
随着语言模型在参数数量和推理复杂度方面的不断增长,传统的集中式训练流程面临着越来越多的限制。高性能模型训练通常依赖于紧密耦合且具有快速互连的计算集群,这些集群成本高昂、可用性有限,并且容易出现可扩展性瓶颈。此外,集中式架构限制了广泛协作和实验的可能性,尤其是在开源研究环境中。转向去中心化方法可以缓解这些挑战,从而实现更广泛的参与和更容错的训练机制。
PrimeIntellect 开源 INTELLECT-2,一个 32B 推理模型
PrimeIntellect 发布了 INTELLECT-2,这是一个拥有 320 亿个参数的推理模型,采用广义强化策略优化 (GRPO) 在完全去中心化的异步强化学习框架内进行后训练。该版本采用 Apache 2.0 许可,不仅包含模型权重,还包含完整的代码库和训练日志。INTELLECT-2 在关键推理基准测试中超越了此前领先的 QwQ-32B 模型。该版本的开源特性旨在支持可重复性、可扩展性和持续研究。
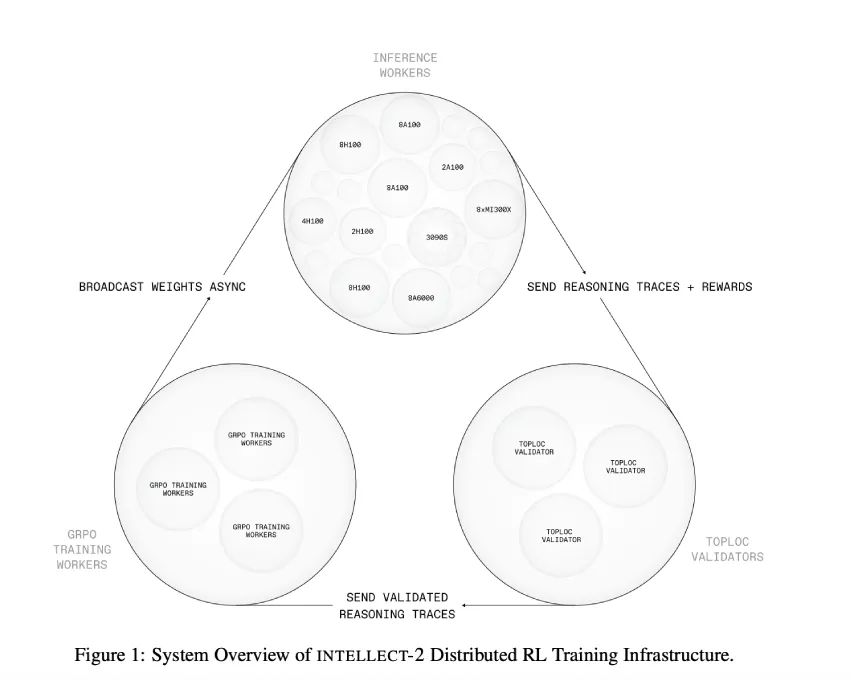

架构与技术创新
INTELLECT-2 是基于专为分布式环境构建的全新训练堆栈开发的。该系统由三个主要组件构成:
- PRIME-RL:一种异步 RL 引擎,它将 rollout 生成、训练和参数分发三个阶段分离。这种解耦消除了同步更新的需要,并允许系统在多变且不可靠的网络条件下运行。
- SHARDCAST:一种树形拓扑 HTTP 协议,支持在分布式工作者之间快速传播模型权重,从而无需专门的基础设施即可提高通信效率。
- TOPLOC:一种基于局部敏感哈希的验证机制,用于检测推理输出中的修改。这对于确保分布式和潜在的非确定性硬件环境中的完整性至关重要。
这种架构使得 INTELLECT-2 能够以最小的协调开销跨异构系统进行训练,同时保持模型质量和推理一致性。
训练数据、方法和性能
INTELLECT-2 的后训练过程使用了大约 285,000 个可验证任务,重点关注推理、编码和数学问题解决。数据来源包括 NuminaMath-1.5、Deepscaler 和 SYNTHETIC-1 等数据集。该模型使用 GRPO 进行异步更新的强化学习微调。
该系统采用了两阶段训练策略:在现有部署和训练流程保持活跃的同时,广播新的策略权重,从而最大限度地减少网络的空闲时间。通过对令牌概率比进行双边裁剪,降低了与大规模更新相关的方差,从而提高了稳定性。
我们结合启发式算法和自动筛选器来筛选高质量的演示,并采用定制的奖励模型对完成情况进行排序。强化学习循环始终优先选择推理结构更佳的完成情况,从而实现了相比基线模型可衡量的性能提升。
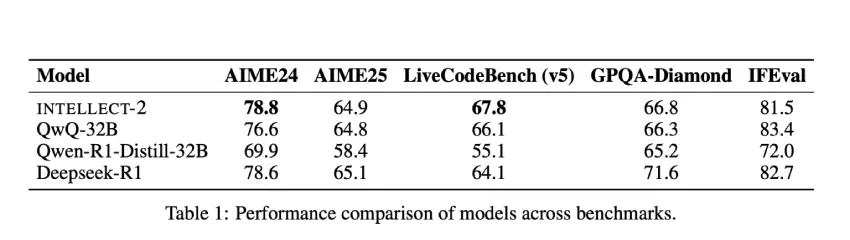
在评估方面,INTELLECT-2 在多个以推理为中心的基准测试中均优于 QwQ-32B,表明其泛化能力和推理准确性均有所提升。这些提升在数学和编码任务中尤为明显,在这些任务中,异步 GRPO 微调和精心策划的奖励模型的使用产生了更具结构化和可验证的输出。这些结果表明,去中心化的训练后流程可以实现与传统 RLHF 流程相当甚至更优的性能,同时提供更高的灵活性和可扩展性。
结论
INTELLECT-2 代表着迈向去中心化大规模模型训练的可靠方法。PrimeIntellect 证明了 32B 参数模型能够通过分布式异步强化学习进行高性能后训练,为集中式 RLHF 流程提供了一种实用且可扩展的替代方案。该架构的模块化组件 PRIME-RL、SHARDCAST 和 TOPLOC 解决了可扩展性、通信效率和推理验证方面的关键挑战。随着人们对开放式、去中心化 AI 开发的研究兴趣日益增长,INTELLECT-2 将成为分布式模型训练中可重复的基准测试和进一步实验的框架。
资料
- 论文地址:https://storage.googleapis.com/public-technical-paper/INTELLECT_2_Technical_Report.pdf
- 发布地址:https://www.primeintellect.ai/blog/intellect-2-release
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/58027.html