
近年来,诸如 CLIP 之类的对比语言-图像模型已成为学习视觉表征的默认选择,尤其是在视觉问答 (VQA) 和文档理解等多模态应用中。这些模型利用大规模图像-文本对,通过语言监督来整合语义基础。然而,这种对文本的依赖带来了概念和实践方面的挑战:语言对于多模态性能至关重要的假设、获取对齐数据集的复杂性以及数据可用性带来的可扩展性限制。相比之下,无需语言的视觉自监督学习 (SSL) 在分类和分割任务上历来表现出色,但由于性能差距,尤其是在 OCR 和基于图表的任务中,在多模态推理中尚未得到充分利用。
Meta 在 Hugging Face 上发布 WebSSL 模型(3 亿 – 70 亿参数)
为了探索大规模无语言视觉学习的能力,Meta 发布了Web-SSL 系列 DINO 和 Vision Transformer (ViT) 模型,其参数数量从 3 亿到 70 亿不等,现已通过 Hugging Face 公开发布。这些模型专门在MetaCLIP 数据集 (MC-2B)的图像子集上进行训练——这是一个包含 20 亿张图像的网络规模数据集。这种受控设置可以直接比较 WebSSL 和 CLIP,它们都基于相同的数据进行训练,从而隔离语言监督的影响。
我们的目标并非取代 CLIP,而是严格评估当模型和数据规模不再成为限制因素时,纯视觉自监督能够走多远。此次发布代表着我们朝着理解语言监督对于训练高容量视觉编码器的必要性(或仅仅是有益的)迈出了重要一步。

技术架构与训练方法
WebSSL 包含两种可视化 SSL 范式:联合嵌入学习(通过 DINOv2)和掩码建模(通过 MAE)。每个模型都遵循使用 224×224 分辨率图像的标准化训练协议,并在下游评估期间维护冻结视觉编码器,以确保观察到的差异完全归因于预训练。
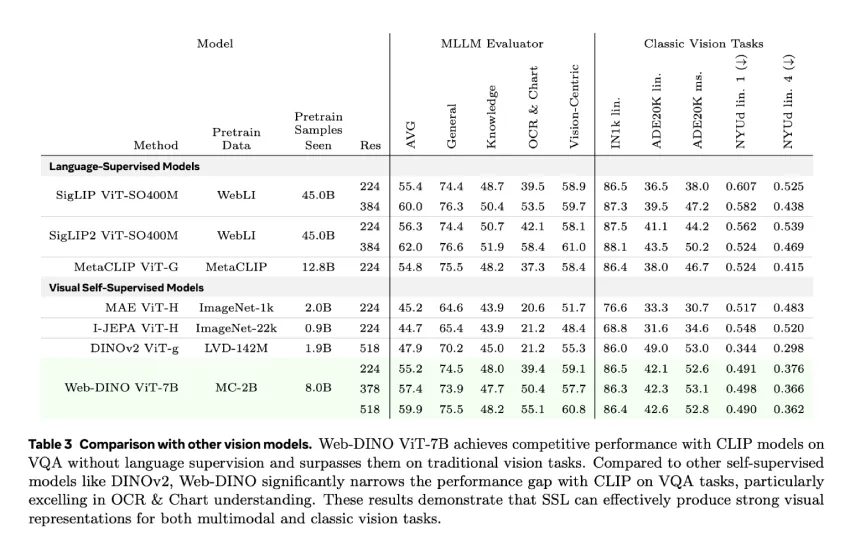
模型在五个容量层级(ViT-1B 至 ViT-7B)上进行训练,仅使用来自 MC-2B 的未标记图像数据。评估使用Cambrian-1进行,这是一个全面的 16 任务 VQA 基准套件,涵盖通用视觉理解、基于知识的推理、OCR 和基于图表的解释。
此外,Hugging Facetransformers库原生支持这些模型,提供可访问的检查点并无缝集成到研究工作流程中。
性能洞察和扩展行为
实验结果揭示了几个关键发现:
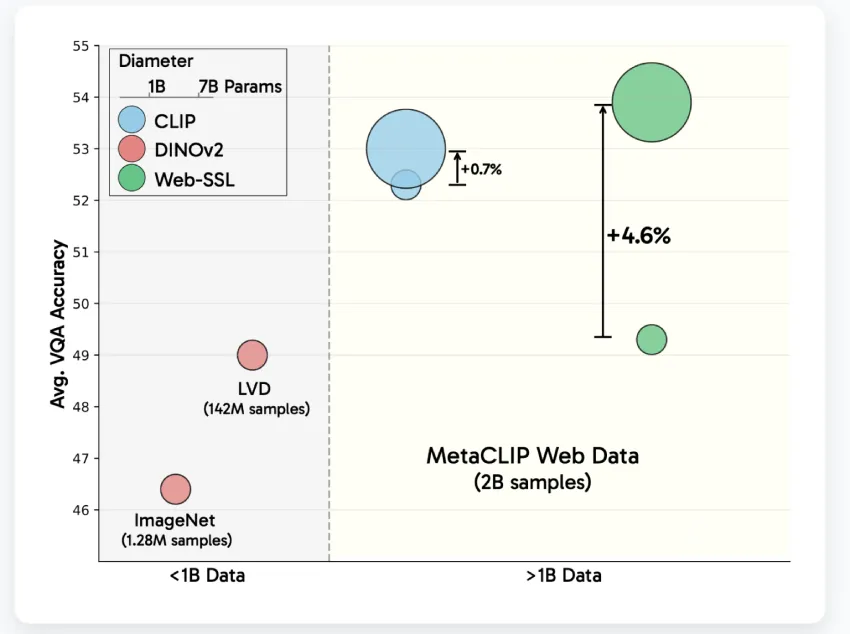
- 扩展模型规模:随着参数数量的增加,WebSSL 模型的 VQA 性能呈现出近乎对数线性的提升。相比之下,CLIP 的性能在超过 30 亿个参数后便趋于稳定。WebSSL 在所有 VQA 类别中都保持了极具竞争力的结果,并在更大规模的视觉中心任务以及 OCR 和图表任务中展现出显著的提升。
- 数据组成至关重要:通过过滤训练数据,使其仅包含 1.3% 的富文本图像,WebSSL 在 OCR 和图表任务上的表现优于 CLIP——在 OCRBench 和 ChartQA 中实现了高达 +13.6% 的提升。这表明,仅凭视觉文本(而非语言标签)的存在,就能显著提升特定任务的性能。
- 高分辨率训练:以 518px 分辨率进行微调的 WebSSL 模型进一步缩小了与 SigLIP 等高分辨率模型的性能差距,特别是对于文档密集型任务而言。
- LLM 对齐:在没有任何语言监督的情况下,随着模型规模和训练次数的增加,WebSSL 与预训练语言模型(例如 LLaMA-3)的对齐效果有所提升。这种新兴行为意味着更大的视觉模型会隐式地学习与文本语义高度相关的特征。
重要的是,WebSSL 在传统基准测试(ImageNet-1k 分类、ADE20K 分割、NYUv2 深度估计)上保持强劲的性能,并且在同等设置下通常优于 MetaCLIP 甚至 DINOv2。
结论性意见
Meta 的 Web-SSL 研究提供了强有力的证据,表明视觉自监督学习在适当扩展的情况下,是语言监督预训练的可行替代方案。这些发现挑战了语言监督对于多模态理解至关重要的普遍假设。相反,它们强调了数据集组成、模型规模以及在不同基准上进行仔细评估的重要性。
此次发布的模型参数范围涵盖 3 亿至 70 亿,这使得更广泛的研究和下游实验能够不受配对数据或专有流程的限制。作为未来多模态系统的开源基础,WebSSL 模型代表了可扩展、无语言限制的视觉学习领域的重大进步。
资料:
https://huggingface.co/collections/facebook/web-ssl-68094132c15fbd7808d1e9bb
https://github.com/facebookresearch/webssl
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/57711.html