务(包括数学、代码、科学和逻辑谜题)的开放权重 1.5B 模型树立了新标准:
- 性能超越了之前的版本和 DeepSeek-R1-1.5B 等竞争对手。
- 通过更多的 RL 步骤获得持续的收益:更长的训练时间会带来持续的改进,特别是在基础模型表现不佳的任务上,这表明推理边界得到了真正的扩展。
- 泛化:ProRLv2 不仅提高了 pass@1 的准确性,而且还能够在训练期间未见过的任务上实现新颖的推理和解决策略。
- 基准:收益包括数学平均通过率@1 提高 14.7%、编码提高 13.9%、逻辑谜题提高 54.8%、STEM 推理提高 25.1% 以及指令遵循任务提高 18.1%,并且在 v2 中对未见过且更难的基准测试有进一步的改进。
ProRLv2 重要性
ProRLv2 的主要发现是,持续的 RL 训练,加上细致的探索和正则化,能够可靠地扩展 LLM 的学习和泛化能力。持续的 RL 训练不会在早期陷入瓶颈或出现过拟合,而是能够让较小的模型在推理能力上与更大的模型相媲美——这表明 RL 本身的扩展与模型或数据集的大小同样重要。
使用 Nemotron-Research-Reasoning-Qwen-1.5B-v2
最新的检查点已在 Hugging Face 上可供测试。正在加载模型:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("nvidia/Nemotron-Research-Reasoning-Qwen-1.5B")
model = AutoModelForCausalLM.from_pretrained("nvidia/Nemotron-Research-Reasoning-Qwen-1.5B")结论
ProRLv2 重新定义了语言模型推理的极限,它表明强化学习的缩放定律与模型规模或数据同等重要。通过高级正则化和智能训练计划,即使在紧凑的架构中,它也能实现深度、创造性和可泛化的推理。未来取决于强化学习的发展方向,而不仅仅是模型规模的扩大。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/60550.html